 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThamizhiUDp: A Dependency Parser for Tamil
Paper and Code
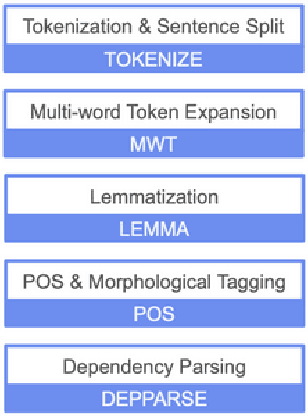

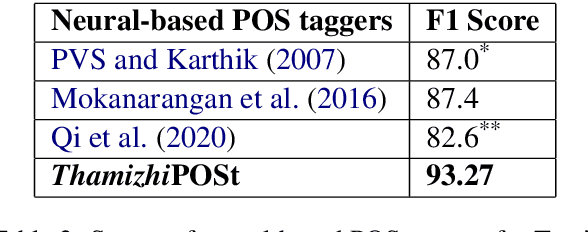
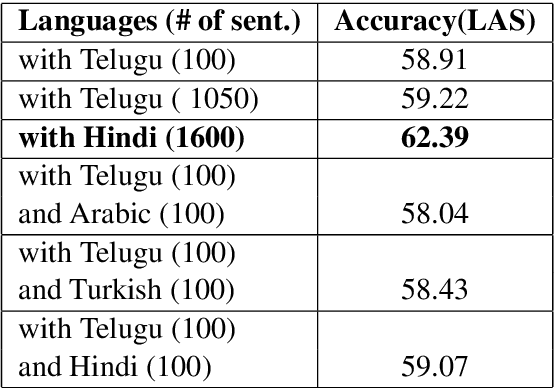
This paper describes how we developed a neural-based dependency parser, namely ThamizhiUDp, which provides a complete pipeline for the dependency parsing of the Tamil language text using Universal Dependency formalism. We have considered the phases of the dependency parsing pipeline and identified tools and resources in each of these phases to improve the accuracy and to tackle data scarcity. ThamizhiUDp uses Stanza for tokenisation and lemmatisation, ThamizhiPOSt and ThamizhiMorph for generating Part of Speech (POS) and Morphological annotations, and uuparser with multilingual training for dependency parsing. ThamizhiPOSt is our POS tagger, which is based on the Stanza, trained with Amrita POS-tagged corpus. It is the current state-of-the-art in Tamil POS tagging with an F1 score of 93.27. Our morphological analyzer, ThamizhiMorph is a rule-based system with a very good coverage of Tamil. Our dependency parser ThamizhiUDp was trained using multilingual data. It shows a Labelled Assigned Score (LAS) of 62.39, 4 points higher than the current best achieved for Tamil dependency parsing. Therefore, we show that breaking up the dependency parsing pipeline to accommodate existing tools and resources is a viable approach for low-resource languages.