 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Bilingual Lexicon Induction for Low Resource Languages
Dec 22, 2024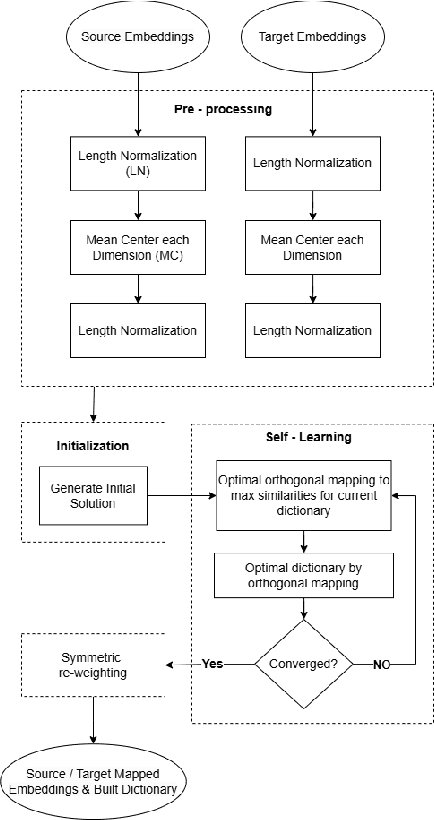
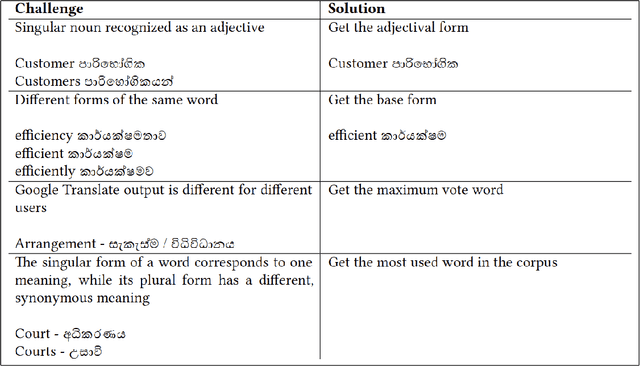
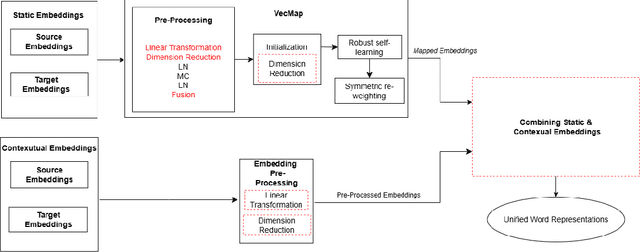
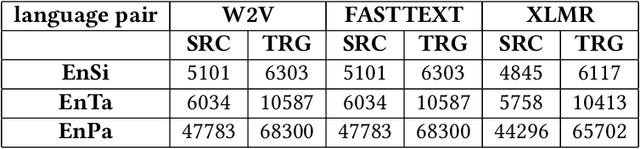
Bilingual lexicons play a crucial role in various Natural Language Processing tasks. However, many low-resource languages (LRLs) do not have such lexicons, and due to the same reason, cannot benefit from the supervised Bilingual Lexicon Induction (BLI) techniques. To address this, unsupervised BLI (UBLI) techniques were introduced. A prominent technique in this line is structure-based UBLI. It is an iterative method, where a seed lexicon, which is initially learned from monolingual embeddings is iteratively improved. There have been numerous improvements to this core idea, however they have been experimented with independently of each other. In this paper, we investigate whether using these techniques simultaneously would lead to equal gains. We use the unsupervised version of VecMap, a commonly used structure-based UBLI framework, and carry out a comprehensive set of experiments using the LRL pairs, English-Sinhala, English-Tamil, and English-Punjabi. These experiments helped us to identify the best combination of the extensions. We also release bilingual dictionaries for English-Sinhala and English-Punjabi.
Quality Does Matter: A Detailed Look at the Quality and Utility of Web-Mined Parallel Corpora
Feb 13, 2024



We conducted a detailed analysis on the quality of web-mined corpora for two low-resource languages (making three language pairs, English-Sinhala, English-Tamil and Sinhala-Tamil). We ranked each corpus according to a similarity measure and carried out an intrinsic and extrinsic evaluation on different portions of this ranked corpus. We show that there are significant quality differences between different portions of web-mined corpora and that the quality varies across languages and datasets. We also show that, for some web-mined datasets, Neural Machine Translation (NMT) models trained with their highest-ranked 25k portion can be on par with human-curated datasets.