 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrucks Don't Mean Trump: Diagnosing Human Error in Image Analysis
May 15, 2022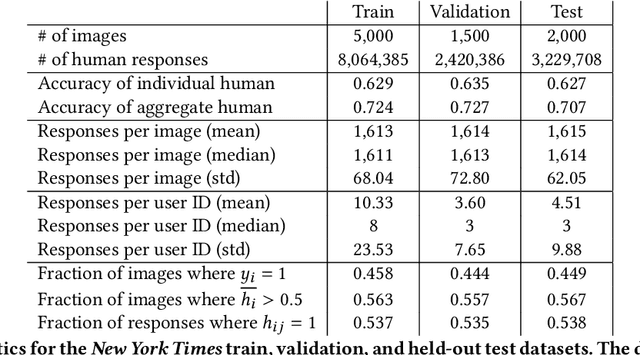
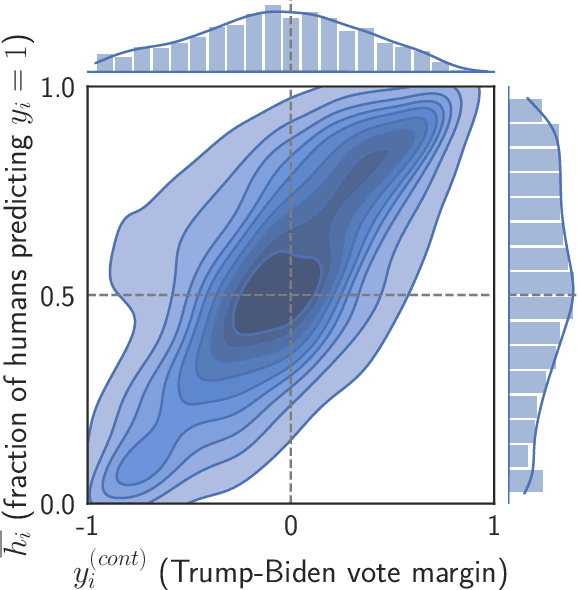
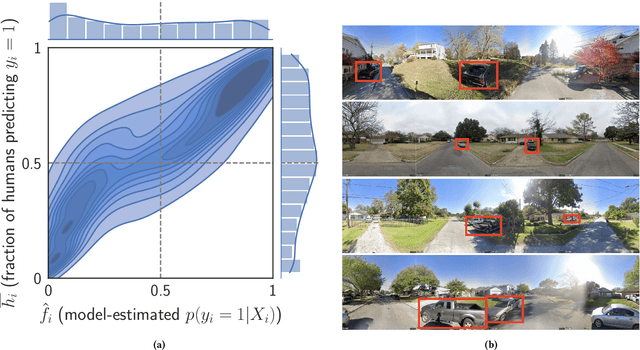
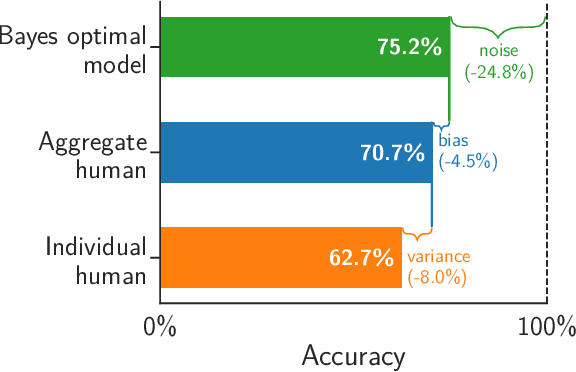
Algorithms provide powerful tools for detecting and dissecting human bias and error. Here, we develop machine learning methods to to analyze how humans err in a particular high-stakes task: image interpretation. We leverage a unique dataset of 16,135,392 human predictions of whether a neighborhood voted for Donald Trump or Joe Biden in the 2020 US election, based on a Google Street View image. We show that by training a machine learning estimator of the Bayes optimal decision for each image, we can provide an actionable decomposition of human error into bias, variance, and noise terms, and further identify specific features (like pickup trucks) which lead humans astray. Our methods can be applied to ensure that human-in-the-loop decision-making is accurate and fair and are also applicable to black-box algorithmic systems.
CheXseg: Combining Expert Annotations with DNN-generated Saliency Maps for X-ray Segmentation
Feb 21, 2021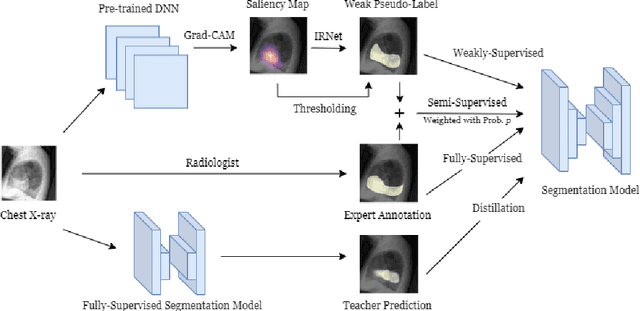
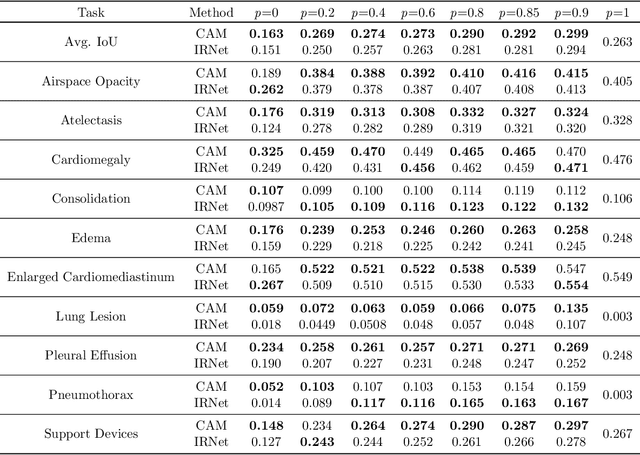
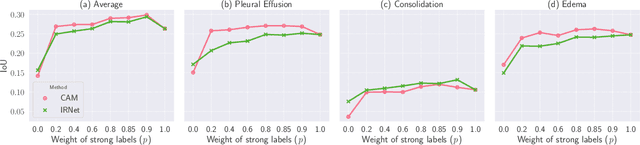
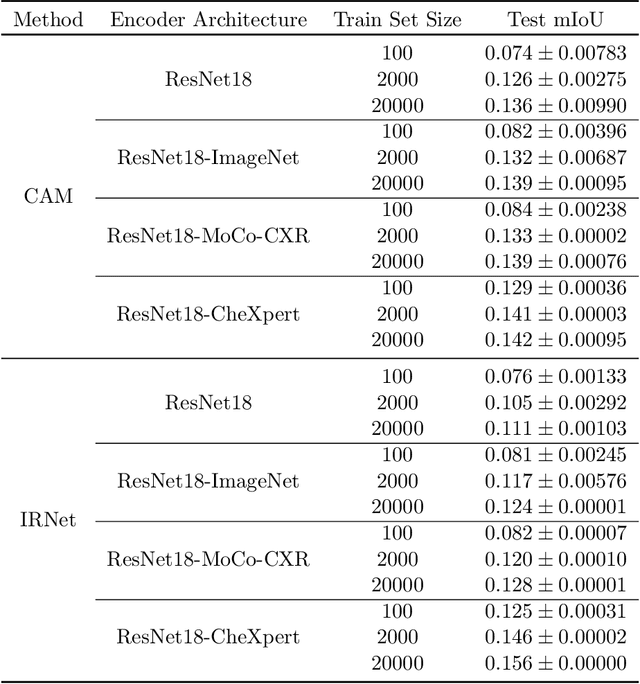
Medical image segmentation models are typically supervised by expert annotations at the pixel-level, which can be expensive to acquire. In this work, we propose a method that combines the high quality of pixel-level expert annotations with the scale of coarse DNN-generated saliency maps for training multi-label semantic segmentation models. We demonstrate the application of our semi-supervised method, which we call CheXseg, on multi-label chest x-ray interpretation. We find that CheXseg improves upon the performance (mIoU) of fully-supervised methods that use only pixel-level expert annotations by 13.4% and weakly-supervised methods that use only DNN-generated saliency maps by 91.2%. Furthermore, we implement a semi-supervised method using knowledge distillation and find that though it is outperformed by CheXseg, it exceeds the performance (mIoU) of the best fully-supervised method by 4.83%. Our best method is able to match radiologist agreement on three out of ten pathologies and reduces the overall performance gap by 71.6% as compared to weakly-supervised methods.
How Not to Give a FLOP: Combining Regularization and Pruning for Efficient Inference
Apr 09, 2020
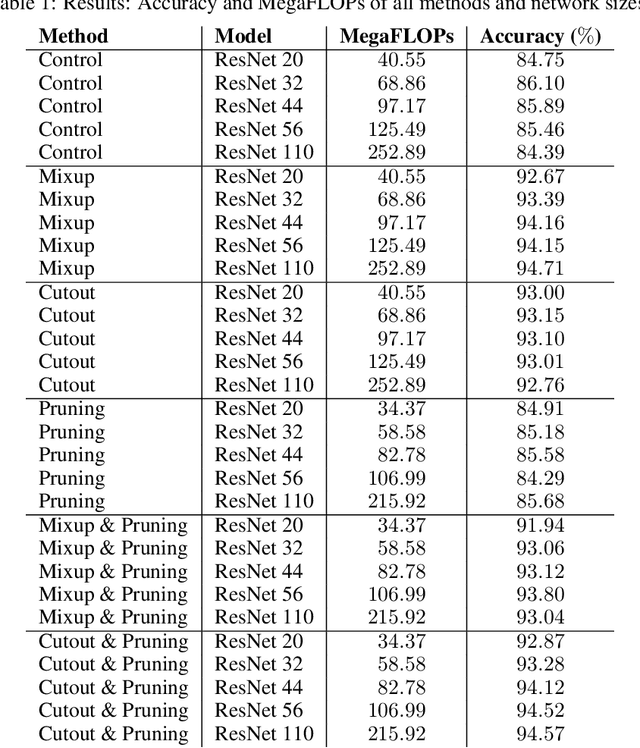

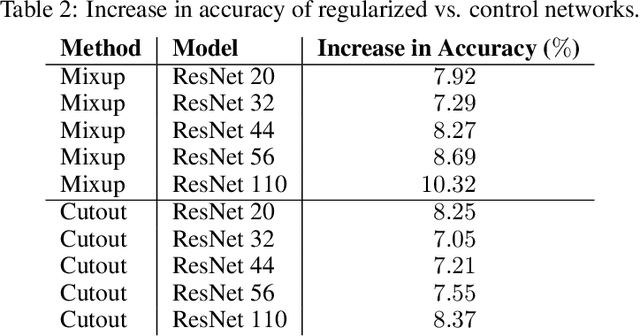
The challenge of speeding up deep learning models during the deployment phase has been a large, expensive bottleneck in the modern tech industry. In this paper, we examine the use of both regularization and pruning for reduced computational complexity and more efficient inference in Deep Neural Networks (DNNs). In particular, we apply mixup and cutout regularizations and soft filter pruning to the ResNet architecture, focusing on minimizing floating-point operations (FLOPs). Furthermore, by using regularization in conjunction with network pruning, we show that such a combination makes a substantial improvement over each of the two techniques individually.