 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheXseg: Combining Expert Annotations with DNN-generated Saliency Maps for X-ray Segmentation
Paper and Code
Feb 21, 2021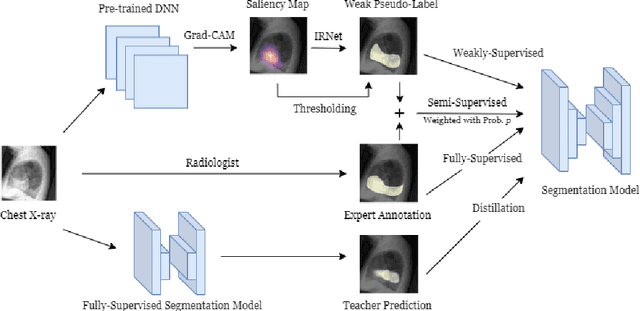
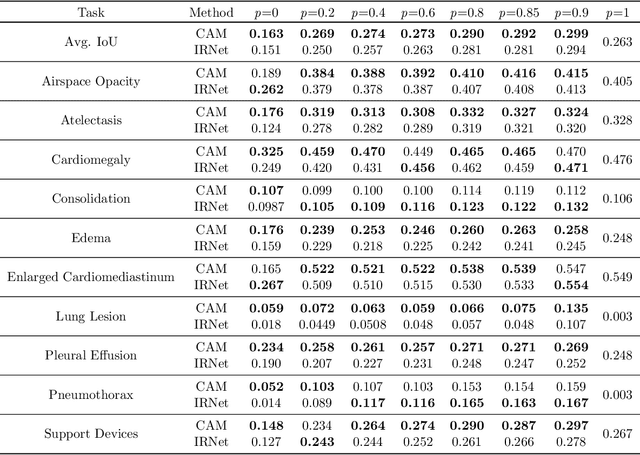
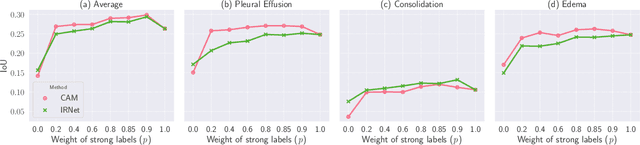
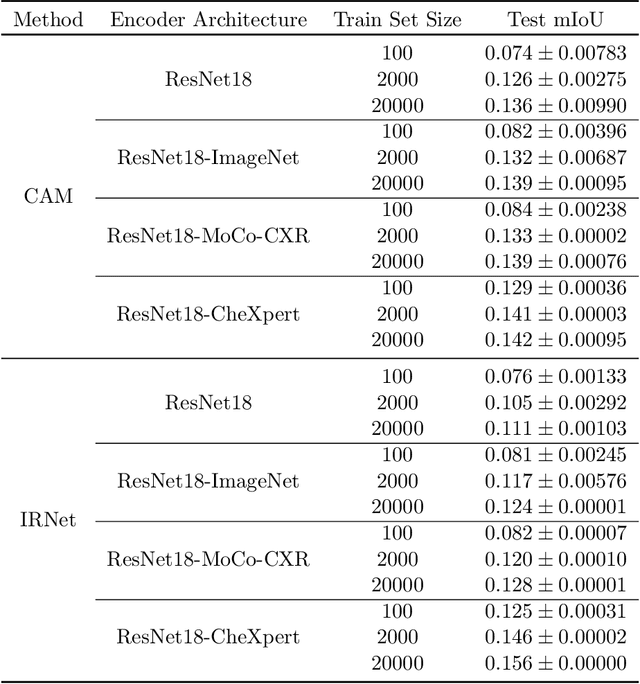
Medical image segmentation models are typically supervised by expert annotations at the pixel-level, which can be expensive to acquire. In this work, we propose a method that combines the high quality of pixel-level expert annotations with the scale of coarse DNN-generated saliency maps for training multi-label semantic segmentation models. We demonstrate the application of our semi-supervised method, which we call CheXseg, on multi-label chest x-ray interpretation. We find that CheXseg improves upon the performance (mIoU) of fully-supervised methods that use only pixel-level expert annotations by 13.4% and weakly-supervised methods that use only DNN-generated saliency maps by 91.2%. Furthermore, we implement a semi-supervised method using knowledge distillation and find that though it is outperformed by CheXseg, it exceeds the performance (mIoU) of the best fully-supervised method by 4.83%. Our best method is able to match radiologist agreement on three out of ten pathologies and reduces the overall performance gap by 71.6% as compared to weakly-supervised methods.