 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecializing Multi-domain NMT via Penalizing Low Mutual Information
Oct 24, 2022



Multi-domain Neural Machine Translation (NMT) trains a single model with multiple domains. It is appealing because of its efficacy in handling multiple domains within one model. An ideal multi-domain NMT should learn distinctive domain characteristics simultaneously, however, grasping the domain peculiarity is a non-trivial task. In this paper, we investigate domain-specific information through the lens of mutual information (MI) and propose a new objective that penalizes low MI to become higher. Our method achieved the state-of-the-art performance among the current competitive multi-domain NMT models. Also, we empirically show our objective promotes low MI to be higher resulting in domain-specialized multi-domain NMT.
DaLC: Domain Adaptation Learning Curve Prediction for Neural Machine Translation
Apr 20, 2022



Domain Adaptation (DA) of Neural Machine Translation (NMT) model often relies on a pre-trained general NMT model which is adapted to the new domain on a sample of in-domain parallel data. Without parallel data, there is no way to estimate the potential benefit of DA, nor the amount of parallel samples it would require. It is however a desirable functionality that could help MT practitioners to make an informed decision before investing resources in dataset creation. We propose a Domain adaptation Learning Curve prediction (DaLC) model that predicts prospective DA performance based on in-domain monolingual samples in the source language. Our model relies on the NMT encoder representations combined with various instance and corpus-level features. We demonstrate that instance-level is better able to distinguish between different domains compared to corpus-level frameworks proposed in previous studies. Finally, we perform in-depth analyses of the results highlighting the limitations of our approach, and provide directions for future research.
Kosp2e: Korean Speech to English Translation Corpus
Jul 06, 2021Most speech-to-text (S2T) translation studies use English speech as a source, which makes it difficult for non-English speakers to take advantage of the S2T technologies. For some languages, this problem was tackled through corpus construction, but the farther linguistically from English or the more under-resourced, this deficiency and underrepresentedness becomes more significant. In this paper, we introduce kosp2e (read as `kospi'), a corpus that allows Korean speech to be translated into English text in an end-to-end manner. We adopt open license speech recognition corpus, translation corpus, and spoken language corpora to make our dataset freely available to the public, and check the performance through the pipeline and training-based approaches. Using pipeline and various end-to-end schemes, we obtain the highest BLEU of 21.3 and 18.0 for each based on the English hypothesis, validating the feasibility of our data. We plan to supplement annotations for other target languages through community contributions in the future.
Revisiting Round-Trip Translation for Quality Estimation
Apr 29, 2020
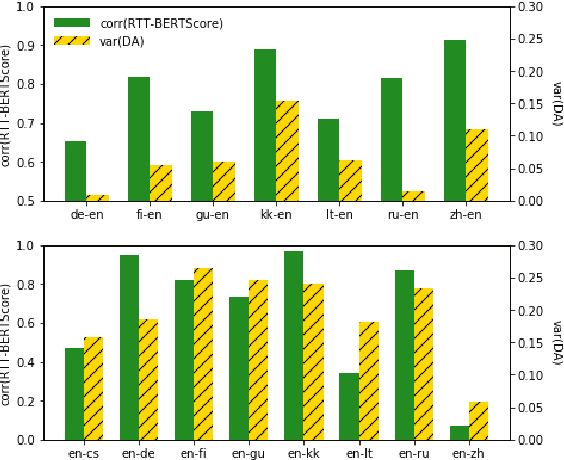
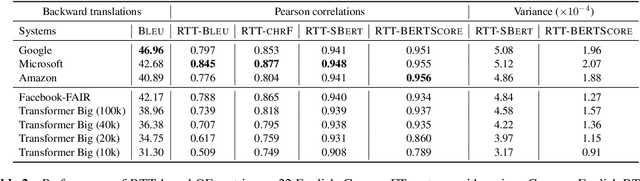
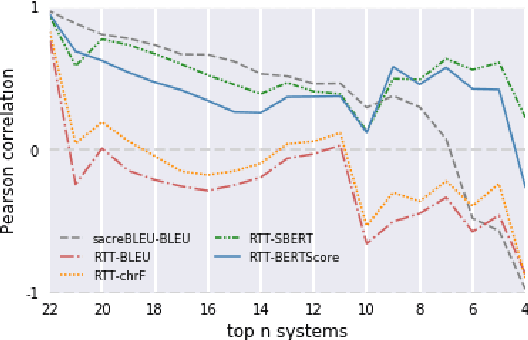
Quality estimation (QE) is the task of automatically evaluating the quality of translations without human-translated references. Calculating BLEU between the input sentence and round-trip translation (RTT) was once considered as a metric for QE, however, it was found to be a poor predictor of translation quality. Recently, various pre-trained language models have made breakthroughs in NLP tasks by providing semantically meaningful word and sentence embeddings. In this paper, we employ semantic embeddings to RTT-based QE. Our method achieves the highest correlations with human judgments, compared to previous WMT 2019 quality estimation metric task submissions. While backward translation models can be a drawback when using RTT, we observe that with semantic-level metrics, RTT-based QE is robust to the choice of the backward translation system. Additionally, the proposed method shows consistent performance for both SMT and NMT forward translation systems, implying the method does not penalize a certain type of model.