 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePensieve Discuss: Scalable Small-Group CS Tutoring System with AI
Jul 24, 2024



Small-group tutoring in Computer Science (CS) is effective, but presents the challenge of providing a dedicated tutor for each group and encouraging collaboration among group members at scale. We present Pensieve Discuss, a software platform that integrates synchronous editing for scaffolded programming problems with online human and AI tutors, designed to improve student collaboration and experience during group tutoring sessions. Our semester-long deployment to 800 students in a CS1 course demonstrated consistently high collaboration rates, positive feedback about the AI tutor's helpfulness and correctness, increased satisfaction with the group tutoring experience, and a substantial increase in question volume. The use of our system was preferred over an interface lacking AI tutors and synchronous editing capabilities. Our experiences suggest that small-group tutoring sessions are an important avenue for future research in educational AI.
A Knowledge-Component-Based Methodology for Evaluating AI Assistants
Jun 09, 2024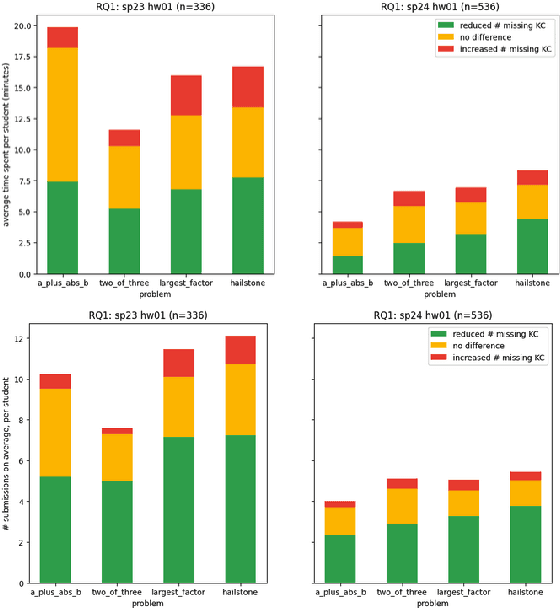
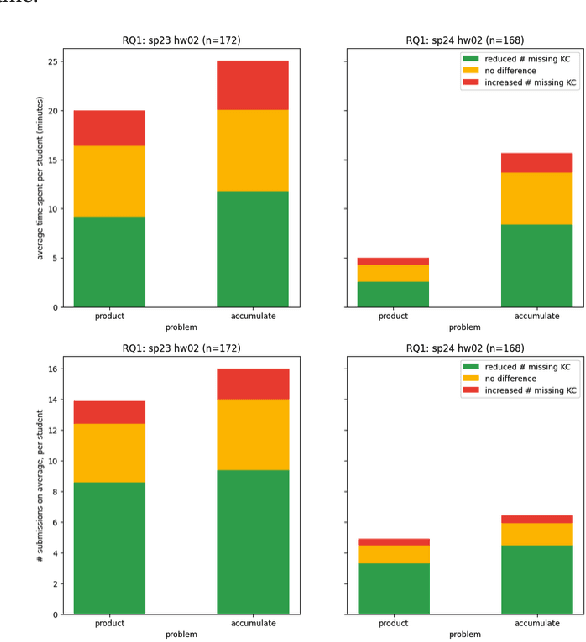
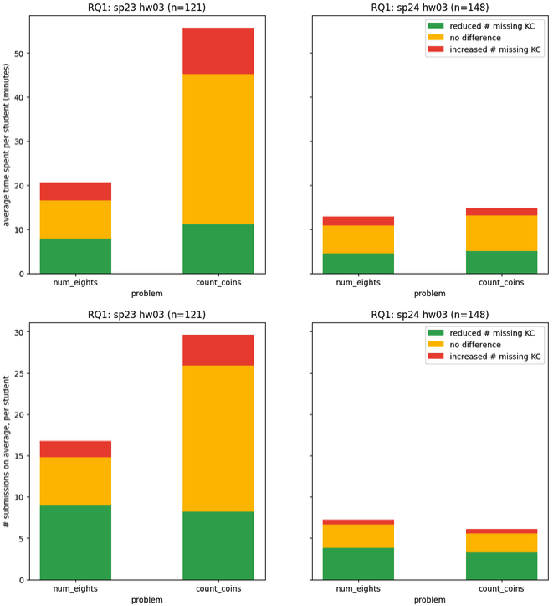
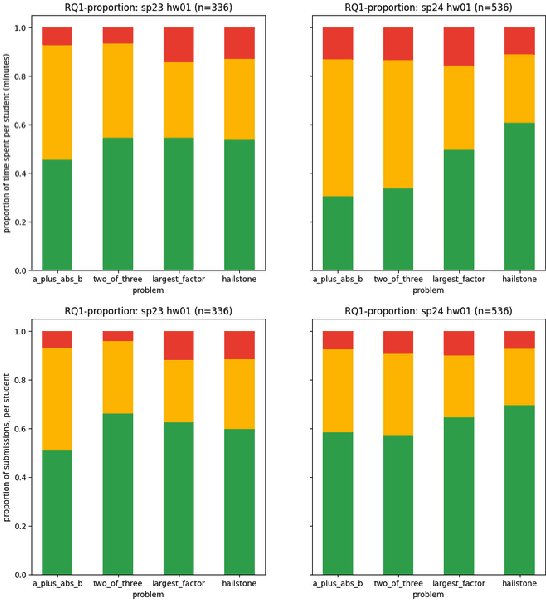
We evaluate an automatic hint generator for CS1 programming assignments powered by GPT-4, a large language model. This system provides natural language guidance about how students can improve their incorrect solutions to short programming exercises. A hint can be requested each time a student fails a test case. Our evaluation addresses three Research Questions: RQ1: Do the hints help students improve their code? RQ2: How effectively do the hints capture problems in student code? RQ3: Are the issues that students resolve the same as the issues addressed in the hints? To address these research questions quantitatively, we identified a set of fine-grained knowledge components and determined which ones apply to each exercise, incorrect solution, and generated hint. Comparing data from two large CS1 offerings, we found that access to the hints helps students to address problems with their code more quickly, that hints are able to consistently capture the most pressing errors in students' code, and that hints that address a few issues at once rather than a single bug are more likely to lead to direct student progress.
Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences
Apr 18, 2024



Due to the cumbersome nature of human evaluation and limitations of code-based evaluation, Large Language Models (LLMs) are increasingly being used to assist humans in evaluating LLM outputs. Yet LLM-generated evaluators simply inherit all the problems of the LLMs they evaluate, requiring further human validation. We present a mixed-initiative approach to ``validate the validators'' -- aligning LLM-generated evaluation functions (be it prompts or code) with human requirements. Our interface, EvalGen, provides automated assistance to users in generating evaluation criteria and implementing assertions. While generating candidate implementations (Python functions, LLM grader prompts), EvalGen asks humans to grade a subset of LLM outputs; this feedback is used to select implementations that better align with user grades. A qualitative study finds overall support for EvalGen but underscores the subjectivity and iterative process of alignment. In particular, we identify a phenomenon we dub \emph{criteria drift}: users need criteria to grade outputs, but grading outputs helps users define criteria. What is more, some criteria appears \emph{dependent} on the specific LLM outputs observed (rather than independent criteria that can be defined \emph{a priori}), raising serious questions for approaches that assume the independence of evaluation from observation of model outputs. We present our interface and implementation details, a comparison of our algorithm with a baseline approach, and implications for the design of future LLM evaluation assistants.
Trucks Don't Mean Trump: Diagnosing Human Error in Image Analysis
May 15, 2022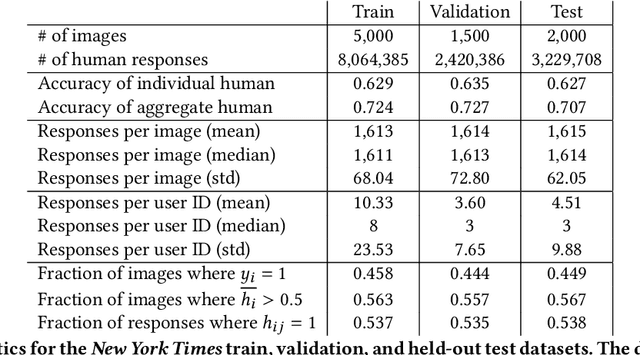
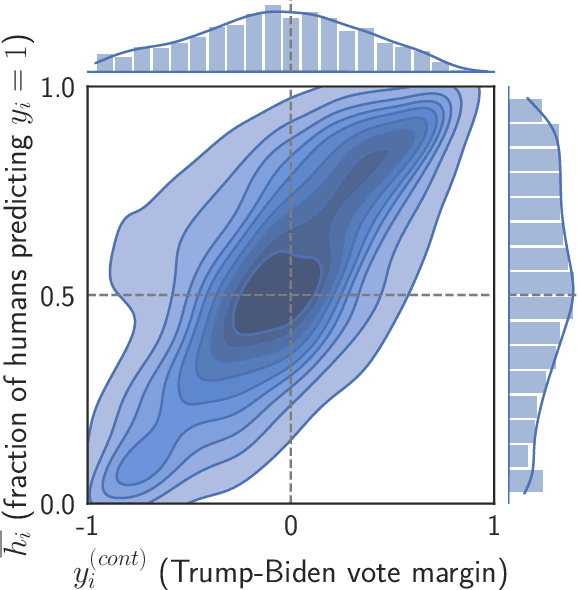
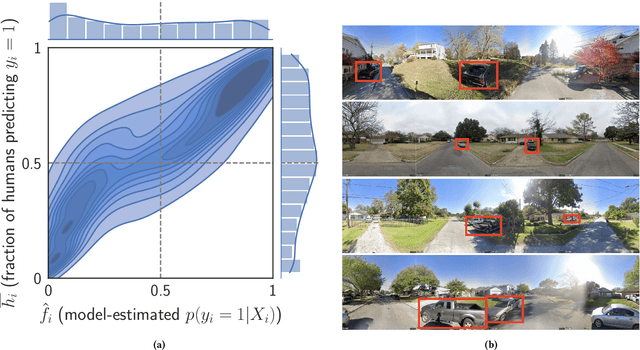
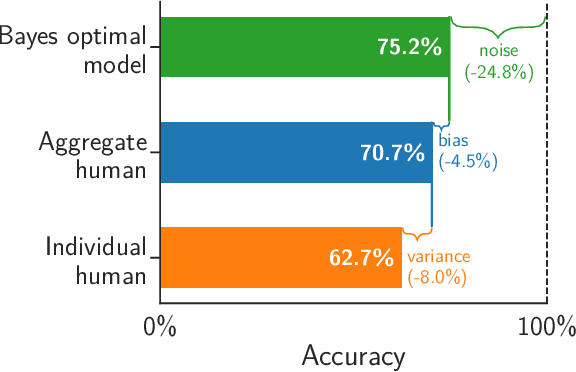
Algorithms provide powerful tools for detecting and dissecting human bias and error. Here, we develop machine learning methods to to analyze how humans err in a particular high-stakes task: image interpretation. We leverage a unique dataset of 16,135,392 human predictions of whether a neighborhood voted for Donald Trump or Joe Biden in the 2020 US election, based on a Google Street View image. We show that by training a machine learning estimator of the Bayes optimal decision for each image, we can provide an actionable decomposition of human error into bias, variance, and noise terms, and further identify specific features (like pickup trucks) which lead humans astray. Our methods can be applied to ensure that human-in-the-loop decision-making is accurate and fair and are also applicable to black-box algorithmic systems.