 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEA-BED: Southeast Asia Embedding Benchmark
Aug 17, 2025
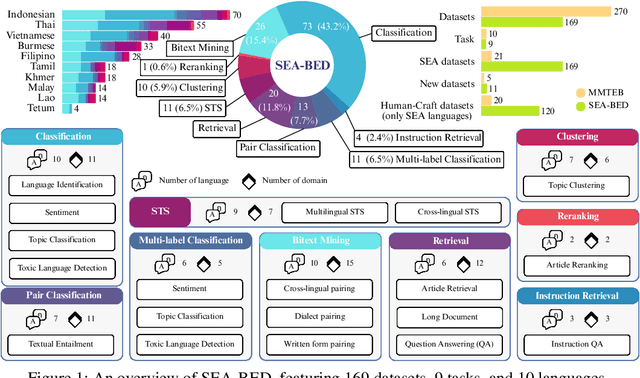


Sentence embeddings are essential for NLP tasks such as semantic search, re-ranking, and textual similarity. Although multilingual benchmarks like MMTEB broaden coverage, Southeast Asia (SEA) datasets are scarce and often machine-translated, missing native linguistic properties. With nearly 700 million speakers, the SEA region lacks a region-specific embedding benchmark. We introduce SEA-BED, the first large-scale SEA embedding benchmark with 169 datasets across 9 tasks and 10 languages, where 71% are formulated by humans, not machine generation or translation. We address three research questions: (1) which SEA languages and tasks are challenging, (2) whether SEA languages show unique performance gaps globally, and (3) how human vs. machine translations affect evaluation. We evaluate 17 embedding models across six studies, analyzing task and language challenges, cross-benchmark comparisons, and translation trade-offs. Results show sharp ranking shifts, inconsistent model performance among SEA languages, and the importance of human-curated datasets for low-resource languages like Burmese.
SEA-LION: Southeast Asian Languages in One Network
Apr 08, 2025Recently, Large Language Models (LLMs) have dominated much of the artificial intelligence scene with their ability to process and generate natural languages. However, the majority of LLM research and development remains English-centric, leaving low-resource languages such as those in the Southeast Asian (SEA) region under-represented. To address this representation gap, we introduce Llama-SEA-LION-v3-8B-IT and Gemma-SEA-LION-v3-9B-IT, two cutting-edge multilingual LLMs designed for SEA languages. The SEA-LION family of LLMs supports 11 SEA languages, namely English, Chinese, Indonesian, Vietnamese, Malay, Thai, Burmese, Lao, Filipino, Tamil, and Khmer. Our work leverages large-scale multilingual continued pre-training with a comprehensive post-training regime involving multiple stages of instruction fine-tuning, alignment, and model merging. Evaluation results on multilingual benchmarks indicate that our models achieve state-of-the-art performance across LLMs supporting SEA languages. We open-source the models to benefit the wider SEA community.
SEA-HELM: Southeast Asian Holistic Evaluation of Language Models
Feb 20, 2025



With the rapid emergence of novel capabilities in Large Language Models (LLMs), the need for rigorous multilingual and multicultural benchmarks that are integrated has become more pronounced. Though existing LLM benchmarks are capable of evaluating specific capabilities of LLMs in English as well as in various mid- to low-resource languages, including those in the Southeast Asian (SEA) region, a comprehensive and authentic evaluation suite for the SEA languages has not been developed thus far. Here, we present SEA-HELM, a holistic linguistic and cultural LLM evaluation suite that emphasizes SEA languages, comprising five core pillars: (1) NLP Classics, (2) LLM-specifics, (3) SEA Linguistics, (4) SEA Culture, (5) Safety. SEA-HELM currently supports Filipino, Indonesian, Tamil, Thai, and Vietnamese. We also introduce the SEA-HELM leaderboard, which allows users to understand models' multilingual and multicultural performance in a systematic and user-friendly manner.
Global MMLU: Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation
Dec 04, 2024



Cultural biases in multilingual datasets pose significant challenges for their effectiveness as global benchmarks. These biases stem not only from language but also from the cultural knowledge required to interpret questions, reducing the practical utility of translated datasets like MMLU. Furthermore, translation often introduces artifacts that can distort the meaning or clarity of questions in the target language. A common practice in multilingual evaluation is to rely on machine-translated evaluation sets, but simply translating a dataset is insufficient to address these challenges. In this work, we trace the impact of both of these issues on multilingual evaluations and ensuing model performances. Our large-scale evaluation of state-of-the-art open and proprietary models illustrates that progress on MMLU depends heavily on learning Western-centric concepts, with 28% of all questions requiring culturally sensitive knowledge. Moreover, for questions requiring geographic knowledge, an astounding 84.9% focus on either North American or European regions. Rankings of model evaluations change depending on whether they are evaluated on the full portion or the subset of questions annotated as culturally sensitive, showing the distortion to model rankings when blindly relying on translated MMLU. We release Global-MMLU, an improved MMLU with evaluation coverage across 42 languages -- with improved overall quality by engaging with compensated professional and community annotators to verify translation quality while also rigorously evaluating cultural biases present in the original dataset. This comprehensive Global-MMLU set also includes designated subsets labeled as culturally sensitive and culturally agnostic to allow for more holistic, complete evaluation.
BHASA: A Holistic Southeast Asian Linguistic and Cultural Evaluation Suite for Large Language Models
Sep 19, 2023



The rapid development of Large Language Models (LLMs) and the emergence of novel abilities with scale have necessitated the construction of holistic, diverse and challenging benchmarks such as HELM and BIG-bench. However, at the moment, most of these benchmarks focus only on performance in English and evaluations that include Southeast Asian (SEA) languages are few in number. We therefore propose BHASA, a holistic linguistic and cultural evaluation suite for LLMs in SEA languages. It comprises three components: (1) a NLP benchmark covering eight tasks across Natural Language Understanding (NLU), Generation (NLG) and Reasoning (NLR) tasks, (2) LINDSEA, a linguistic diagnostic toolkit that spans the gamut of linguistic phenomena including syntax, semantics and pragmatics, and (3) a cultural diagnostics dataset that probes for both cultural representation and sensitivity. For this preliminary effort, we implement the NLP benchmark only for Indonesian, Vietnamese, Thai and Tamil, and we only include Indonesian and Tamil for LINDSEA and the cultural diagnostics dataset. As GPT-4 is purportedly one of the best-performing multilingual LLMs at the moment, we use it as a yardstick to gauge the capabilities of LLMs in the context of SEA languages. Our initial experiments on GPT-4 with BHASA find it lacking in various aspects of linguistic capabilities, cultural representation and sensitivity in the targeted SEA languages. BHASA is a work in progress and will continue to be improved and expanded in the future. The repository for this paper can be found at: https://github.com/aisingapore/BHASA
MICE: A Crosslinguistic Emotion Corpus in Malay, Indonesian, Chinese and English
Jun 09, 2021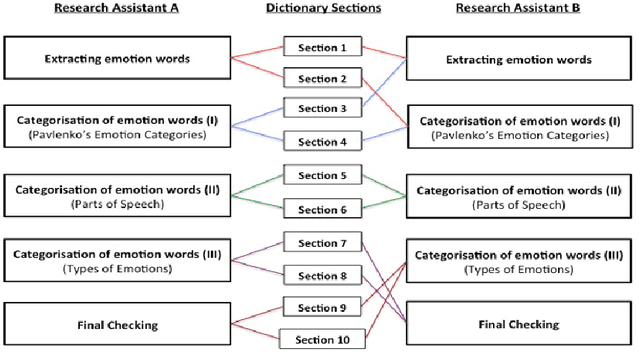

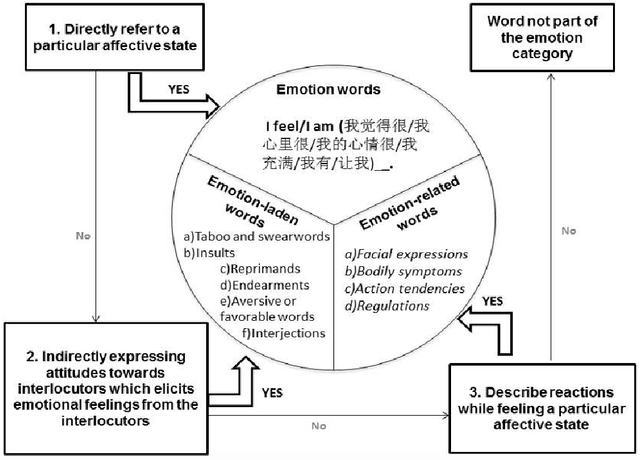
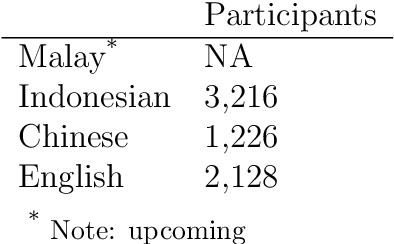
MICE is a corpus of emotion words in four languages which is currently working progress. There are two sections to this study, Part I: Emotion word corpus and Part II: Emotion word survey. In Part 1, the method of how the emotion data is culled for each of the four languages will be described and very preliminary data will be presented. In total, we identified 3,750 emotion expressions in Malay, 6,657 in Indonesian, 3,347 in Mandarin Chinese and 8,683 in English. We are currently evaluating and double checking the corpus and doing further analysis on the distribution of these emotion expressions. Part II Emotion word survey involved an online language survey which collected information on how speakers assigned the emotion words into basic emotion categories, the rating for valence and intensity as well as biographical information of all the respondents.