 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance of Recent Large Language Models for a Low-Resourced Language
Jul 31, 2024Large Language Models (LLMs) have shown significant advances in the past year. In addition to new versions of GPT and Llama, several other LLMs have been introduced recently. Some of these are open models available for download and modification. Although multilingual large language models have been available for some time, their performance on low-resourced languages such as Sinhala has been poor. We evaluated four recent LLMs on their performance directly in the Sinhala language, and by translation to and from English. We also evaluated their fine-tunability with a small amount of fine-tuning data. Claude and GPT 4o perform well out-of-the-box and do significantly better than previous versions. Llama and Mistral perform poorly but show some promise of improvement with fine tuning.
SinSpell: A Comprehensive Spelling Checker for Sinhala
Jul 07, 2021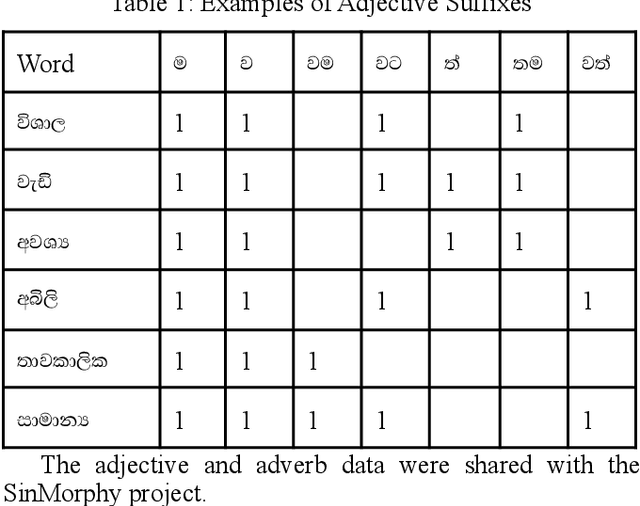


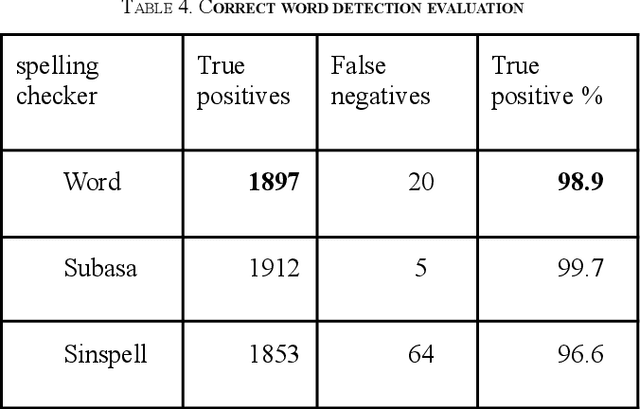
We have built SinSpell, a comprehensive spelling checker for the Sinhala language which is spoken by over 16 million people, mainly in Sri Lanka. However, until recently, Sinhala had no spelling checker with acceptable coverage. Sinspell is still the only open source Sinhala spelling checker. SinSpell identifies possible spelling errors and suggests corrections. It also contains a module which auto-corrects evident errors. To maintain accuracy, SinSpell was designed as a rule-based system based on Hunspell. A set of words was compiled from several sources and verified. These were divided into morphological classes, and the valid roots, suffixes and prefixes for each class were identified, together with lists of irregular words and exceptions. The errors in a corpus of Sinhala documents were analysed and commonly misspelled words and types of common errors were identified. We found that the most common errors were in vowel length and similar sounding letters. Errors due to incorrect typing and encoding were also found. This analysis was used to develop the suggestion generator and auto-corrector.
ThamizhiUDp: A Dependency Parser for Tamil
Dec 24, 2020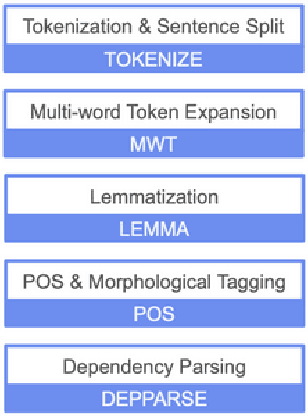

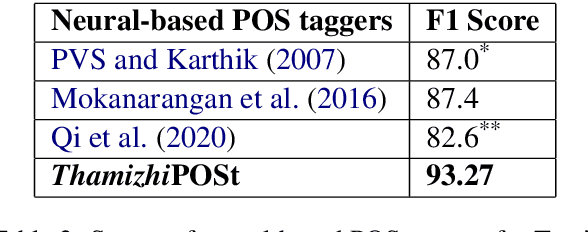
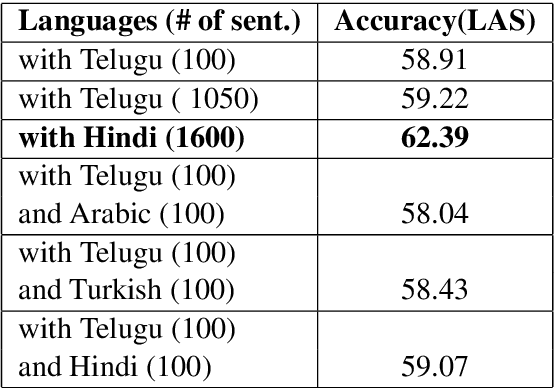
This paper describes how we developed a neural-based dependency parser, namely ThamizhiUDp, which provides a complete pipeline for the dependency parsing of the Tamil language text using Universal Dependency formalism. We have considered the phases of the dependency parsing pipeline and identified tools and resources in each of these phases to improve the accuracy and to tackle data scarcity. ThamizhiUDp uses Stanza for tokenisation and lemmatisation, ThamizhiPOSt and ThamizhiMorph for generating Part of Speech (POS) and Morphological annotations, and uuparser with multilingual training for dependency parsing. ThamizhiPOSt is our POS tagger, which is based on the Stanza, trained with Amrita POS-tagged corpus. It is the current state-of-the-art in Tamil POS tagging with an F1 score of 93.27. Our morphological analyzer, ThamizhiMorph is a rule-based system with a very good coverage of Tamil. Our dependency parser ThamizhiUDp was trained using multilingual data. It shows a Labelled Assigned Score (LAS) of 62.39, 4 points higher than the current best achieved for Tamil dependency parsing. Therefore, we show that breaking up the dependency parsing pipeline to accommodate existing tools and resources is a viable approach for low-resource languages.
Data Augmentation and Terminology Integration for Domain-Specific Sinhala-English-Tamil Statistical Machine Translation
Nov 06, 2020


Out of vocabulary (OOV) is a problem in the context of Machine Translation (MT) in low-resourced languages. When source and/or target languages are morphologically rich, it becomes even worse. Bilingual list integration is an approach to address the OOV problem. This allows more words to be translated than are in the training data. However, since bilingual lists contain words in the base form, it will not translate inflected forms for morphologically rich languages such as Sinhala and Tamil. This paper focuses on data augmentation techniques where bilingual lexicon terms are expanded based on case-markers with the objective of generating new words, to be used in Statistical machine Translation (SMT). This data augmentation technique for dictionary terms shows improved BLEU scores for Sinhala-English SMT.