 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the quality of Web-mined Parallel Corpora of Low-Resource Languages using Debiasing Heuristics
Paper and Code
Feb 26, 2025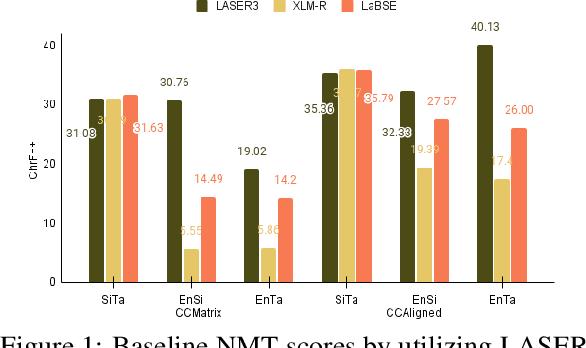



Parallel Data Curation (PDC) techniques aim to filter out noisy parallel sentences from the web-mined corpora. Prior research has demonstrated that ranking sentence pairs using similarity scores on sentence embeddings derived from Pre-trained Multilingual Language Models (multiPLMs) and training the NMT systems with the top-ranked samples, produces superior NMT performance than when trained using the full dataset. However, previous research has shown that the choice of multiPLM significantly impacts the ranking quality. This paper investigates the reasons behind this disparity across multiPLMs. Using the web-mined corpora CCMatrix and CCAligned for En$\rightarrow$Si, En$\rightarrow$Ta and Si$\rightarrow$Ta, we show that different multiPLMs (LASER3, XLM-R, and LaBSE) are biased towards certain types of sentences, which allows noisy sentences to creep into the top-ranked samples. We show that by employing a series of heuristics, this noise can be removed to a certain extent. This results in improving the results of NMT systems trained with web-mined corpora and reduces the disparity across multiPLMs.