 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNaver Labs Europe's Systems for the WMT19 Machine Translation Robustness Task
Paper and Code

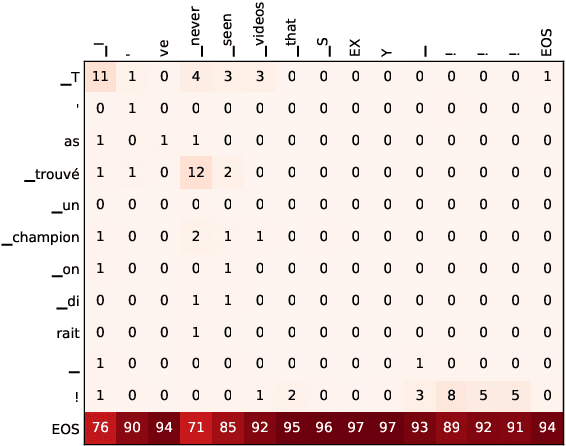
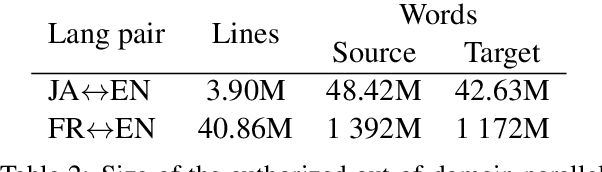
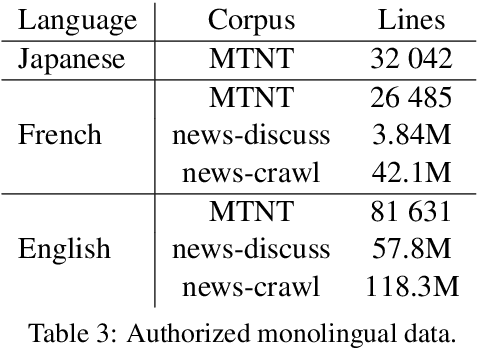
This paper describes the systems that we submitted to the WMT19 Machine Translation robustness task. This task aims to improve MT's robustness to noise found on social media, like informal language, spelling mistakes and other orthographic variations. The organizers provide parallel data extracted from a social media website in two language pairs: French-English and Japanese-English (in both translation directions). The goal is to obtain the best scores on unseen test sets from the same source, according to automatic metrics (BLEU) and human evaluation. We proposed one single and one ensemble system for each translation direction. Our ensemble models ranked first in all language pairs, according to BLEU evaluation. We discuss the pre-processing choices that we made, and present our solutions for robustness to noise and domain adaptation.