 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSection-Weighted Hybrid Approach for Legal Case Retrieval
Jun 02, 2026Finding truly analogous precedents requires capturing legal reasoning beyond surface word overlap. We present a two-stage, section-aware framework for legal case retrieval that first segments raw judgments into facts, issues, decision, and reasoning using a deterministic large language model (LLM) offline. In Stage 1, we combine parallel lexical (BM25) and semantic (dense ANN) whole-document searches via Reciprocal Rank Fusion (RRF) to form a high-recall candidate pool. In Stage 2, we perform fine-grained, like-for-like comparisons (e.g., query reasoning vs. candidate reasoning). To address the scale mismatch between unbounded lexical scores and cosine similarities, we apply query-wise Z-score normalization before aggregating signals with learned section weights. For the top results, the system returns the relevant section text with a concise, grounded rationale and party-stance labels. We evaluate on a jurisdiction-scale benchmark, demonstrating consistent gains over strong lexical and neural baselines while maintaining high candidate coverage
SiDiaC-v.2.0: Sinhala Diachronic Corpus Version 2.0
Mar 11, 2026SiDiaC-v.2.0 is the largest comprehensive Sinhala Diachronic Corpus to date, covering a period from 1800 CE to 1955 CE in terms of publication dates, and a historical span from the 5th to the 20th century CE in terms of written dates. The corpus consists of 244k words across 185 literary works that underwent thorough filtering, preprocessing, and copyright compliance checks, followed by extensive post-processing. Additionally, a subset of 59 documents totalling 70k words was annotated based on their written dates. Texts from the National Library of Sri Lanka were selected from the SiDiaC-v.1.0 non-filtered list, which was digitised using Google Document AI OCR. This was followed by post-processing to correct formatting issues, address code-mixing, include special tokens, and fix malformed tokens. The construction of SiDiaC-v.2.0 was informed by practices from other corpora, such as FarPaHC, SiDiaC-v.1.0, and CCOHA. This was particularly relevant for syntactic annotation and text normalisation strategies, given the shared characteristics of low-resource language status between Faroese and the similar cleaning strategies utilised in CCOHA. This corpus is categorised into two layers based on genres: primary and secondary. The primary categorisation is binary, assigning each book to either Non-Fiction or Fiction. The secondary categorisation is more detailed, grouping texts under specific genres such as Religious, History, Poetry, Language, and Medical. Despite facing challenges due to limited resources, SiDiaC-v.2.0 serves as a comprehensive resource for Sinhala NLP, building upon the work previously done in SiDiaC-v.1.0.
Sinhala Physical Common Sense Reasoning Dataset for Global PIQA
Feb 02, 2026This paper presents the first-ever Sinhala physical common sense reasoning dataset created as part of Global PIQA. It contains 110 human-created and verified data samples, where each sample consists of a prompt, the corresponding correct answer, and a wrong answer. Most of the questions refer to the Sri Lankan context, where Sinhala is an official language.
How Good is BLI as an Alignment Measure: A Study in Word Embedding Paradigm
Nov 17, 2025Sans a dwindling number of monolingual embedding studies originating predominantly from the low-resource domains, it is evident that multilingual embedding has become the de facto choice due to its adaptability to the usage of code-mixed languages, granting the ability to process multilingual documents in a language-agnostic manner, as well as removing the difficult task of aligning monolingual embeddings. But is this victory complete? Are the multilingual models better than aligned monolingual models in every aspect? Can the higher computational cost of multilingual models always be justified? Or is there a compromise between the two extremes? Bilingual Lexicon Induction is one of the most widely used metrics in terms of evaluating the degree of alignment between two embedding spaces. In this study, we explore the strengths and limitations of BLI as a measure to evaluate the degree of alignment of two embedding spaces. Further, we evaluate how well traditional embedding alignment techniques, novel multilingual models, and combined alignment techniques perform BLI tasks in the contexts of both high-resource and low-resource languages. In addition to that, we investigate the impact of the language families to which the pairs of languages belong. We identify that BLI does not measure the true degree of alignment in some cases and we propose solutions for them. We propose a novel stem-based BLI approach to evaluate two aligned embedding spaces that take into account the inflected nature of languages as opposed to the prevalent word-based BLI techniques. Further, we introduce a vocabulary pruning technique that is more informative in showing the degree of the alignment, especially performing BLI on multilingual embedding models. Often, combined embedding alignment techniques perform better while in certain cases multilingual embeddings perform better (mainly low-resource language cases).
DESS: DeBERTa Enhanced Syntactic-Semantic Aspect Sentiment Triplet Extraction
Nov 13, 2025Fine-grained sentiment analysis faces ongoing challenges in Aspect Sentiment Triple Extraction (ASTE), particularly in accurately capturing the relationships between aspects, opinions, and sentiment polarities. While researchers have made progress using BERT and Graph Neural Networks, the full potential of advanced language models in understanding complex language patterns remains unexplored. We introduce DESS, a new approach that builds upon previous work by integrating DeBERTa's enhanced attention mechanism to better understand context and relationships in text. Our framework maintains a dual-channel structure, where DeBERTa works alongside an LSTM channel to process both meaning and grammatical patterns in text. We have carefully refined how these components work together, paying special attention to how different types of language information interact. When we tested DESS on standard datasets, it showed meaningful improvements over current methods, with F1-score increases of 4.85, 8.36, and 2.42 in identifying aspect opinion pairs and determining sentiment accurately. Looking deeper into the results, we found that DeBERTa's sophisticated attention system helps DESS handle complicated sentence structures better, especially when important words are far apart. Our findings suggest that upgrading to more advanced language models when thoughtfully integrated, can lead to real improvements in how well we can analyze sentiments in text. The implementation of our approach is publicly available at: https://github.com/VishalRepos/DESS.
Utilizing Multilingual Encoders to Improve Large Language Models for Low-Resource Languages
Aug 12, 2025

Large Language Models (LLMs) excel in English, but their performance degrades significantly on low-resource languages (LRLs) due to English-centric training. While methods like LangBridge align LLMs with multilingual encoders such as the Massively Multilingual Text-to-Text Transfer Transformer (mT5), they typically use only the final encoder layer. We propose a novel architecture that fuses all intermediate layers, enriching the linguistic information passed to the LLM. Our approach features two strategies: (1) a Global Softmax weighting for overall layer importance, and (2) a Transformer Softmax model that learns token-specific weights. The fused representations are mapped into the LLM's embedding space, enabling it to process multilingual inputs. The model is trained only on English data, without using any parallel or multilingual data. Evaluated on XNLI, IndicXNLI, Sinhala News Classification, and Amazon Reviews, our Transformer Softmax model significantly outperforms the LangBridge baseline. We observe strong performance gains in LRLs, improving Sinhala classification accuracy from 71.66% to 75.86% and achieving clear improvements across Indic languages such as Tamil, Bengali, and Malayalam. These specific gains contribute to an overall boost in average XNLI accuracy from 70.36% to 71.50%. This approach offers a scalable, data-efficient path toward more capable and equitable multilingual LLMs.
SinLlama -- A Large Language Model for Sinhala
Aug 12, 2025Low-resource languages such as Sinhala are often overlooked by open-source Large Language Models (LLMs). In this research, we extend an existing multilingual LLM (Llama-3-8B) to better serve Sinhala. We enhance the LLM tokenizer with Sinhala specific vocabulary and perform continual pre-training on a cleaned 10 million Sinhala corpus, resulting in the SinLlama model. This is the very first decoder-based open-source LLM with explicit Sinhala support. When SinLlama was instruction fine-tuned for three text classification tasks, it outperformed base and instruct variants of Llama-3-8B by a significant margin.
Improving the quality of Web-mined Parallel Corpora of Low-Resource Languages using Debiasing Heuristics
Feb 26, 2025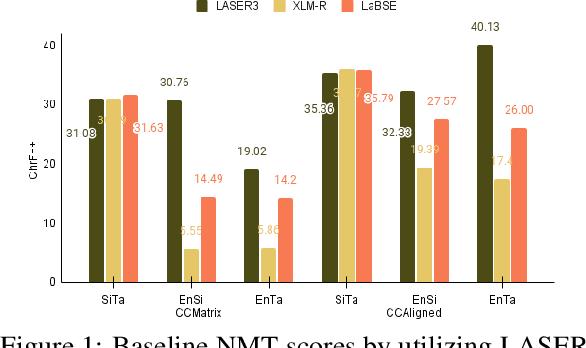



Parallel Data Curation (PDC) techniques aim to filter out noisy parallel sentences from the web-mined corpora. Prior research has demonstrated that ranking sentence pairs using similarity scores on sentence embeddings derived from Pre-trained Multilingual Language Models (multiPLMs) and training the NMT systems with the top-ranked samples, produces superior NMT performance than when trained using the full dataset. However, previous research has shown that the choice of multiPLM significantly impacts the ranking quality. This paper investigates the reasons behind this disparity across multiPLMs. Using the web-mined corpora CCMatrix and CCAligned for En$\rightarrow$Si, En$\rightarrow$Ta and Si$\rightarrow$Ta, we show that different multiPLMs (LASER3, XLM-R, and LaBSE) are biased towards certain types of sentences, which allows noisy sentences to creep into the top-ranked samples. We show that by employing a series of heuristics, this noise can be removed to a certain extent. This results in improving the results of NMT systems trained with web-mined corpora and reduces the disparity across multiPLMs.
Linguistic Analysis of Sinhala YouTube Comments on Sinhala Music Videos: A Dataset Study
Jan 28, 2025



This research investigates the area of Music Information Retrieval (MIR) and Music Emotion Recognition (MER) in relation to Sinhala songs, an underexplored field in music studies. The purpose of this study is to analyze the behavior of Sinhala comments on YouTube Sinhala song videos using social media comments as primary data sources. These included comments from 27 YouTube videos containing 20 different Sinhala songs, which were carefully selected so that strict linguistic reliability would be maintained and relevancy ensured. This process led to a total of 93,116 comments being gathered upon which the dataset was refined further by advanced filtering methods and transliteration mechanisms resulting into 63,471 Sinhala comments. Additionally, 964 stop-words specific for the Sinhala language were algorithmically derived out of which 182 matched exactly with English stop-words from NLTK corpus once translated. Also, comparisons were made between general domain corpora in Sinhala against the YouTube Comment Corpus in Sinhala confirming latter as good representation of general domain. The meticulously curated data set as well as the derived stop-words form important resources for future research in the fields of MIR and MER, since they could be used and demonstrate that there are possibilities with computational techniques to solve complex musical experiences across varied cultural traditions
Sinhala Transliteration: A Comparative Analysis Between Rule-based and Seq2Seq Approaches
Dec 31, 2024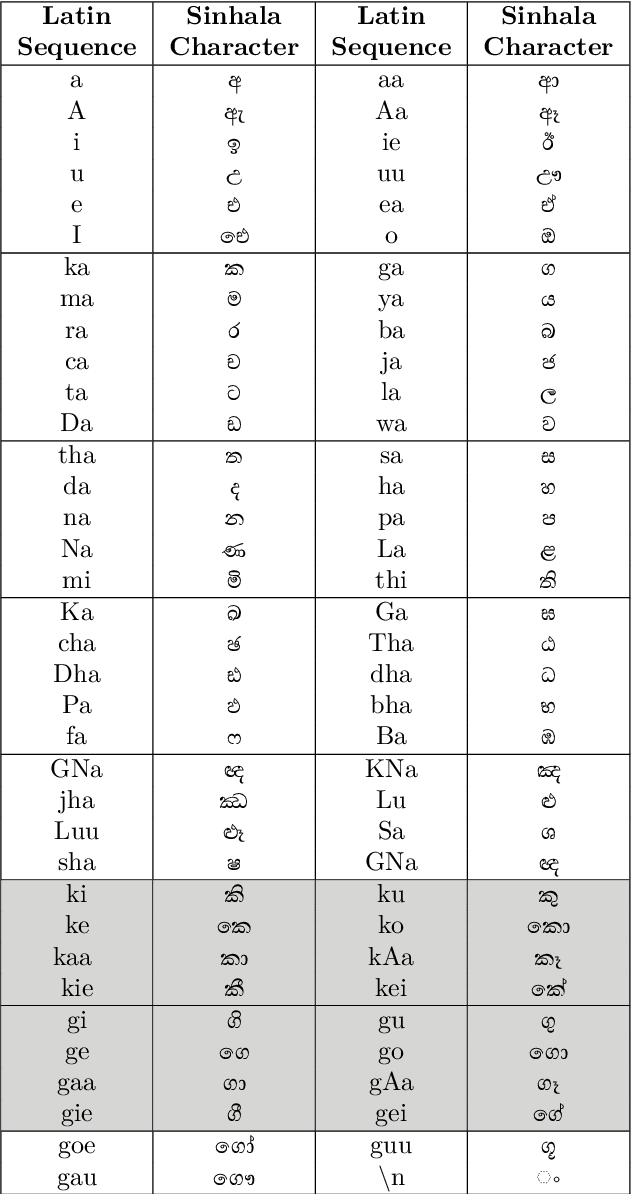


Due to reasons of convenience and lack of tech literacy, transliteration (i.e., Romanizing native scripts instead of using localization tools) is eminently prevalent in the context of low-resource languages such as Sinhala, which have their own writing script. In this study, our focus is on Romanized Sinhala transliteration. We propose two methods to address this problem: Our baseline is a rule-based method, which is then compared against our second method where we approach the transliteration problem as a sequence-to-sequence task akin to the established Neural Machine Translation (NMT) task. For the latter, we propose a Transformer-based Encode-Decoder solution. We witnessed that the Transformer-based method could grab many ad-hoc patterns within the Romanized scripts compared to the rule-based method. The code base associated with this paper is available on GitHub - https://github.com/kasunw22/Sinhala-Transliterator/