 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multilingual Neural Machine Translation Model for Biomedical Data
Aug 06, 2020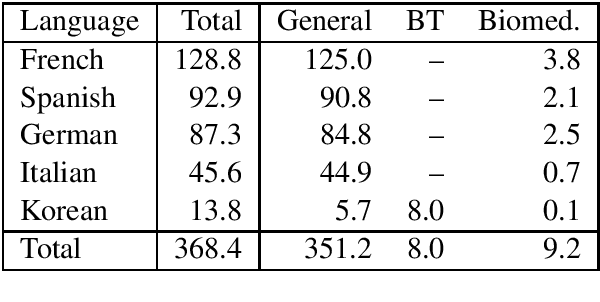

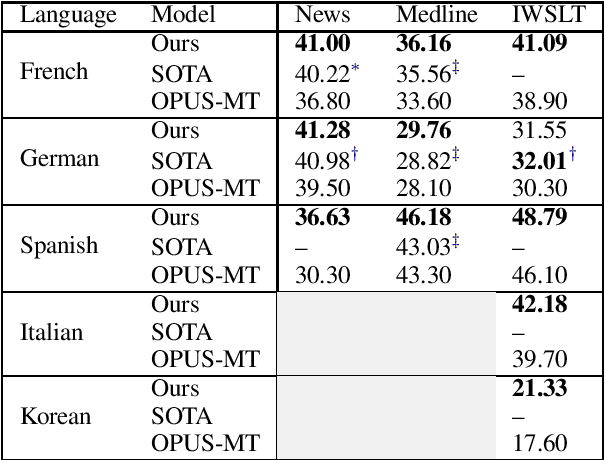
We release a multilingual neural machine translation model, which can be used to translate text in the biomedical domain. The model can translate from 5 languages (French, German, Italian, Korean and Spanish) into English. It is trained with large amounts of generic and biomedical data, using domain tags. Our benchmarks show that it performs near state-of-the-art both on news (generic domain) and biomedical test sets, and that it outperforms the existing publicly released models. We believe that this release will help the large-scale multilingual analysis of the digital content of the COVID-19 crisis and of its effects on society, economy, and healthcare policies. We also release a test set of biomedical text for Korean-English. It consists of 758 sentences from official guidelines and recent papers, all about COVID-19.
Revisiting Round-Trip Translation for Quality Estimation
Apr 29, 2020
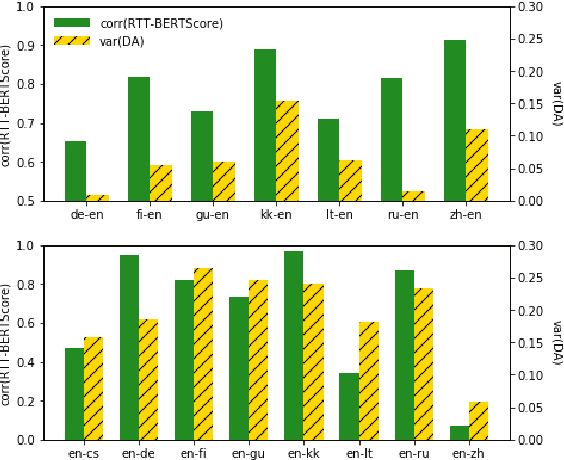
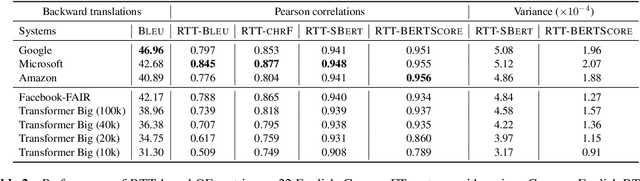
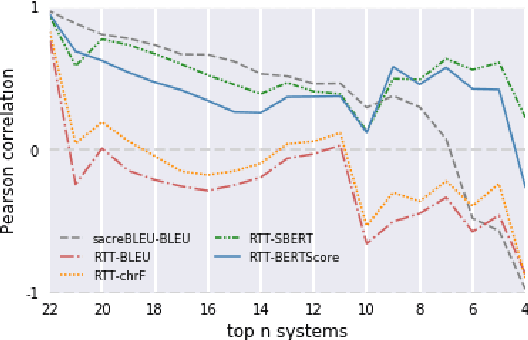
Quality estimation (QE) is the task of automatically evaluating the quality of translations without human-translated references. Calculating BLEU between the input sentence and round-trip translation (RTT) was once considered as a metric for QE, however, it was found to be a poor predictor of translation quality. Recently, various pre-trained language models have made breakthroughs in NLP tasks by providing semantically meaningful word and sentence embeddings. In this paper, we employ semantic embeddings to RTT-based QE. Our method achieves the highest correlations with human judgments, compared to previous WMT 2019 quality estimation metric task submissions. While backward translation models can be a drawback when using RTT, we observe that with semantic-level metrics, RTT-based QE is robust to the choice of the backward translation system. Additionally, the proposed method shows consistent performance for both SMT and NMT forward translation systems, implying the method does not penalize a certain type of model.