 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Medication Extraction: A Comparison of Recent Models in Supervised and Semi-supervised Learning Settings
Paper and Code


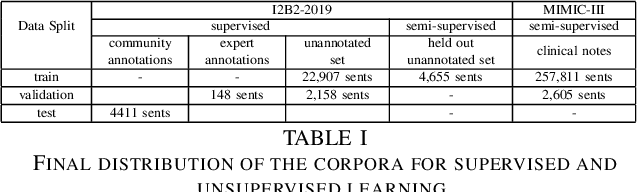
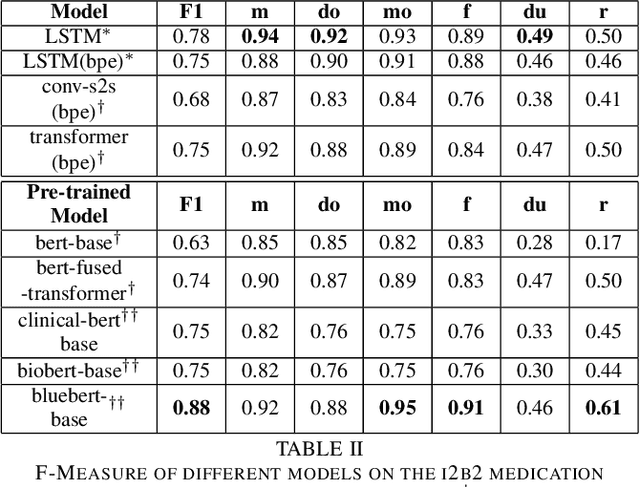
Drug prescriptions are essential information that must be encoded in electronic medical records. However, much of this information is hidden within free-text reports. This is why the medication extraction task has emerged. To date, most of the research effort has focused on small amount of data and has only recently considered deep learning methods. In this paper, we present an independent and comprehensive evaluation of state-of-the-art neural architectures on the I2B2 medical prescription extraction task both in the supervised and semi-supervised settings. The study shows the very competitive performance of simple DNN models on the task as well as the high interest of pre-trained models. Adapting the latter models on the I2B2 dataset enables to push medication extraction performances above the state-of-the-art. Finally, the study also confirms that semi-supervised techniques are promising to leverage large amounts of unlabeled data in particular in low resource setting when labeled data is too costly to acquire.