 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Multilingual Divide and Its Impact on Global AI Safety
May 27, 2025Despite advances in large language model capabilities in recent years, a large gap remains in their capabilities and safety performance for many languages beyond a relatively small handful of globally dominant languages. This paper provides researchers, policymakers and governance experts with an overview of key challenges to bridging the "language gap" in AI and minimizing safety risks across languages. We provide an analysis of why the language gap in AI exists and grows, and how it creates disparities in global AI safety. We identify barriers to address these challenges, and recommend how those working in policy and governance can help address safety concerns associated with the language gap by supporting multilingual dataset creation, transparency, and research.
MAPS: A Multilingual Benchmark for Global Agent Performance and Security
May 21, 2025Agentic AI systems, which build on Large Language Models (LLMs) and interact with tools and memory, have rapidly advanced in capability and scope. Yet, since LLMs have been shown to struggle in multilingual settings, typically resulting in lower performance and reduced safety, agentic systems risk inheriting these limitations. This raises concerns about the global accessibility of such systems, as users interacting in languages other than English may encounter unreliable or security-critical agent behavior. Despite growing interest in evaluating agentic AI, existing benchmarks focus exclusively on English, leaving multilingual settings unexplored. To address this gap, we propose MAPS, a multilingual benchmark suite designed to evaluate agentic AI systems across diverse languages and tasks. MAPS builds on four widely used agentic benchmarks - GAIA (real-world tasks), SWE-bench (code generation), MATH (mathematical reasoning), and the Agent Security Benchmark (security). We translate each dataset into ten diverse languages, resulting in 805 unique tasks and 8,855 total language-specific instances. Our benchmark suite enables a systematic analysis of how multilingual contexts affect agent performance and robustness. Empirically, we observe consistent degradation in both performance and security when transitioning from English to other languages, with severity varying by task and correlating with the amount of translated input. Building on these findings, we provide actionable recommendations to guide agentic AI systems development and assessment under multilingual settings. This work establishes a standardized evaluation framework, encouraging future research towards equitable, reliable, and globally accessible agentic AI. MAPS benchmark suite is publicly available at https://huggingface.co/datasets/Fujitsu-FRE/MAPS
The Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs
Apr 24, 2025Sparse attention offers a promising strategy to extend long-context capabilities in Transformer LLMs, yet its viability, its efficiency-accuracy trade-offs, and systematic scaling studies remain unexplored. To address this gap, we perform a careful comparison of training-free sparse attention methods at varying model scales, sequence lengths, and sparsity levels on a diverse collection of long-sequence tasks-including novel ones that rely on natural language while remaining controllable and easy to evaluate. Based on our experiments, we report a series of key findings: 1) an isoFLOPS analysis reveals that for very long sequences, larger and highly sparse models are preferable to smaller and dense ones. 2) The level of sparsity attainable while statistically guaranteeing accuracy preservation is higher during decoding than prefilling, and correlates with model size in the former. 3) There is no clear strategy that performs best across tasks and phases, with different units of sparsification or budget adaptivity needed for different scenarios. Even moderate sparsity levels often result in significant performance degradation on at least one task, highlighting that sparse attention is not a universal solution. 4) We introduce and validate novel scaling laws specifically tailored for sparse attention, providing evidence that our findings are likely to hold true beyond our range of experiments. Through these insights, we demonstrate that sparse attention is a key tool to enhance the capabilities of Transformer LLMs for processing longer sequences, but requires careful evaluation of trade-offs for performance-sensitive applications.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
AL-QASIDA: Analyzing LLM Quality and Accuracy Systematically in Dialectal Arabic
Dec 05, 2024



Dialectal Arabic (DA) varieties are under-served by language technologies, particularly large language models (LLMs). This trend threatens to exacerbate existing social inequalities and limits language modeling applications, yet the research community lacks operationalized LLM performance measurements in DA. We present a method that comprehensively evaluates LLM fidelity, understanding, quality, and diglossia in modeling DA. We evaluate nine LLMs in eight DA varieties across these four dimensions and provide best practice recommendations. Our evaluation suggests that LLMs do not produce DA as well as they understand it, but does not suggest deterioration in quality when they do. Further analysis suggests that current post-training can degrade DA capabilities, that few-shot examples can overcome this and other LLM deficiencies, and that otherwise no measurable features of input text correlate well with LLM DA performance.
Global MMLU: Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation
Dec 04, 2024



Cultural biases in multilingual datasets pose significant challenges for their effectiveness as global benchmarks. These biases stem not only from language but also from the cultural knowledge required to interpret questions, reducing the practical utility of translated datasets like MMLU. Furthermore, translation often introduces artifacts that can distort the meaning or clarity of questions in the target language. A common practice in multilingual evaluation is to rely on machine-translated evaluation sets, but simply translating a dataset is insufficient to address these challenges. In this work, we trace the impact of both of these issues on multilingual evaluations and ensuing model performances. Our large-scale evaluation of state-of-the-art open and proprietary models illustrates that progress on MMLU depends heavily on learning Western-centric concepts, with 28% of all questions requiring culturally sensitive knowledge. Moreover, for questions requiring geographic knowledge, an astounding 84.9% focus on either North American or European regions. Rankings of model evaluations change depending on whether they are evaluated on the full portion or the subset of questions annotated as culturally sensitive, showing the distortion to model rankings when blindly relying on translated MMLU. We release Global-MMLU, an improved MMLU with evaluation coverage across 42 languages -- with improved overall quality by engaging with compensated professional and community annotators to verify translation quality while also rigorously evaluating cultural biases present in the original dataset. This comprehensive Global-MMLU set also includes designated subsets labeled as culturally sensitive and culturally agnostic to allow for more holistic, complete evaluation.
How Does Quantization Affect Multilingual LLMs?
Jul 03, 2024Quantization techniques are widely used to improve inference speed and deployment of large language models. While a wide body of work examines the impact of quantized LLMs on English tasks, none have examined the effect of quantization across languages. We conduct a thorough analysis of quantized multilingual LLMs, focusing on their performance across languages and at varying scales. We use automatic benchmarks, LLM-as-a-Judge methods, and human evaluation, finding that (1) harmful effects of quantization are apparent in human evaluation, and automatic metrics severely underestimate the detriment: a 1.7% average drop in Japanese across automatic tasks corresponds to a 16.0% drop reported by human evaluators on realistic prompts; (2) languages are disparately affected by quantization, with non-Latin script languages impacted worst; and (3) challenging tasks such as mathematical reasoning degrade fastest. As the ability to serve low-compute models is critical for wide global adoption of NLP technologies, our results urge consideration of multilingual performance as a key evaluation criterion for efficient models.
RLHF Can Speak Many Languages: Unlocking Multilingual Preference Optimization for LLMs
Jul 02, 2024Preference optimization techniques have become a standard final stage for training state-of-art large language models (LLMs). However, despite widespread adoption, the vast majority of work to-date has focused on first-class citizen languages like English and Chinese. This captures a small fraction of the languages in the world, but also makes it unclear which aspects of current state-of-the-art research transfer to a multilingual setting. In this work, we perform an exhaustive study to achieve a new state-of-the-art in aligning multilingual LLMs. We introduce a novel, scalable method for generating high-quality multilingual feedback data to balance data coverage. We establish the benefits of cross-lingual transfer and increased dataset size in preference training. Our preference-trained model achieves a 54.4% win-rate against Aya 23 8B, the current state-of-the-art multilingual LLM in its parameter class, and a 69.5% win-rate or higher against widely used models like Gemma-1.1-7B-it, Llama-3-8B-Instruct, Mistral-7B-Instruct-v0.3. As a result of our study, we expand the frontier of alignment techniques to 23 languages covering half of the world's population.
Understanding and Mitigating Language Confusion in LLMs
Jun 28, 2024We investigate a surprising limitation of LLMs: their inability to consistently generate text in a user's desired language. We create the Language Confusion Benchmark (LCB) to evaluate such failures, covering 15 typologically diverse languages with existing and newly-created English and multilingual prompts. We evaluate a range of LLMs on monolingual and cross-lingual generation reflecting practical use cases, finding that Llama Instruct and Mistral models exhibit high degrees of language confusion and even the strongest models fail to consistently respond in the correct language. We observe that base and English-centric instruct models are more prone to language confusion, which is aggravated by complex prompts and high sampling temperatures. We find that language confusion can be partially mitigated via few-shot prompting, multilingual SFT and preference tuning. We release our language confusion benchmark, which serves as a first layer of efficient, scalable multilingual evaluation at https://github.com/for-ai/language-confusion.
Aya 23: Open Weight Releases to Further Multilingual Progress
May 23, 2024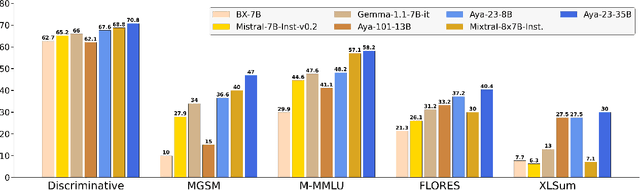

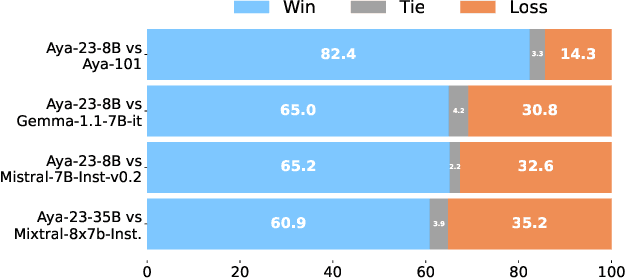

This technical report introduces Aya 23, a family of multilingual language models. Aya 23 builds on the recent release of the Aya model (\"Ust\"un et al., 2024), focusing on pairing a highly performant pre-trained model with the recently released Aya collection (Singh et al., 2024). The result is a powerful multilingual large language model serving 23 languages, expanding state-of-art language modeling capabilities to approximately half of the world's population. The Aya model covered 101 languages whereas Aya 23 is an experiment in depth vs breadth, exploring the impact of allocating more capacity to fewer languages that are included during pre-training. Aya 23 outperforms both previous massively multilingual models like Aya 101 for the languages it covers, as well as widely used models like Gemma, Mistral and Mixtral on an extensive range of discriminative and generative tasks. We release the open weights for both the 8B and 35B models as part of our continued commitment for expanding access to multilingual progress.