 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpoken Dialogue System for Medical Prescription Acquisition on Smartphone: Development, Corpus and Evaluation
Nov 06, 2023


Hospital information systems (HIS) have become an essential part of healthcare institutions and now incorporate prescribing support software. Prescription support software allows for structured information capture, which improves the safety, appropriateness and efficiency of prescriptions and reduces the number of adverse drug events (ADEs). However, such a system increases the amount of time physicians spend at a computer entering information instead of providing medical care. In addition, any new visiting clinician must learn to manage complex interfaces since each HIS has its own interfaces. In this paper, we present a natural language interface for e-prescribing software in the form of a spoken dialogue system accessible on a smartphone. This system allows prescribers to record their prescriptions verbally, a form of interaction closer to their usual practice. The system extracts the formal representation of the prescription ready to be checked by the prescribing software and uses the dialogue to request mandatory information, correct errors or warn of particular situations. Since, to the best of our knowledge, there is no existing voice-based prescription dialogue system, we present the system developed in a low-resource environment, focusing on dialogue modeling, semantic extraction and data augmentation. The system was evaluated in the wild with 55 participants. This evaluation showed that our system has an average prescription time of 66.15 seconds for physicians and 35.64 seconds for other experts, and a task success rate of 76\% for physicians and 72\% for other experts. All evaluation data were recorded and annotated to form PxCorpus, the first spoken drug prescription corpus that has been made fully available to the community (\url{https://doi.org/10.5281/zenodo.6524162}).
A Spoken Drug Prescription Dataset in French for Spoken Language Understanding
Jul 17, 2022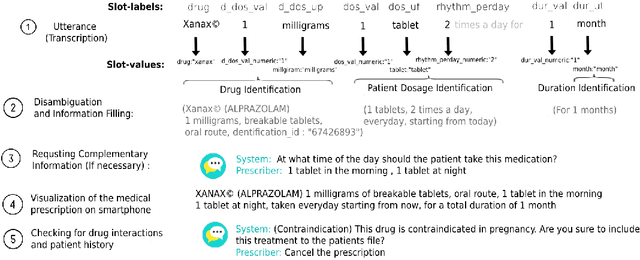
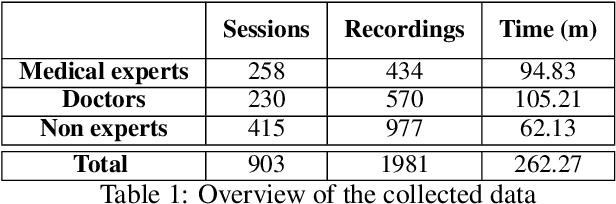


Spoken medical dialogue systems are increasingly attracting interest to enhance access to healthcare services and improve quality and traceability of patient care. In this paper, we focus on medical drug prescriptions acquired on smartphones through spoken dialogue. Such systems would facilitate the traceability of care and would free clinicians' time. However, there is a lack of speech corpora to develop such systems since most of the related corpora are in text form and in English. To facilitate the research and development of spoken medical dialogue systems, we present, to the best of our knowledge, the first spoken medical drug prescriptions corpus, named PxSLU. It contains 4 hours of transcribed and annotated dialogues of drug prescriptions in French acquired through an experiment with 55 participants experts and non-experts in prescriptions. We also present some experiments that demonstrate the interest of this corpus for the evaluation and development of medical dialogue systems.
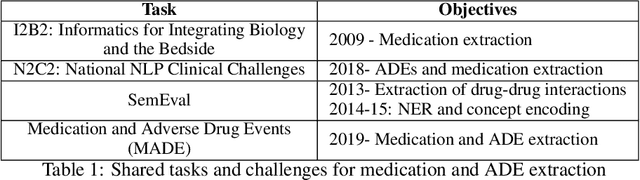
Neural Medication Extraction: A Comparison of Recent Models in Supervised and Semi-supervised Learning Settings
Oct 19, 2021

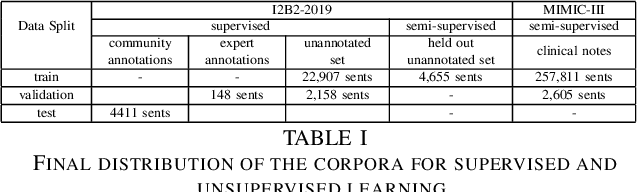
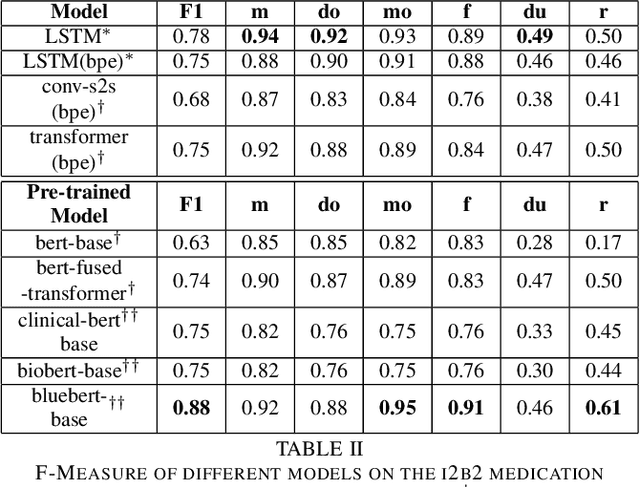
Drug prescriptions are essential information that must be encoded in electronic medical records. However, much of this information is hidden within free-text reports. This is why the medication extraction task has emerged. To date, most of the research effort has focused on small amount of data and has only recently considered deep learning methods. In this paper, we present an independent and comprehensive evaluation of state-of-the-art neural architectures on the I2B2 medical prescription extraction task both in the supervised and semi-supervised settings. The study shows the very competitive performance of simple DNN models on the task as well as the high interest of pre-trained models. Adapting the latter models on the I2B2 dataset enables to push medication extraction performances above the state-of-the-art. Finally, the study also confirms that semi-supervised techniques are promising to leverage large amounts of unlabeled data in particular in low resource setting when labeled data is too costly to acquire.
End-to-End Automatic Speech Translation of Audiobooks
Feb 12, 2018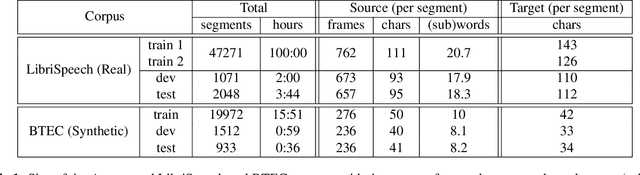
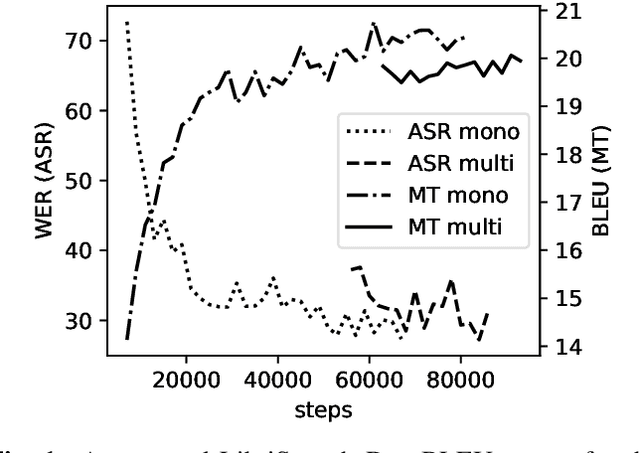
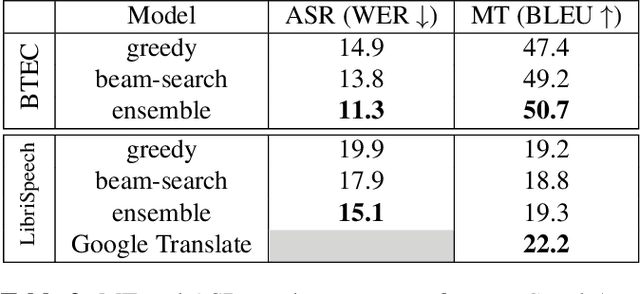

We investigate end-to-end speech-to-text translation on a corpus of audiobooks specifically augmented for this task. Previous works investigated the extreme case where source language transcription is not available during learning nor decoding, but we also study a midway case where source language transcription is available at training time only. In this case, a single model is trained to decode source speech into target text in a single pass. Experimental results show that it is possible to train compact and efficient end-to-end speech translation models in this setup. We also distribute the corpus and hope that our speech translation baseline on this corpus will be challenged in the future.
Augmenting Librispeech with French Translations: A Multimodal Corpus for Direct Speech Translation Evaluation
Feb 09, 2018
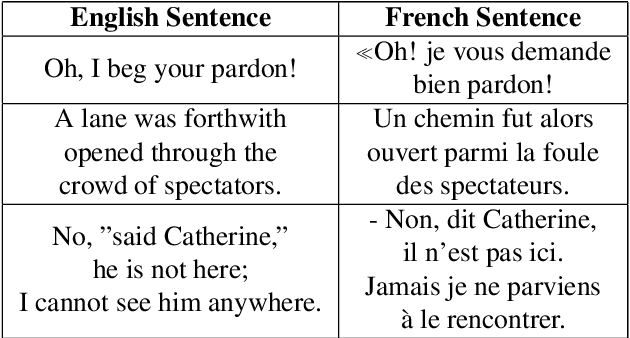
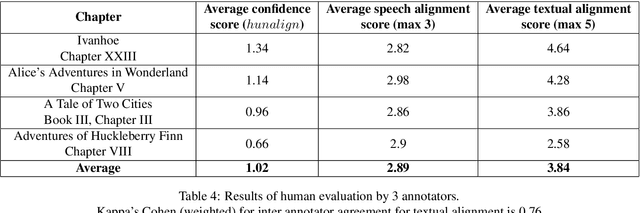
Recent works in spoken language translation (SLT) have attempted to build end-to-end speech-to-text translation without using source language transcription during learning or decoding. However, while large quantities of parallel texts (such as Europarl, OpenSubtitles) are available for training machine translation systems, there are no large (100h) and open source parallel corpora that include speech in a source language aligned to text in a target language. This paper tries to fill this gap by augmenting an existing (monolingual) corpus: LibriSpeech. This corpus, used for automatic speech recognition, is derived from read audiobooks from the LibriVox project, and has been carefully segmented and aligned. After gathering French e-books corresponding to the English audio-books from LibriSpeech, we align speech segments at the sentence level with their respective translations and obtain 236h of usable parallel data. This paper presents the details of the processing as well as a manual evaluation conducted on a small subset of the corpus. This evaluation shows that the automatic alignments scores are reasonably correlated with the human judgments of the bilingual alignment quality. We believe that this corpus (which is made available online) is useful for replicable experiments in direct speech translation or more general spoken language translation experiments.