 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Formality-Aware Japanese Sentence Representation
Jan 17, 2023



While the way intermediate representations are generated in encoder-decoder sequence-to-sequence models typically allow them to preserve the semantics of the input sentence, input features such as formality might be left out. On the other hand, downstream tasks such as translation would benefit from working with a sentence representation that preserves formality in addition to semantics, so as to generate sentences with the appropriate level of social formality -- the difference between speaking to a friend versus speaking with a supervisor. We propose a sequence-to-sequence method for learning a formality-aware representation for Japanese sentences, where sentence generation is conditioned on both the original representation of the input sentence, and a side constraint which guides the sentence representation towards preserving formality information. Additionally, we propose augmenting the sentence representation with a learned representation of formality which facilitates the extraction of formality in downstream tasks. We address the lack of formality-annotated parallel data by adapting previous works on procedural formality classification of Japanese sentences. Experimental results suggest that our techniques not only helps the decoder recover the formality of the input sentence, but also slightly improves the preservation of input sentence semantics.
Mulco: Recognizing Chinese Nested Named Entities Through Multiple Scopes
Nov 20, 2022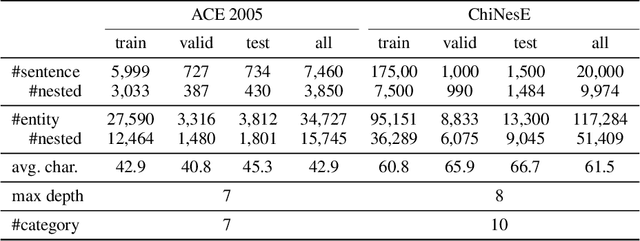
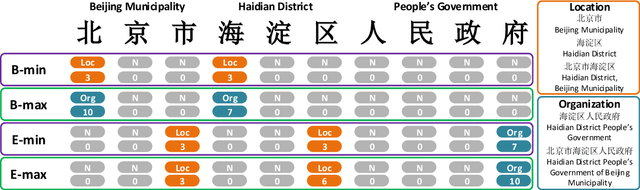
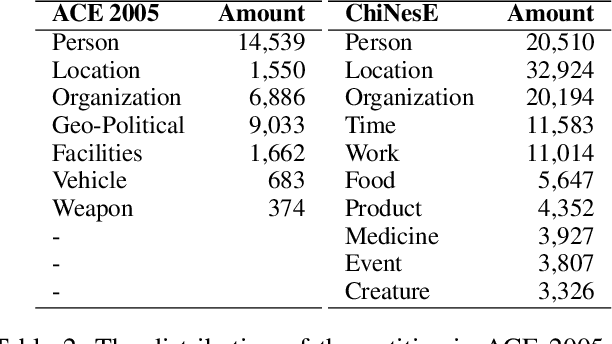
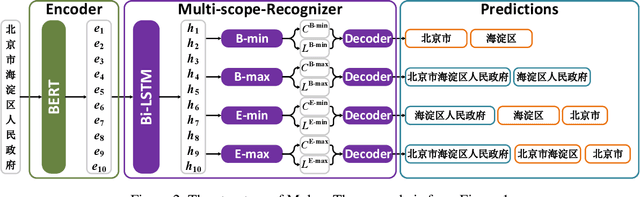
Nested Named Entity Recognition (NNER) has been a long-term challenge to researchers as an important sub-area of Named Entity Recognition. NNER is where one entity may be part of a longer entity, and this may happen on multiple levels, as the term nested suggests. These nested structures make traditional sequence labeling methods unable to properly recognize all entities. While recent researches focus on designing better recognition methods for NNER in a variety of languages, the Chinese NNER (CNNER) still lacks attention, where a free-for-access, CNNER-specialized benchmark is absent. In this paper, we aim to solve CNNER problems by providing a Chinese dataset and a learning-based model to tackle the issue. To facilitate the research on this task, we release ChiNesE, a CNNER dataset with 20,000 sentences sampled from online passages of multiple domains, containing 117,284 entities failing in 10 categories, where 43.8 percent of those entities are nested. Based on ChiNesE, we propose Mulco, a novel method that can recognize named entities in nested structures through multiple scopes. Each scope use a designed scope-based sequence labeling method, which predicts an anchor and the length of a named entity to recognize it. Experiment results show that Mulco has outperformed several baseline methods with the different recognizing schemes on ChiNesE. We also conduct extensive experiments on ACE2005 Chinese corpus, where Mulco has achieved the best performance compared with the baseline methods.
Trucks Don't Mean Trump: Diagnosing Human Error in Image Analysis
May 15, 2022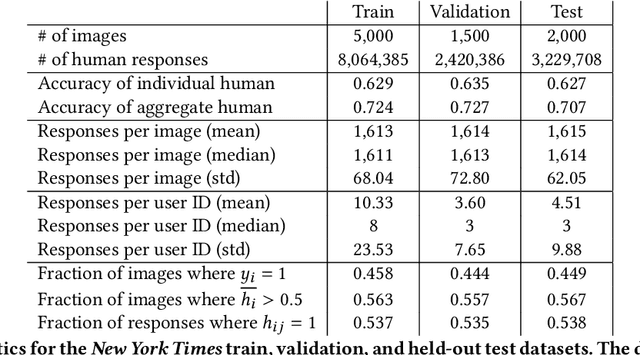
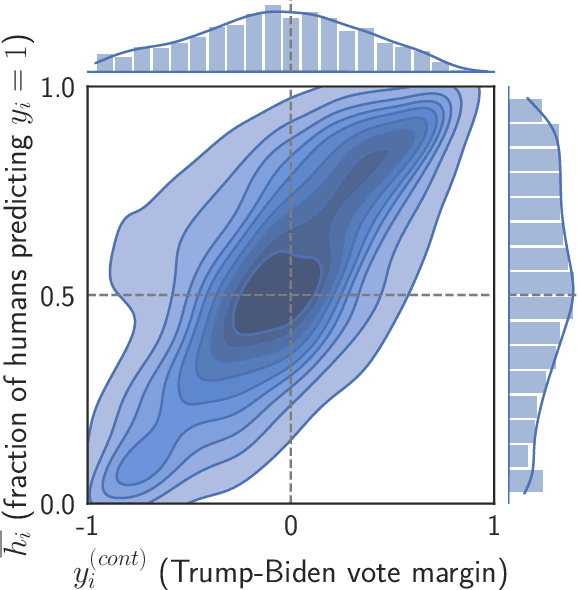
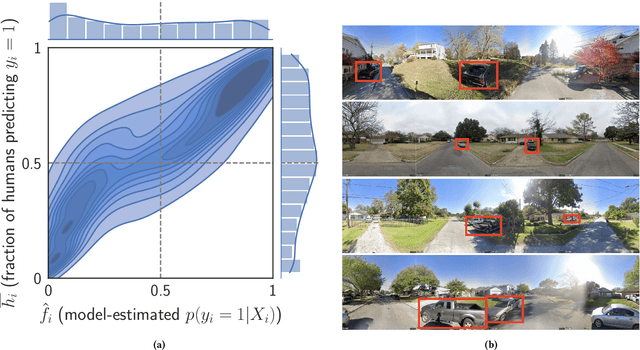
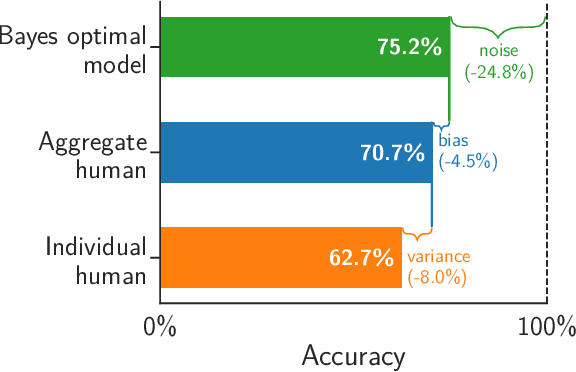
Algorithms provide powerful tools for detecting and dissecting human bias and error. Here, we develop machine learning methods to to analyze how humans err in a particular high-stakes task: image interpretation. We leverage a unique dataset of 16,135,392 human predictions of whether a neighborhood voted for Donald Trump or Joe Biden in the 2020 US election, based on a Google Street View image. We show that by training a machine learning estimator of the Bayes optimal decision for each image, we can provide an actionable decomposition of human error into bias, variance, and noise terms, and further identify specific features (like pickup trucks) which lead humans astray. Our methods can be applied to ensure that human-in-the-loop decision-making is accurate and fair and are also applicable to black-box algorithmic systems.
Generating Lode Runner Levels by Learning Player Paths with LSTMs
Jul 27, 2021


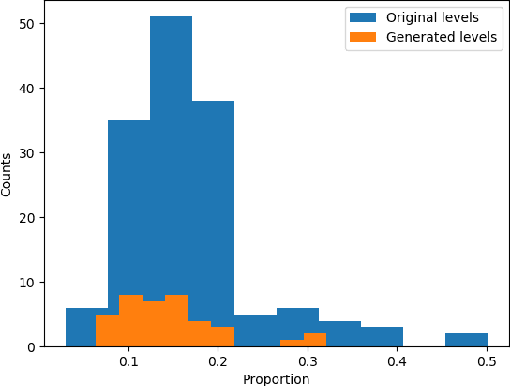
Machine learning has been a popular tool in many different fields, including procedural content generation. However, procedural content generation via machine learning (PCGML) approaches can struggle with controllability and coherence. In this paper, we attempt to address these problems by learning to generate human-like paths, and then generating levels based on these paths. We extract player path data from gameplay video, train an LSTM to generate new paths based on this data, and then generate game levels based on this path data. We demonstrate that our approach leads to more coherent levels for the game Lode Runner in comparison to an existing PCGML approach.
* 7 pages, 6 figures, Workshop on Procedural Content Generation