 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAya 23: Open Weight Releases to Further Multilingual Progress
Paper and Code
May 23, 2024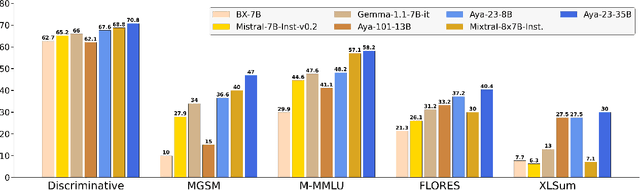

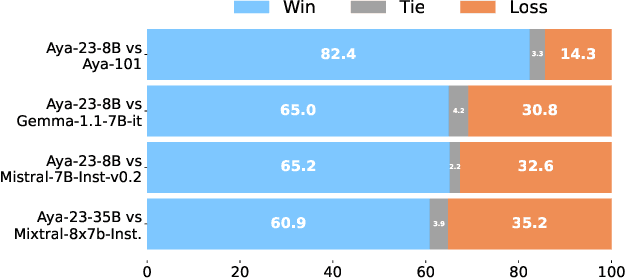

This technical report introduces Aya 23, a family of multilingual language models. Aya 23 builds on the recent release of the Aya model (\"Ust\"un et al., 2024), focusing on pairing a highly performant pre-trained model with the recently released Aya collection (Singh et al., 2024). The result is a powerful multilingual large language model serving 23 languages, expanding state-of-art language modeling capabilities to approximately half of the world's population. The Aya model covered 101 languages whereas Aya 23 is an experiment in depth vs breadth, exploring the impact of allocating more capacity to fewer languages that are included during pre-training. Aya 23 outperforms both previous massively multilingual models like Aya 101 for the languages it covers, as well as widely used models like Gemma, Mistral and Mixtral on an extensive range of discriminative and generative tasks. We release the open weights for both the 8B and 35B models as part of our continued commitment for expanding access to multilingual progress.