 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptative Bilingual Aligning Using Multilingual Sentence Embedding
Mar 18, 2024In this paper, we present an adaptive bitextual alignment system called AIlign. This aligner relies on sentence embeddings to extract reliable anchor points that can guide the alignment path, even for texts whose parallelism is fragmentary and not strictly monotonic. In an experiment on several datasets, we show that AIlign achieves results equivalent to the state of the art, with quasi-linear complexity. In addition, AIlign is able to handle texts whose parallelism and monotonicity properties are only satisfied locally, unlike recent systems such as Vecalign or Bertalign.
Multi-Task Sequence Prediction For Tunisian Arabizi Multi-Level Annotation
Nov 10, 2020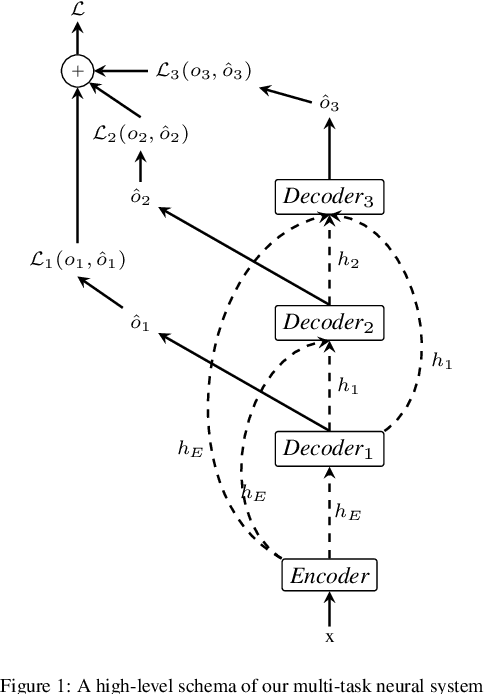


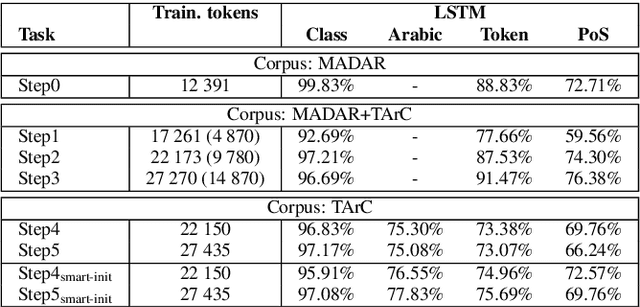
In this paper we propose a multi-task sequence prediction system, based on recurrent neural networks and used to annotate on multiple levels an Arabizi Tunisian corpus. The annotation performed are text classification, tokenization, PoS tagging and encoding of Tunisian Arabizi into CODA* Arabic orthography. The system is learned to predict all the annotation levels in cascade, starting from Arabizi input. We evaluate the system on the TIGER German corpus, suitably converting data to have a multi-task problem, in order to show the effectiveness of our neural architecture. We show also how we used the system in order to annotate a Tunisian Arabizi corpus, which has been afterwards manually corrected and used to further evaluate sequence models on Tunisian data. Our system is developed for the Fairseq framework, which allows for a fast and easy use for any other sequence prediction problem.
Augmenting Librispeech with French Translations: A Multimodal Corpus for Direct Speech Translation Evaluation
Feb 09, 2018
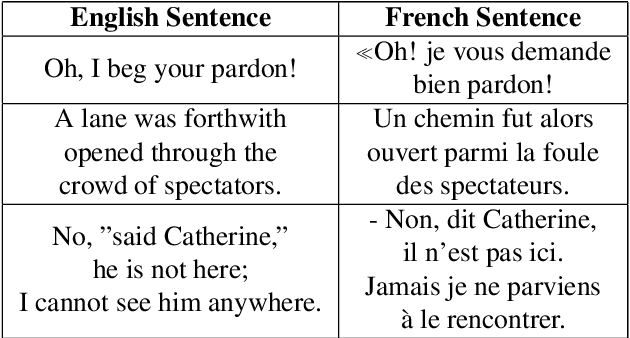
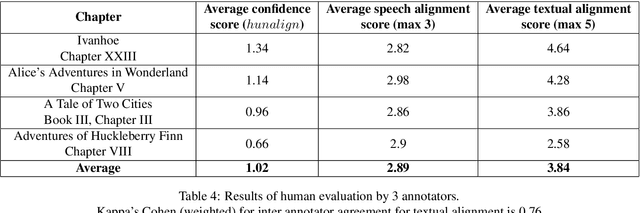
Recent works in spoken language translation (SLT) have attempted to build end-to-end speech-to-text translation without using source language transcription during learning or decoding. However, while large quantities of parallel texts (such as Europarl, OpenSubtitles) are available for training machine translation systems, there are no large (100h) and open source parallel corpora that include speech in a source language aligned to text in a target language. This paper tries to fill this gap by augmenting an existing (monolingual) corpus: LibriSpeech. This corpus, used for automatic speech recognition, is derived from read audiobooks from the LibriVox project, and has been carefully segmented and aligned. After gathering French e-books corresponding to the English audio-books from LibriSpeech, we align speech segments at the sentence level with their respective translations and obtain 236h of usable parallel data. This paper presents the details of the processing as well as a manual evaluation conducted on a small subset of the corpus. This evaluation shows that the automatic alignments scores are reasonably correlated with the human judgments of the bilingual alignment quality. We believe that this corpus (which is made available online) is useful for replicable experiments in direct speech translation or more general spoken language translation experiments.
NLP and CALL: integration is working
Feb 20, 2013

In the first part of this article, we explore the background of computer-assisted learning from its beginnings in the early XIXth century and the first teaching machines, founded on theories of learning, at the start of the XXth century. With the arrival of the computer, it became possible to offer language learners different types of language activities such as comprehension tasks, simulations, etc. However, these have limits that cannot be overcome without some contribution from the field of natural language processing (NLP). In what follows, we examine the challenges faced and the issues raised by integrating NLP into CALL. We hope to demonstrate that the key to success in integrating NLP into CALL is to be found in multidisciplinary work between computer experts, linguists, language teachers, didacticians and NLP specialists.