 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Document-level Machine Translation: Methods and Evaluation
Paper and Code
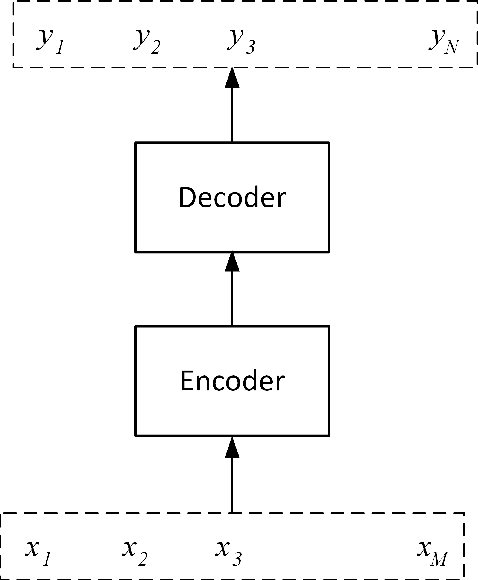
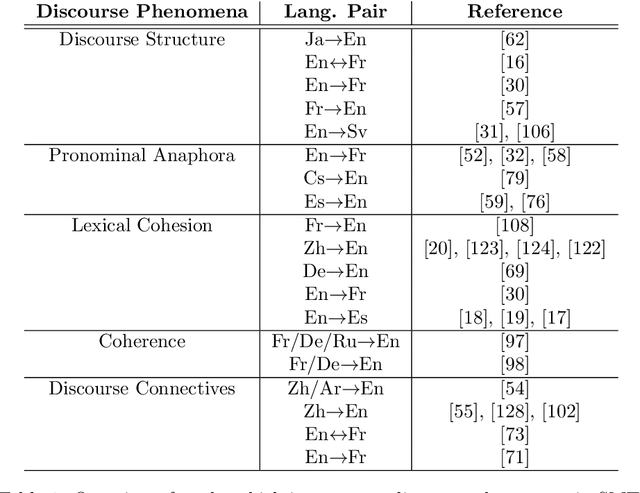
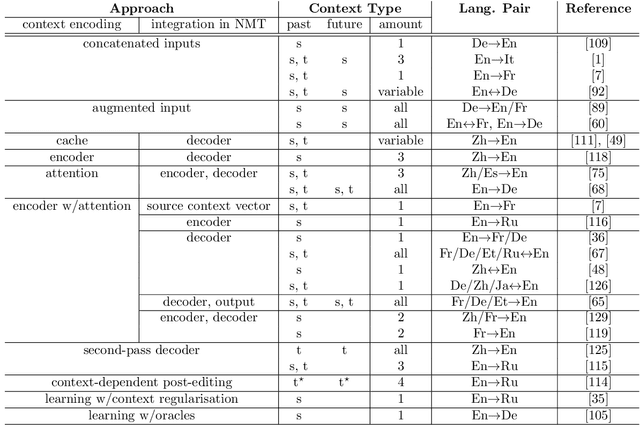
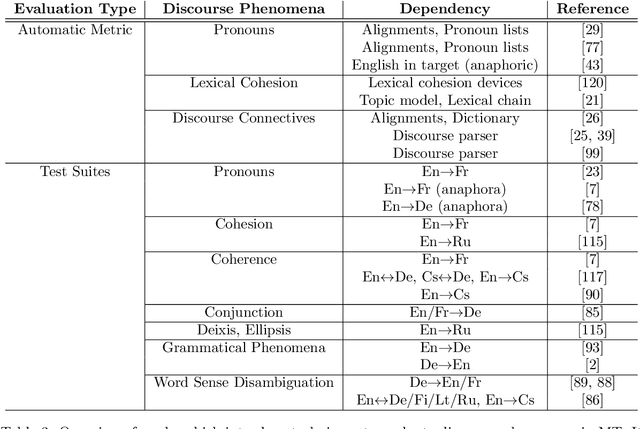
Machine translation (MT) is an important task in natural language processing (NLP) as it automates the translation process and reduces the reliance on human translators. With the advent of neural networks, the translation quality surpasses that of the translations obtained using statistical techniques. Up until three years ago, all neural translation models translated sentences independently, without incorporating any extra-sentential information. The aim of this paper is to highlight the major works that have been undertaken in the space of document-level machine translation before and after the neural revolution so that researchers can recognise where we started from and which direction we are heading in. When talking about the literature in statistical machine translation (SMT), we focus on works which have tried to improve the translation of specific discourse phenomena, while in neural machine translation (NMT), we focus on works which use the wider context explicitly. In addition to this, we also cover the evaluation strategies that have been introduced to account for the improvements in this domain.