 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaLC: Domain Adaptation Learning Curve Prediction for Neural Machine Translation
Paper and Code
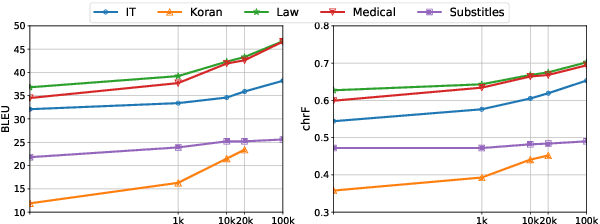



Domain Adaptation (DA) of Neural Machine Translation (NMT) model often relies on a pre-trained general NMT model which is adapted to the new domain on a sample of in-domain parallel data. Without parallel data, there is no way to estimate the potential benefit of DA, nor the amount of parallel samples it would require. It is however a desirable functionality that could help MT practitioners to make an informed decision before investing resources in dataset creation. We propose a Domain adaptation Learning Curve prediction (DaLC) model that predicts prospective DA performance based on in-domain monolingual samples in the source language. Our model relies on the NMT encoder representations combined with various instance and corpus-level features. We demonstrate that instance-level is better able to distinguish between different domains compared to corpus-level frameworks proposed in previous studies. Finally, we perform in-depth analyses of the results highlighting the limitations of our approach, and provide directions for future research.