 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLARITY: A Framework and Benchmark for Conversational Language Ambiguity and Unanswerability in Interactive NL2SQL Systems
Apr 24, 2026NL2SQL systems deployed in industry settings often encounter ambiguous or unanswerable queries, particularly in interactive scenarios with incomplete user clarification. Existing benchmarks typically assume a single source of ambiguity and rely on user interaction for resolution, overlooking realistic failure modes. We introduce Clarity, a framework for automatically generating an NL2SQL benchmark with multi-faceted ambiguities and diverse user behaviors across both single- and multi-turn settings. Using a constraint-driven pipeline, Clarity transforms executable SQL into ambiguous queries, augmented with grounded conversational continuations and schema-level metadata. Empirical evaluation on Spider and BIRD shows that leading NL2SQL systems, including those based on strong LLMs, suffer significant performance degradation under multi-faceted ambiguity. While these systems often detect ambiguity, they struggle to accurately localize and resolve the underlying schema-level sources. Our results highlight the need for more robust ambiguity detection and resolution in industry-grade NL2SQL systems.
Multilingual Neural Machine Translation:Can Linguistic Hierarchies Help?
Oct 15, 2021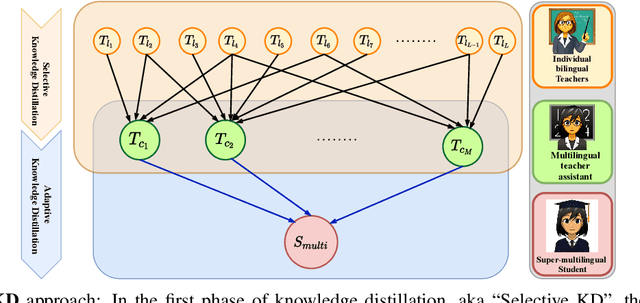
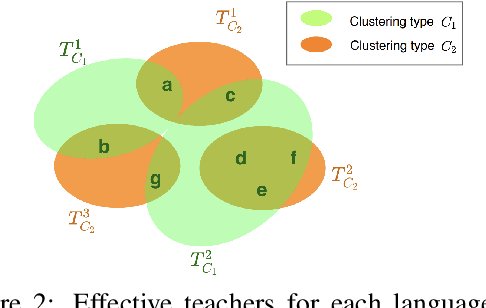

Multilingual Neural Machine Translation (MNMT) trains a single NMT model that supports translation between multiple languages, rather than training separate models for different languages. Learning a single model can enhance the low-resource translation by leveraging data from multiple languages. However, the performance of an MNMT model is highly dependent on the type of languages used in training, as transferring knowledge from a diverse set of languages degrades the translation performance due to negative transfer. In this paper, we propose a Hierarchical Knowledge Distillation (HKD) approach for MNMT which capitalises on language groups generated according to typological features and phylogeny of languages to overcome the issue of negative transfer. HKD generates a set of multilingual teacher-assistant models via a selective knowledge distillation mechanism based on the language groups, and then distils the ultimate multilingual model from those assistants in an adaptive way. Experimental results derived from the TED dataset with 53 languages demonstrate the effectiveness of our approach in avoiding the negative transfer effect in MNMT, leading to an improved translation performance (about 1 BLEU score on average) compared to strong baselines.
Collective Wisdom: Improving Low-resource Neural Machine Translation using Adaptive Knowledge Distillation
Oct 12, 2020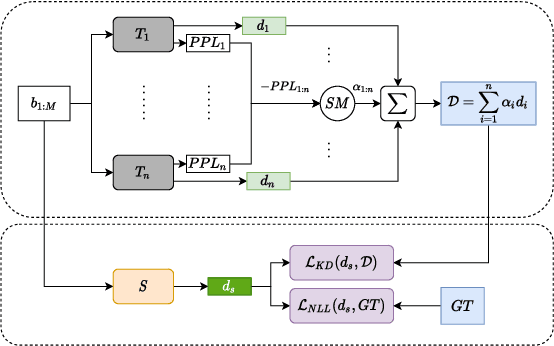

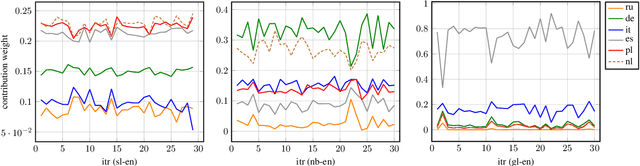
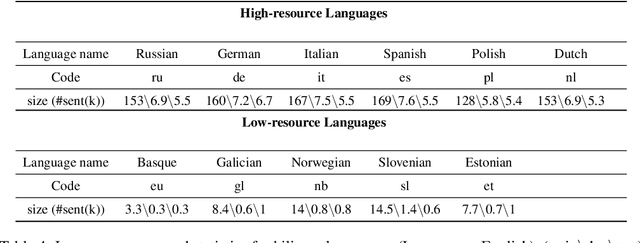
Scarcity of parallel sentence-pairs poses a significant hurdle for training high-quality Neural Machine Translation (NMT) models in bilingually low-resource scenarios. A standard approach is transfer learning, which involves taking a model trained on a high-resource language-pair and fine-tuning it on the data of the low-resource MT condition of interest. However, it is not clear generally which high-resource language-pair offers the best transfer learning for the target MT setting. Furthermore, different transferred models may have complementary semantic and/or syntactic strengths, hence using only one model may be sub-optimal. In this paper, we tackle this problem using knowledge distillation, where we propose to distill the knowledge of ensemble of teacher models to a single student model. As the quality of these teacher models varies, we propose an effective adaptive knowledge distillation approach to dynamically adjust the contribution of the teacher models during the distillation process. Experiments on transferring from a collection of six language pairs from IWSLT to five low-resource language-pairs from TED Talks demonstrate the effectiveness of our approach, achieving up to +0.9 BLEU score improvement compared to strong baselines.
A Survey on Document-level Machine Translation: Methods and Evaluation
Dec 18, 2019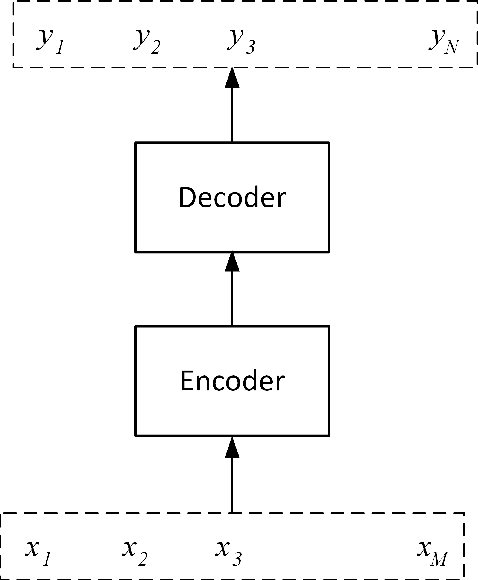
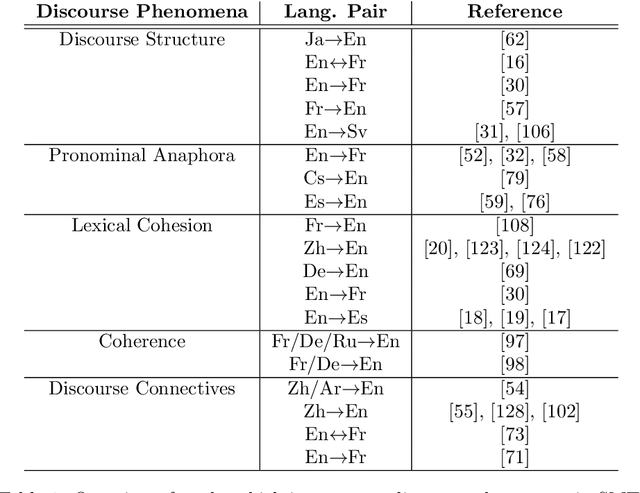
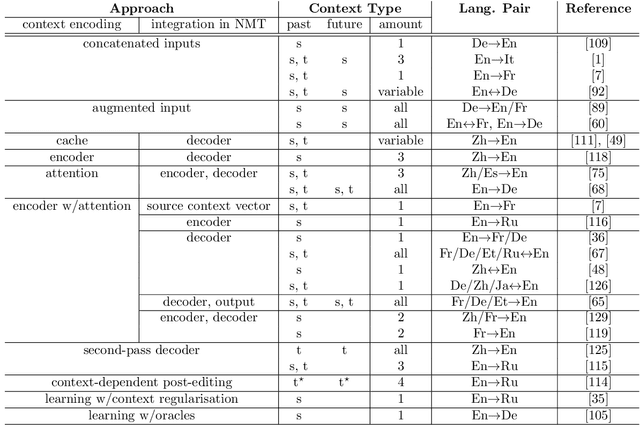
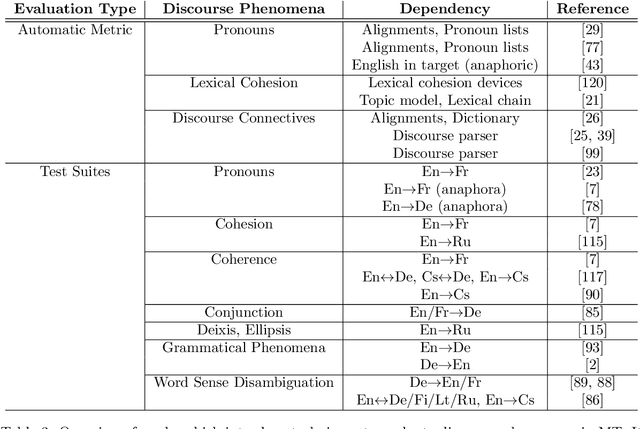
Machine translation (MT) is an important task in natural language processing (NLP) as it automates the translation process and reduces the reliance on human translators. With the advent of neural networks, the translation quality surpasses that of the translations obtained using statistical techniques. Up until three years ago, all neural translation models translated sentences independently, without incorporating any extra-sentential information. The aim of this paper is to highlight the major works that have been undertaken in the space of document-level machine translation before and after the neural revolution so that researchers can recognise where we started from and which direction we are heading in. When talking about the literature in statistical machine translation (SMT), we focus on works which have tried to improve the translation of specific discourse phenomena, while in neural machine translation (NMT), we focus on works which use the wider context explicitly. In addition to this, we also cover the evaluation strategies that have been introduced to account for the improvements in this domain.
Naver Labs Europe's Systems for the Document-Level Generation and Translation Task at WNGT 2019
Oct 31, 2019
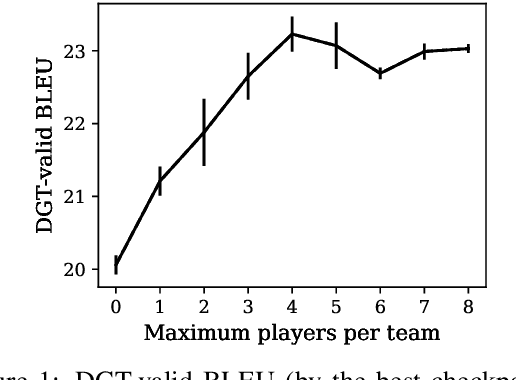

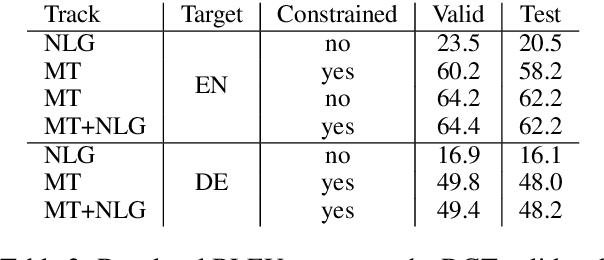
Recently, neural models led to significant improvements in both machine translation (MT) and natural language generation tasks (NLG). However, generation of long descriptive summaries conditioned on structured data remains an open challenge. Likewise, MT that goes beyond sentence-level context is still an open issue (e.g., document-level MT or MT with metadata). To address these challenges, we propose to leverage data from both tasks and do transfer learning between MT, NLG, and MT with source-side metadata (MT+NLG). First, we train document-based MT systems with large amounts of parallel data. Then, we adapt these models to pure NLG and MT+NLG tasks by fine-tuning with smaller amounts of domain-specific data. This end-to-end NLG approach, without data selection and planning, outperforms the previous state of the art on the Rotowire NLG task. We participated to the "Document Generation and Translation" task at WNGT 2019, and ranked first in all tracks.