 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the quality of Web-mined Parallel Corpora of Low-Resource Languages using Debiasing Heuristics
Feb 26, 2025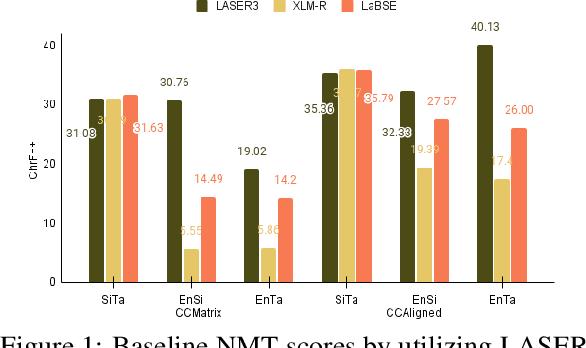



Parallel Data Curation (PDC) techniques aim to filter out noisy parallel sentences from the web-mined corpora. Prior research has demonstrated that ranking sentence pairs using similarity scores on sentence embeddings derived from Pre-trained Multilingual Language Models (multiPLMs) and training the NMT systems with the top-ranked samples, produces superior NMT performance than when trained using the full dataset. However, previous research has shown that the choice of multiPLM significantly impacts the ranking quality. This paper investigates the reasons behind this disparity across multiPLMs. Using the web-mined corpora CCMatrix and CCAligned for En$\rightarrow$Si, En$\rightarrow$Ta and Si$\rightarrow$Ta, we show that different multiPLMs (LASER3, XLM-R, and LaBSE) are biased towards certain types of sentences, which allows noisy sentences to creep into the top-ranked samples. We show that by employing a series of heuristics, this noise can be removed to a certain extent. This results in improving the results of NMT systems trained with web-mined corpora and reduces the disparity across multiPLMs.
Linguistic Entity Masking to Improve Cross-Lingual Representation of Multilingual Language Models for Low-Resource Languages
Jan 10, 2025



Multilingual Pre-trained Language models (multiPLMs), trained on the Masked Language Modelling (MLM) objective are commonly being used for cross-lingual tasks such as bitext mining. However, the performance of these models is still suboptimal for low-resource languages (LRLs). To improve the language representation of a given multiPLM, it is possible to further pre-train it. This is known as continual pre-training. Previous research has shown that continual pre-training with MLM and subsequently with Translation Language Modelling (TLM) improves the cross-lingual representation of multiPLMs. However, during masking, both MLM and TLM give equal weight to all tokens in the input sequence, irrespective of the linguistic properties of the tokens. In this paper, we introduce a novel masking strategy, Linguistic Entity Masking (LEM) to be used in the continual pre-training step to further improve the cross-lingual representations of existing multiPLMs. In contrast to MLM and TLM, LEM limits masking to the linguistic entity types nouns, verbs and named entities, which hold a higher prominence in a sentence. Secondly, we limit masking to a single token within the linguistic entity span thus keeping more context, whereas, in MLM and TLM, tokens are masked randomly. We evaluate the effectiveness of LEM using three downstream tasks, namely bitext mining, parallel data curation and code-mixed sentiment analysis using three low-resource language pairs English-Sinhala, English-Tamil, and Sinhala-Tamil. Experiment results show that continually pre-training a multiPLM with LEM outperforms a multiPLM continually pre-trained with MLM+TLM for all three tasks.
Shoulders of Giants: A Look at the Degree and Utility of Openness in NLP Research
Jun 10, 2024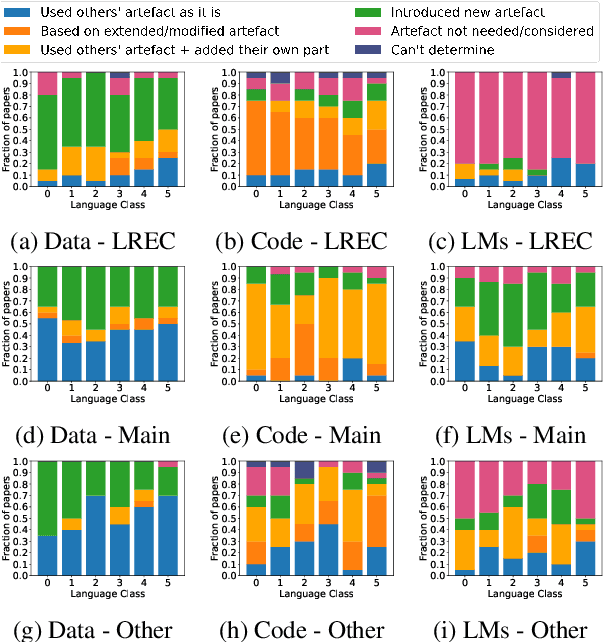



We analysed a sample of NLP research papers archived in ACL Anthology as an attempt to quantify the degree of openness and the benefit of such an open culture in the NLP community. We observe that papers published in different NLP venues show different patterns related to artefact reuse. We also note that more than 30% of the papers we analysed do not release their artefacts publicly, despite promising to do so. Further, we observe a wide language-wise disparity in publicly available NLP-related artefacts.
Quality Does Matter: A Detailed Look at the Quality and Utility of Web-Mined Parallel Corpora
Feb 13, 2024



We conducted a detailed analysis on the quality of web-mined corpora for two low-resource languages (making three language pairs, English-Sinhala, English-Tamil and Sinhala-Tamil). We ranked each corpus according to a similarity measure and carried out an intrinsic and extrinsic evaluation on different portions of this ranked corpus. We show that there are significant quality differences between different portions of web-mined corpora and that the quality varies across languages and datasets. We also show that, for some web-mined datasets, Neural Machine Translation (NMT) models trained with their highest-ranked 25k portion can be on par with human-curated datasets.
Data Augmentation to Address Out-of-Vocabulary Problem in Low-Resource Sinhala-English Neural Machine Translation
May 18, 2022
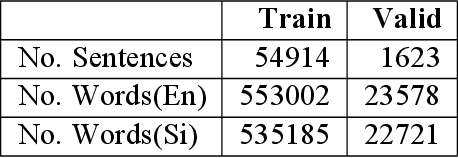

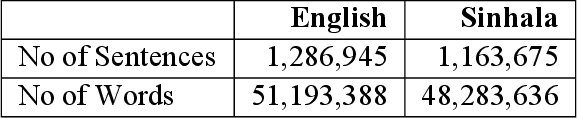
Out-of-Vocabulary (OOV) is a problem for Neural Machine Translation (NMT). OOV refers to words with a low occurrence in the training data, or to those that are absent from the training data. To alleviate this, word or phrase-based Data Augmentation (DA) techniques have been used. However, existing DA techniques have addressed only one of these OOV types and limit to considering either syntactic constraints or semantic constraints. We present a word and phrase replacement-based DA technique that consider both types of OOV, by augmenting (1) rare words in the existing parallel corpus, and (2) new words from a bilingual dictionary. During augmentation, we consider both syntactic and semantic properties of the words to guarantee fluency in the synthetic sentences. This technique was experimented with low resource Sinhala-English language pair. We observe with only semantic constraints in the DA, the results are comparable with the scores obtained considering syntactic constraints, and is favourable for low-resourced languages that lacks linguistic tool support. Additionally, results can be further improved by considering both syntactic and semantic constraints.
Data Augmentation and Terminology Integration for Domain-Specific Sinhala-English-Tamil Statistical Machine Translation
Nov 06, 2020


Out of vocabulary (OOV) is a problem in the context of Machine Translation (MT) in low-resourced languages. When source and/or target languages are morphologically rich, it becomes even worse. Bilingual list integration is an approach to address the OOV problem. This allows more words to be translated than are in the training data. However, since bilingual lists contain words in the base form, it will not translate inflected forms for morphologically rich languages such as Sinhala and Tamil. This paper focuses on data augmentation techniques where bilingual lexicon terms are expanded based on case-markers with the objective of generating new words, to be used in Statistical machine Translation (SMT). This data augmentation technique for dictionary terms shows improved BLEU scores for Sinhala-English SMT.