 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Phonemes to Meaning: Evaluating Large Language Models on Tamil
Nov 15, 2025Large Language Models (LLMs) have shown strong generalization across tasks in high-resource languages; however, their linguistic competence in low-resource and morphologically rich languages such as Tamil remains largely unexplored. Existing multilingual benchmarks often rely on translated English datasets, failing to capture the linguistic and cultural nuances of the target language. To address this gap, we introduce ILAKKANAM, the first Tamil-specific linguistic evaluation benchmark manually curated using 820 questions from Sri Lankan school-level Tamil subject examination papers. Each question is annotated by trained linguists under five linguistic categories and a factual knowledge category, spanning Grades 1--13 to ensure broad linguistic coverage. We evaluate both closed-source and open-source LLMs using a standardized evaluation framework. Our results show that Gemini 2.5 achieves the highest overall performance, while open-source models lag behind, highlighting the gap in linguistic grounding. Category- and grade-wise analyses reveal that all models perform well on lower-grade questions but show a clear decline as linguistic complexity increases. Further, no strong correlation is observed between a model's overall performance and its ability to identify linguistic categories, suggesting that performance may be driven by exposure rather than genuine understanding.
Building Tamil Treebanks
Sep 23, 2024Treebanks are important linguistic resources, which are structured and annotated corpora with rich linguistic annotations. These resources are used in Natural Language Processing (NLP) applications, supporting linguistic analyses, and are essential for training and evaluating various computational models. This paper discusses the creation of Tamil treebanks using three distinct approaches: manual annotation, computational grammars, and machine learning techniques. Manual annotation, though time-consuming and requiring linguistic expertise, ensures high-quality and rich syntactic and semantic information. Computational deep grammars, such as Lexical Functional Grammar (LFG), offer deep linguistic analyses but necessitate significant knowledge of the formalism. Machine learning approaches, utilising off-the-shelf frameworks and tools like Stanza, UDpipe, and UUParser, facilitate the automated annotation of large datasets but depend on the availability of quality annotated data, cross-linguistic training resources, and computational power. The paper discusses the challenges encountered in building Tamil treebanks, including issues with Internet data, the need for comprehensive linguistic analysis, and the difficulty of finding skilled annotators. Despite these challenges, the development of Tamil treebanks is essential for advancing linguistic research and improving NLP tools for Tamil.
* 10 pages
Egalitarian Language Representation in Language Models: It All Begins with Tokenizers
Sep 17, 2024Tokenizers act as a bridge between human language and the latent space of language models, influencing how language is represented in these models. Due to the immense popularity of English-Centric Large Language Models (LLMs), efforts are being made to adapt them for other languages. However, we demonstrate that, from a tokenization standpoint, not all tokenizers offer fair representation for complex script languages such as Tamil, Sinhala, and Hindi, primarily due to the choice of pre-tokenization methods. We go further to show that pre-tokenization plays a more critical role than the tokenization algorithm itself in achieving an egalitarian representation of these complex script languages. To address this, we introduce an improvement to the Byte Pair Encoding (BPE) algorithm by incorporating graphemes, which we term Grapheme Pair Encoding (GPE). Our experiments show that grapheme-based character extraction outperforms byte-level tokenizers for complex scripts. We validate this approach through experiments on Tamil, Sinhala, and Hindi.
Tamil Language Computing: the Present and the Future
Jul 11, 2024This paper delves into the text processing aspects of Language Computing, which enables computers to understand, interpret, and generate human language. Focusing on tasks such as speech recognition, machine translation, sentiment analysis, text summarization, and language modelling, language computing integrates disciplines including linguistics, computer science, and cognitive psychology to create meaningful human-computer interactions. Recent advancements in deep learning have made computers more accessible and capable of independent learning and adaptation. In examining the landscape of language computing, the paper emphasises foundational work like encoding, where Tamil transitioned from ASCII to Unicode, enhancing digital communication. It discusses the development of computational resources, including raw data, dictionaries, glossaries, annotated data, and computational grammars, necessary for effective language processing. The challenges of linguistic annotation, the creation of treebanks, and the training of large language models are also covered, emphasising the need for high-quality, annotated data and advanced language models. The paper underscores the importance of building practical applications for languages like Tamil to address everyday communication needs, highlighting gaps in current technology. It calls for increased research collaboration, digitization of historical texts, and fostering digital usage to ensure the comprehensive development of Tamil language processing, ultimately enhancing global communication and access to digital services.
Morphology and Syntax of the Tamil Language
Jan 16, 2024This paper provides an overview of the morphology and syntax of the Tamil language, focusing on its contemporary usage. The paper also highlights the complexity and richness of Tamil in terms of its morphological and syntactic features, which will be useful for linguists analysing the language and conducting comparative studies. In addition, the paper will be useful for those developing computational resources for the Tamil language. It is proven as a rule-based morphological analyser cum generator and a computational grammar for Tamil have already been developed based on this paper. To enhance accessibility for a broader audience, the analysis is conducted without relying on any specific grammatical formalism.
BHASA: A Holistic Southeast Asian Linguistic and Cultural Evaluation Suite for Large Language Models
Sep 19, 2023



The rapid development of Large Language Models (LLMs) and the emergence of novel abilities with scale have necessitated the construction of holistic, diverse and challenging benchmarks such as HELM and BIG-bench. However, at the moment, most of these benchmarks focus only on performance in English and evaluations that include Southeast Asian (SEA) languages are few in number. We therefore propose BHASA, a holistic linguistic and cultural evaluation suite for LLMs in SEA languages. It comprises three components: (1) a NLP benchmark covering eight tasks across Natural Language Understanding (NLU), Generation (NLG) and Reasoning (NLR) tasks, (2) LINDSEA, a linguistic diagnostic toolkit that spans the gamut of linguistic phenomena including syntax, semantics and pragmatics, and (3) a cultural diagnostics dataset that probes for both cultural representation and sensitivity. For this preliminary effort, we implement the NLP benchmark only for Indonesian, Vietnamese, Thai and Tamil, and we only include Indonesian and Tamil for LINDSEA and the cultural diagnostics dataset. As GPT-4 is purportedly one of the best-performing multilingual LLMs at the moment, we use it as a yardstick to gauge the capabilities of LLMs in the context of SEA languages. Our initial experiments on GPT-4 with BHASA find it lacking in various aspects of linguistic capabilities, cultural representation and sensitivity in the targeted SEA languages. BHASA is a work in progress and will continue to be improved and expanded in the future. The repository for this paper can be found at: https://github.com/aisingapore/BHASA
ThamizhiUDp: A Dependency Parser for Tamil
Dec 24, 2020

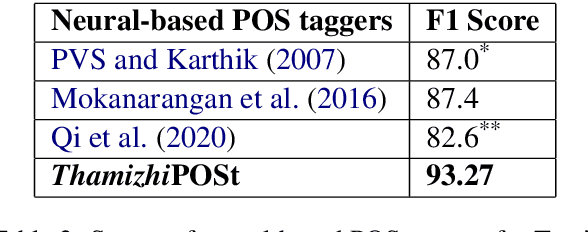
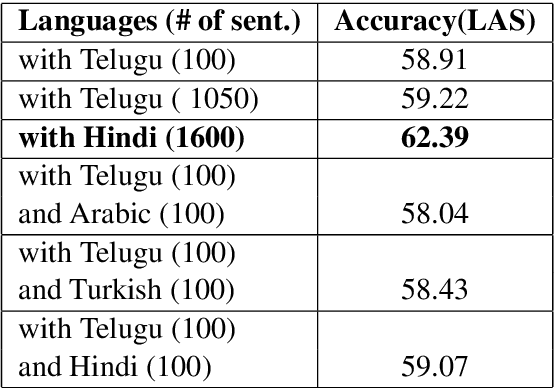
This paper describes how we developed a neural-based dependency parser, namely ThamizhiUDp, which provides a complete pipeline for the dependency parsing of the Tamil language text using Universal Dependency formalism. We have considered the phases of the dependency parsing pipeline and identified tools and resources in each of these phases to improve the accuracy and to tackle data scarcity. ThamizhiUDp uses Stanza for tokenisation and lemmatisation, ThamizhiPOSt and ThamizhiMorph for generating Part of Speech (POS) and Morphological annotations, and uuparser with multilingual training for dependency parsing. ThamizhiPOSt is our POS tagger, which is based on the Stanza, trained with Amrita POS-tagged corpus. It is the current state-of-the-art in Tamil POS tagging with an F1 score of 93.27. Our morphological analyzer, ThamizhiMorph is a rule-based system with a very good coverage of Tamil. Our dependency parser ThamizhiUDp was trained using multilingual data. It shows a Labelled Assigned Score (LAS) of 62.39, 4 points higher than the current best achieved for Tamil dependency parsing. Therefore, we show that breaking up the dependency parsing pipeline to accommodate existing tools and resources is a viable approach for low-resource languages.