 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning Flowchart into Dialog: Plan-based Data Augmentation for Low-Resource Flowchart-grounded Troubleshooting Dialogs
May 10, 2023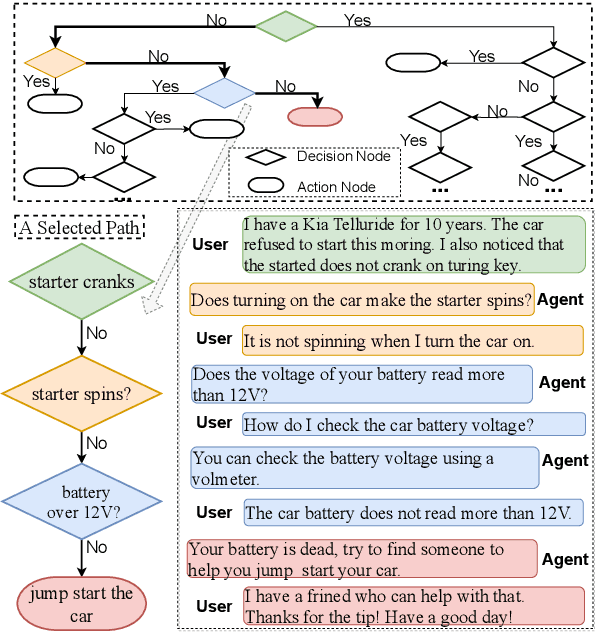
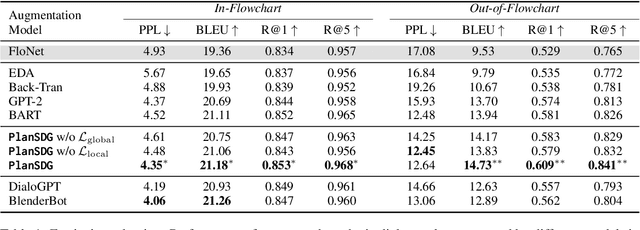
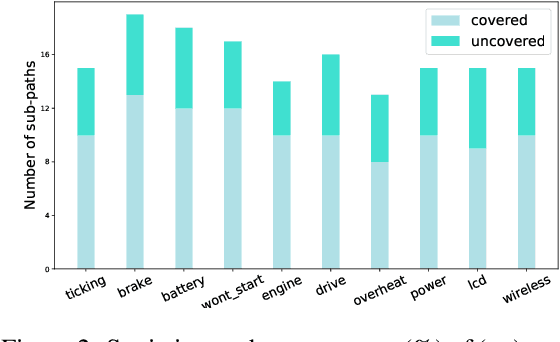

Flowchart-grounded troubleshooting dialogue (FTD) systems, which follow the instructions of a flowchart to diagnose users' problems in specific domains (eg., vehicle, laptop), have been gaining research interest in recent years. However, collecting sufficient dialogues that are naturally grounded on flowcharts is costly, thus FTD systems are impeded by scarce training data. To mitigate the data sparsity issue, we propose a plan-based data augmentation (PlanDA) approach that generates diverse synthetic dialog data at scale by transforming concise flowchart into dialogues. Specifically, its generative model employs a variational-base framework with a hierarchical planning strategy that includes global and local latent planning variables. Experiments on the FloDial dataset show that synthetic dialogue produced by PlanDA improves the performance of downstream tasks, including flowchart path retrieval and response generation, in particular on the Out-of-Flowchart settings. In addition, further analysis demonstrate the quality of synthetic data generated by PlanDA in paths that are covered by current sample dialogues and paths that are not covered.
Contextual Neural Machine Translation Improves Translation of Cataphoric Pronouns
Apr 28, 2020
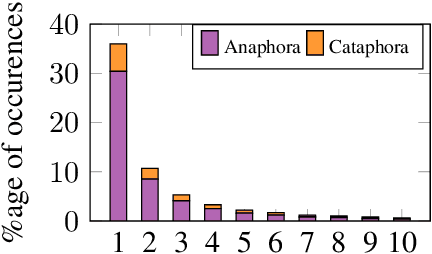
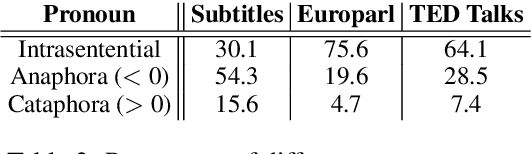
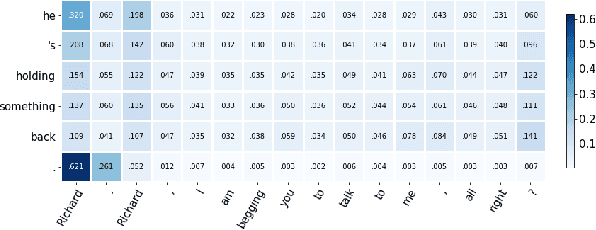
The advent of context-aware NMT has resulted in promising improvements in the overall translation quality and specifically in the translation of discourse phenomena such as pronouns. Previous works have mainly focused on the use of past sentences as context with a focus on anaphora translation. In this work, we investigate the effect of future sentences as context by comparing the performance of a contextual NMT model trained with the future context to the one trained with the past context. Our experiments and evaluation, using generic and pronoun-focused automatic metrics, show that the use of future context not only achieves significant improvements over the context-agnostic Transformer, but also demonstrates comparable and in some cases improved performance over its counterpart trained on past context. We also perform an evaluation on a targeted cataphora test suite and report significant gains over the context-agnostic Transformer in terms of BLEU.
A Survey on Document-level Machine Translation: Methods and Evaluation
Dec 18, 2019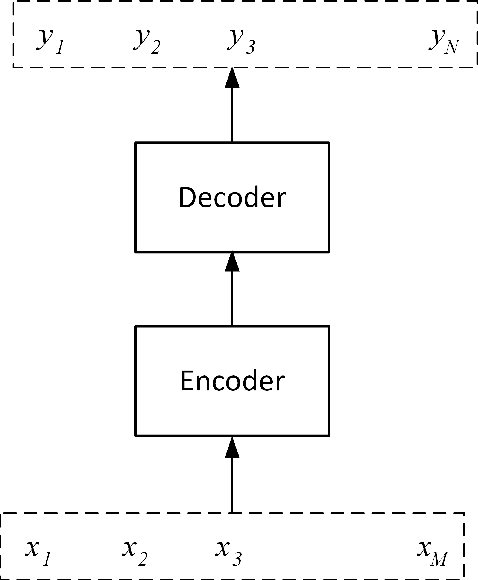
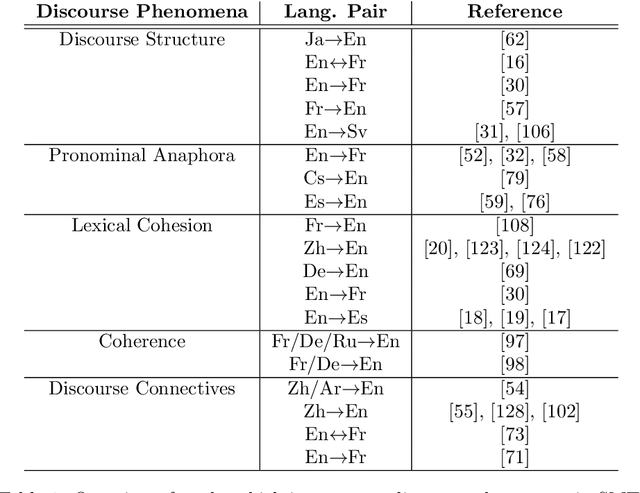
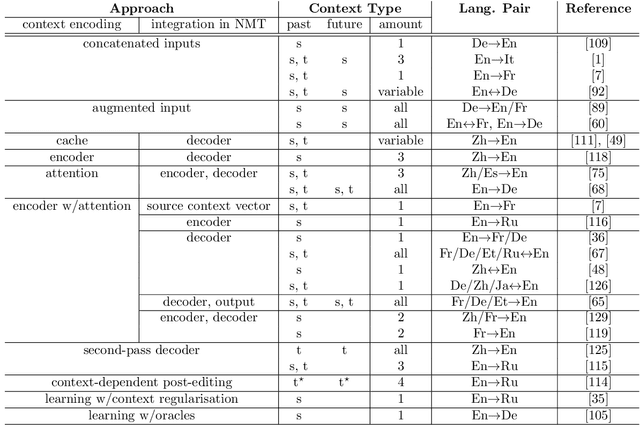
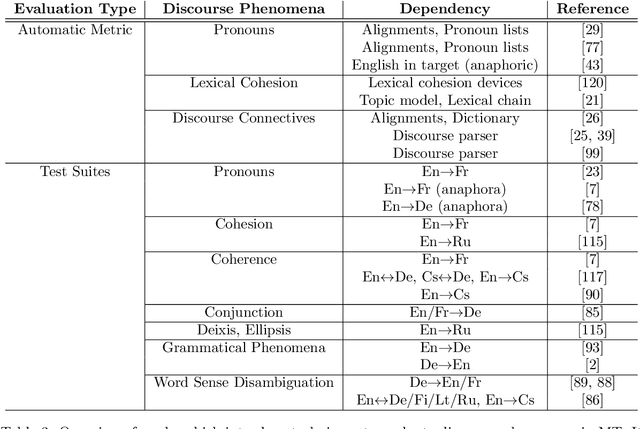
Machine translation (MT) is an important task in natural language processing (NLP) as it automates the translation process and reduces the reliance on human translators. With the advent of neural networks, the translation quality surpasses that of the translations obtained using statistical techniques. Up until three years ago, all neural translation models translated sentences independently, without incorporating any extra-sentential information. The aim of this paper is to highlight the major works that have been undertaken in the space of document-level machine translation before and after the neural revolution so that researchers can recognise where we started from and which direction we are heading in. When talking about the literature in statistical machine translation (SMT), we focus on works which have tried to improve the translation of specific discourse phenomena, while in neural machine translation (NMT), we focus on works which use the wider context explicitly. In addition to this, we also cover the evaluation strategies that have been introduced to account for the improvements in this domain.
Selective Attention for Context-aware Neural Machine Translation
Mar 21, 2019

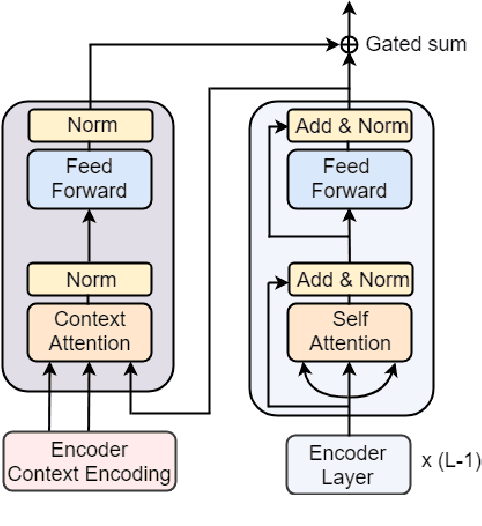
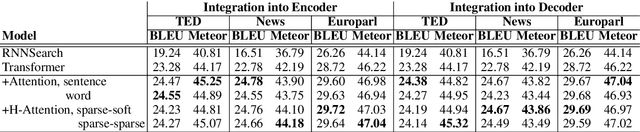
Despite the progress made in sentence-level NMT, current systems still fall short at achieving fluent, good quality translation for a full document. Recent works in context-aware NMT consider only a few previous sentences as context and may not scale to entire documents. To this end, we propose a novel and scalable top-down approach to hierarchical attention for context-aware NMT which uses sparse attention to selectively focus on relevant sentences in the document context and then attends to key words in those sentences. We also propose single-level attention approaches based on sentence or word-level information in the context. The document-level context representation, produced from these attention modules, is integrated into the encoder or decoder of the Transformer model depending on whether we use monolingual or bilingual context. Our experiments and evaluation on English-German datasets in different document MT settings show that our selective attention approach not only significantly outperforms context-agnostic baselines but also surpasses context-aware baselines in most cases.
Contextual Neural Model for Translating Bilingual Multi-Speaker Conversations
Sep 02, 2018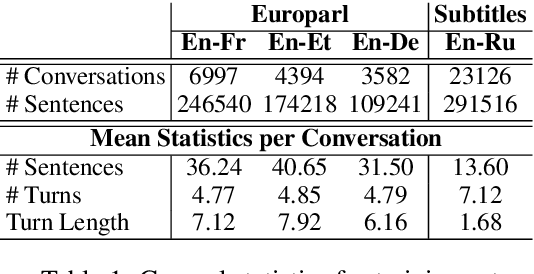
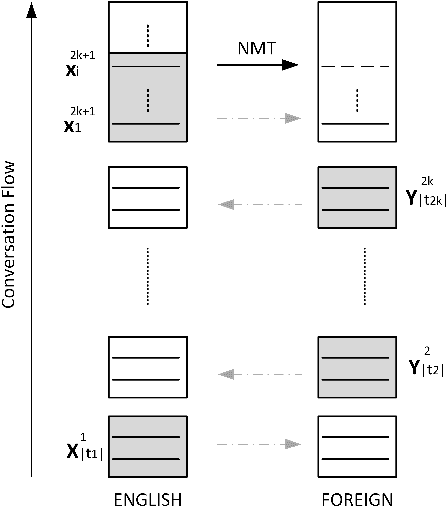
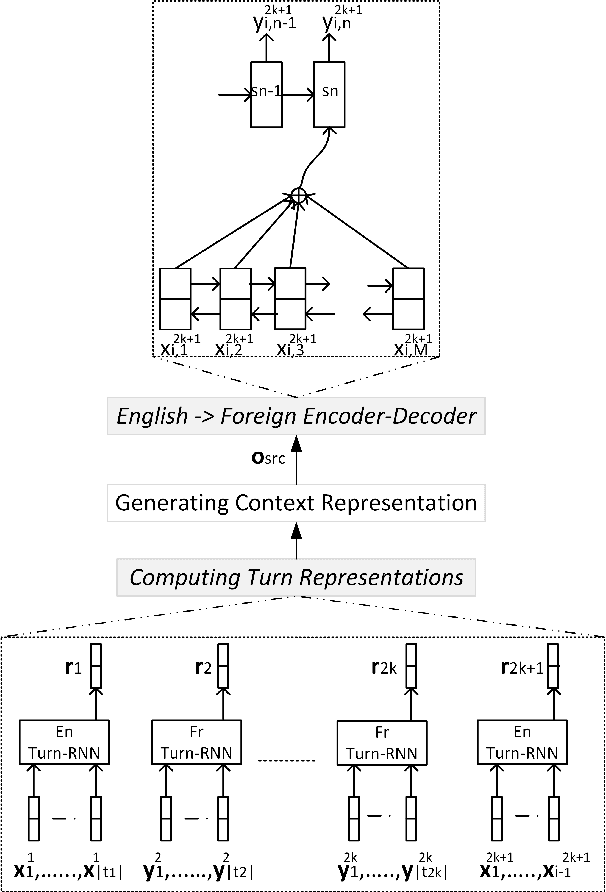
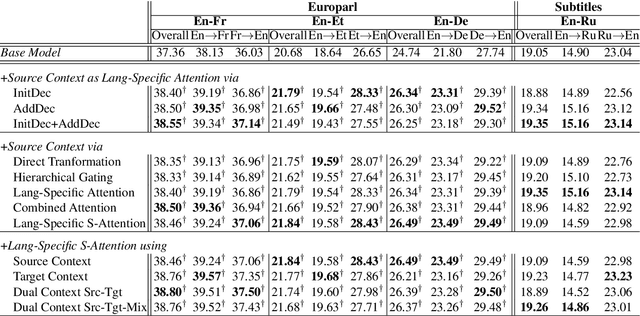
Recent works in neural machine translation have begun to explore document translation. However, translating online multi-speaker conversations is still an open problem. In this work, we propose the task of translating Bilingual Multi-Speaker Conversations, and explore neural architectures which exploit both source and target-side conversation histories for this task. To initiate an evaluation for this task, we introduce datasets extracted from Europarl v7 and OpenSubtitles2016. Our experiments on four language-pairs confirm the significance of leveraging conversation history, both in terms of BLEU and manual evaluation.
Document Context Neural Machine Translation with Memory Networks
May 16, 2018
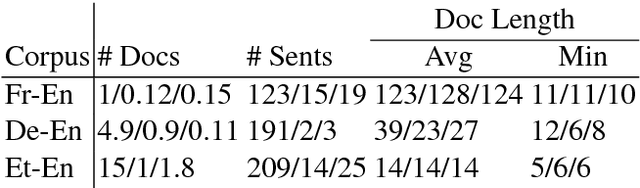
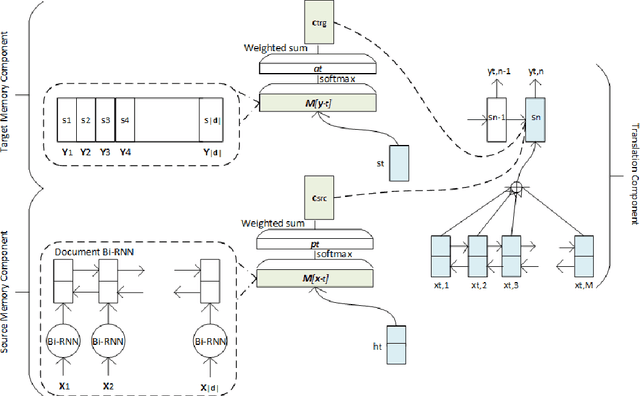
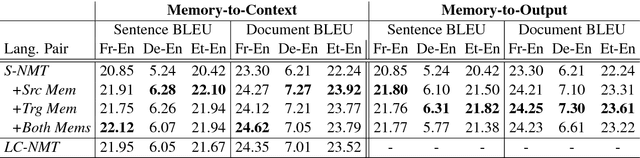
We present a document-level neural machine translation model which takes both source and target document context into account using memory networks. We model the problem as a structured prediction problem with interdependencies among the observed and hidden variables, i.e., the source sentences and their unobserved target translations in the document. The resulting structured prediction problem is tackled with a neural translation model equipped with two memory components, one each for the source and target side, to capture the documental interdependencies. We train the model end-to-end, and propose an iterative decoding algorithm based on block coordinate descent. Experimental results of English translations from French, German, and Estonian documents show that our model is effective in exploiting both source and target document context, and statistically significantly outperforms the previous work in terms of BLEU and METEOR.