 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHADE: Semantic Hypernym Annotator for Domain-specific Entities -- DnD Domain Use Case
Paper and Code
Jun 29, 2024


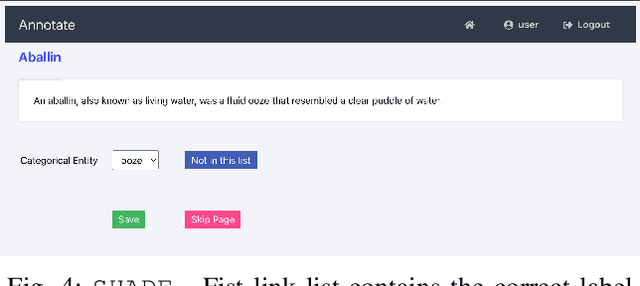
Manual data annotation is an important NLP task but one that takes considerable amount of resources and effort. In spite of the costs, labeling and categorizing entities is essential for NLP tasks such as semantic evaluation. Even though annotation can be done by non-experts in most cases, due to the fact that this requires human labor, the process is costly. Another major challenge encountered in data annotation is maintaining the annotation consistency. Annotation efforts are typically carried out by teams of multiple annotators. The annotations need to maintain the consistency in relation to both the domain truth and annotation format while reducing human errors. Annotating a specialized domain that deviates significantly from the general domain, such as fantasy literature, will see a lot of human error and annotator disagreement. So it is vital that proper guidelines and error reduction mechanisms are enforced. One such way to enforce these constraints is using a specialized application. Such an app can ensure that the notations are consistent, and the labels can be pre-defined or restricted reducing the room for errors. In this paper, we present SHADE, an annotation software that can be used to annotate entities in the high fantasy literature domain. Specifically in Dungeons and Dragons lore extracted from the Forgotten Realms Fandom Wiki.