 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Investigating the potential of Sparse Mixtures-of-Experts for multi-domain neural machine translation
Jul 01, 2024



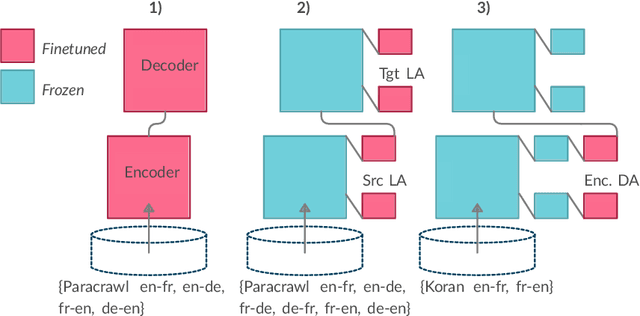
We focus on multi-domain Neural Machine Translation, with the goal of developing efficient models which can handle data from various domains seen during training and are robust to domains unseen during training. We hypothesize that Sparse Mixture-of-Experts (SMoE) models are a good fit for this task, as they enable efficient model scaling, which helps to accommodate a variety of multi-domain data, and allow flexible sharing of parameters between domains, potentially enabling knowledge transfer between similar domains and limiting negative transfer. We conduct a series of experiments aimed at validating the utility of SMoE for the multi-domain scenario, and find that a straightforward width scaling of Transformer is a simpler and surprisingly more efficient approach in practice, and reaches the same performance level as SMoE. We also search for a better recipe for robustness of multi-domain systems, highlighting the importance of mixing-in a generic domain, i.e. Paracrawl, and introducing a simple technique, domain randomization.
Understanding and Mitigating Language Confusion in LLMs
Jun 28, 2024We investigate a surprising limitation of LLMs: their inability to consistently generate text in a user's desired language. We create the Language Confusion Benchmark (LCB) to evaluate such failures, covering 15 typologically diverse languages with existing and newly-created English and multilingual prompts. We evaluate a range of LLMs on monolingual and cross-lingual generation reflecting practical use cases, finding that Llama Instruct and Mistral models exhibit high degrees of language confusion and even the strongest models fail to consistently respond in the correct language. We observe that base and English-centric instruct models are more prone to language confusion, which is aggravated by complex prompts and high sampling temperatures. We find that language confusion can be partially mitigated via few-shot prompting, multilingual SFT and preference tuning. We release our language confusion benchmark, which serves as a first layer of efficient, scalable multilingual evaluation at https://github.com/for-ai/language-confusion.
Multilingual Unsupervised Neural Machine Translation with Denoising Adapters
Oct 20, 2021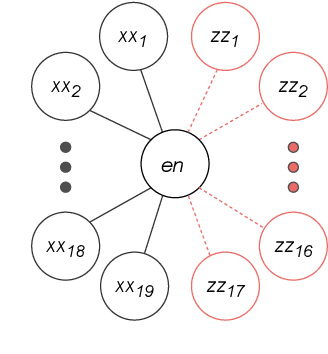

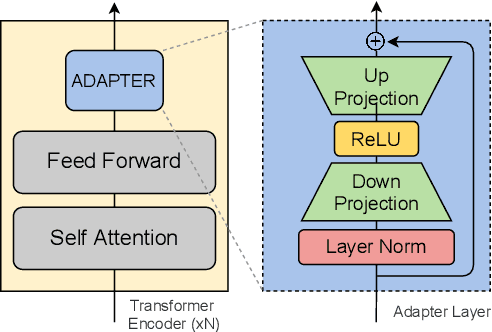

We consider the problem of multilingual unsupervised machine translation, translating to and from languages that only have monolingual data by using auxiliary parallel language pairs. For this problem the standard procedure so far to leverage the monolingual data is back-translation, which is computationally costly and hard to tune. In this paper we propose instead to use denoising adapters, adapter layers with a denoising objective, on top of pre-trained mBART-50. In addition to the modularity and flexibility of such an approach we show that the resulting translations are on-par with back-translating as measured by BLEU, and furthermore it allows adding unseen languages incrementally.
Multilingual Domain Adaptation for NMT: Decoupling Language and Domain Information with Adapters
Oct 18, 2021


Adapter layers are lightweight, learnable units inserted between transformer layers. Recent work explores using such layers for neural machine translation (NMT), to adapt pre-trained models to new domains or language pairs, training only a small set of parameters for each new setting (language pair or domain). In this work we study the compositionality of language and domain adapters in the context of Machine Translation. We aim to study, 1) parameter-efficient adaptation to multiple domains and languages simultaneously (full-resource scenario) and 2) cross-lingual transfer in domains where parallel data is unavailable for certain language pairs (partial-resource scenario). We find that in the partial resource scenario a naive combination of domain-specific and language-specific adapters often results in `catastrophic forgetting' of the missing languages. We study other ways to combine the adapters to alleviate this issue and maximize cross-lingual transfer. With our best adapter combinations, we obtain improvements of 3-4 BLEU on average for source languages that do not have in-domain data. For target languages without in-domain data, we achieve a similar improvement by combining adapters with back-translation. Supplementary material is available at https://tinyurl.com/r66stbxj
A Multilingual Neural Machine Translation Model for Biomedical Data
Aug 06, 2020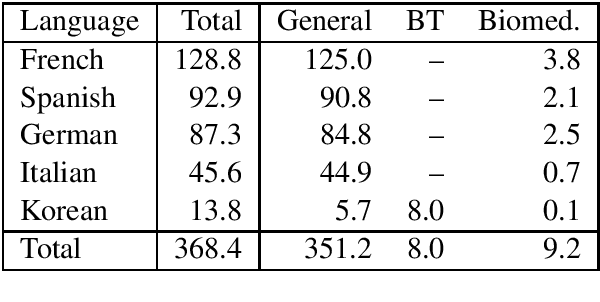

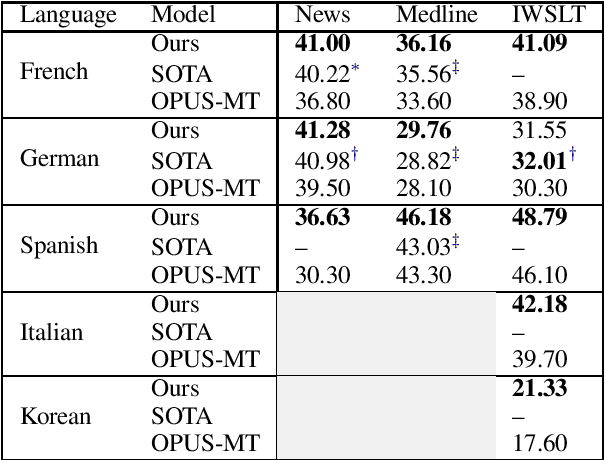
We release a multilingual neural machine translation model, which can be used to translate text in the biomedical domain. The model can translate from 5 languages (French, German, Italian, Korean and Spanish) into English. It is trained with large amounts of generic and biomedical data, using domain tags. Our benchmarks show that it performs near state-of-the-art both on news (generic domain) and biomedical test sets, and that it outperforms the existing publicly released models. We believe that this release will help the large-scale multilingual analysis of the digital content of the COVID-19 crisis and of its effects on society, economy, and healthcare policies. We also release a test set of biomedical text for Korean-English. It consists of 758 sentences from official guidelines and recent papers, all about COVID-19.
Machine Translation of Restaurant Reviews: New Corpus for Domain Adaptation and Robustness
Oct 31, 2019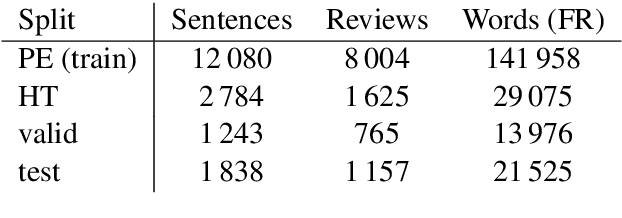


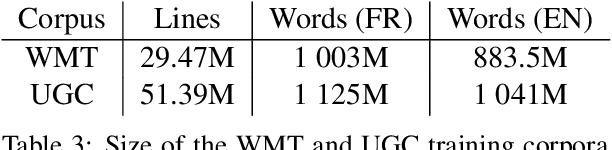
We share a French-English parallel corpus of Foursquare restaurant reviews (https://europe.naverlabs.com/research/natural-language-processing/machine-translation-of-restaurant-reviews), and define a new task to encourage research on Neural Machine Translation robustness and domain adaptation, in a real-world scenario where better-quality MT would be greatly beneficial. We discuss the challenges of such user-generated content, and train good baseline models that build upon the latest techniques for MT robustness. We also perform an extensive evaluation (automatic and human) that shows significant improvements over existing online systems. Finally, we propose task-specific metrics based on sentiment analysis or translation accuracy of domain-specific polysemous words.
Naver Labs Europe's Systems for the Document-Level Generation and Translation Task at WNGT 2019
Oct 31, 2019

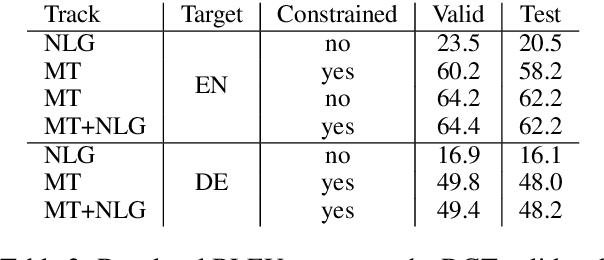
Recently, neural models led to significant improvements in both machine translation (MT) and natural language generation tasks (NLG). However, generation of long descriptive summaries conditioned on structured data remains an open challenge. Likewise, MT that goes beyond sentence-level context is still an open issue (e.g., document-level MT or MT with metadata). To address these challenges, we propose to leverage data from both tasks and do transfer learning between MT, NLG, and MT with source-side metadata (MT+NLG). First, we train document-based MT systems with large amounts of parallel data. Then, we adapt these models to pure NLG and MT+NLG tasks by fine-tuning with smaller amounts of domain-specific data. This end-to-end NLG approach, without data selection and planning, outperforms the previous state of the art on the Rotowire NLG task. We participated to the "Document Generation and Translation" task at WNGT 2019, and ranked first in all tracks.
Naver Labs Europe's Systems for the WMT19 Machine Translation Robustness Task
Jul 15, 2019
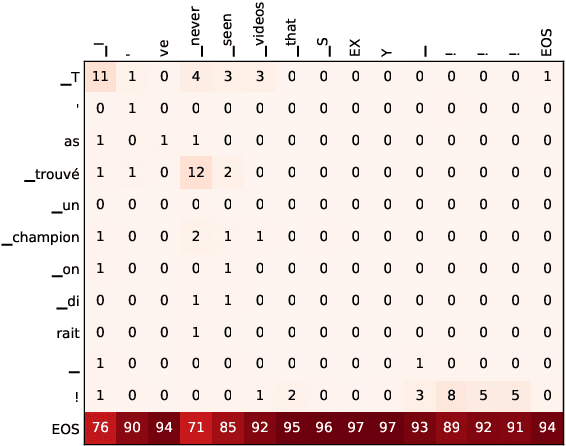
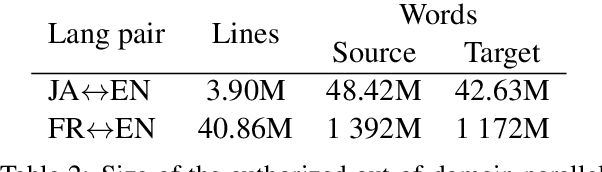
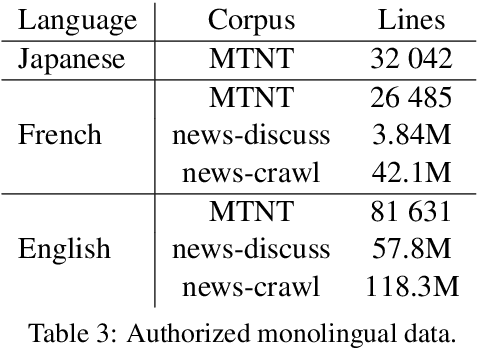
This paper describes the systems that we submitted to the WMT19 Machine Translation robustness task. This task aims to improve MT's robustness to noise found on social media, like informal language, spelling mistakes and other orthographic variations. The organizers provide parallel data extracted from a social media website in two language pairs: French-English and Japanese-English (in both translation directions). The goal is to obtain the best scores on unseen test sets from the same source, according to automatic metrics (BLEU) and human evaluation. We proposed one single and one ensemble system for each translation direction. Our ensemble models ranked first in all language pairs, according to BLEU evaluation. We discuss the pre-processing choices that we made, and present our solutions for robustness to noise and domain adaptation.
End-to-End Automatic Speech Translation of Audiobooks
Feb 12, 2018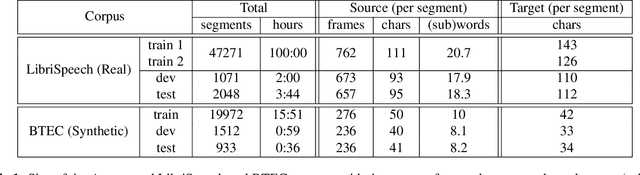
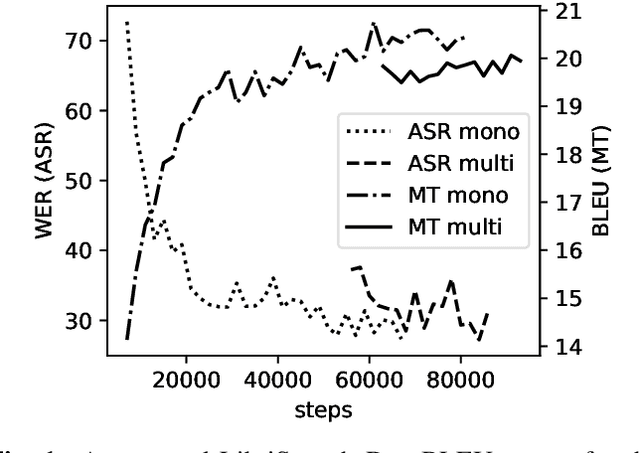
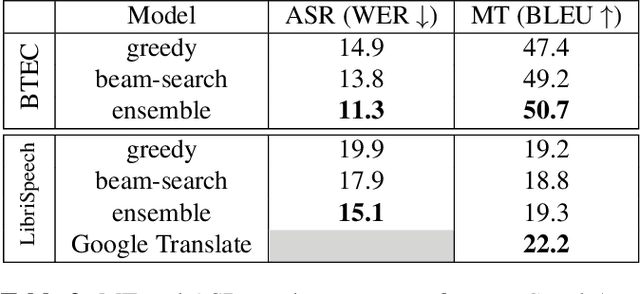

We investigate end-to-end speech-to-text translation on a corpus of audiobooks specifically augmented for this task. Previous works investigated the extreme case where source language transcription is not available during learning nor decoding, but we also study a midway case where source language transcription is available at training time only. In this case, a single model is trained to decode source speech into target text in a single pass. Experimental results show that it is possible to train compact and efficient end-to-end speech translation models in this setup. We also distribute the corpus and hope that our speech translation baseline on this corpus will be challenged in the future.