 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurrogateSHAP: Training-Free Contributor Attribution for Text-to-Image (T2I) Models
Jan 29, 2026As Text-to-Image (T2I) diffusion models are increasingly used in real-world creative workflows, a principled framework for valuing contributors who provide a collection of data is essential for fair compensation and sustainable data marketplaces. While the Shapley value offers a theoretically grounded approach to attribution, it faces a dual computational bottleneck: (i) the prohibitive cost of exhaustive model retraining for each sampled subset of players (i.e., data contributors) and (ii) the combinatorial number of subsets needed to estimate marginal contributions due to contributor interactions. To this end, we propose SurrogateSHAP, a retraining-free framework that approximates the expensive retraining game through inference from a pretrained model. To further improve efficiency, we employ a gradient-boosted tree to approximate the utility function and derive Shapley values analytically from the tree-based model. We evaluate SurrogateSHAP across three diverse attribution tasks: (i) image quality for DDPM-CFG on CIFAR-20, (ii) aesthetics for Stable Diffusion on Post-Impressionist artworks, and (iii) product diversity for FLUX.1 on Fashion-Product data. Across settings, SurrogateSHAP outperforms prior methods while substantially reducing computational overhead, consistently identifying influential contributors across multiple utility metrics. Finally, we demonstrate that SurrogateSHAP effectively localizes data sources responsible for spurious correlations in clinical images, providing a scalable path toward auditing safety-critical generative models.
Ensembling Sparse Autoencoders
May 21, 2025Sparse autoencoders (SAEs) are used to decompose neural network activations into human-interpretable features. Typically, features learned by a single SAE are used for downstream applications. However, it has recently been shown that SAEs trained with different initial weights can learn different features, demonstrating that a single SAE captures only a limited subset of features that can be extracted from the activation space. Motivated by this limitation, we propose to ensemble multiple SAEs through naive bagging and boosting. Specifically, SAEs trained with different weight initializations are ensembled in naive bagging, whereas SAEs sequentially trained to minimize the residual error are ensembled in boosting. We evaluate our ensemble approaches with three settings of language models and SAE architectures. Our empirical results demonstrate that ensembling SAEs can improve the reconstruction of language model activations, diversity of features, and SAE stability. Furthermore, ensembling SAEs performs better than applying a single SAE on downstream tasks such as concept detection and spurious correlation removal, showing improved practical utility.
Transformer-based Time-Series Biomarker Discovery for COPD Diagnosis
Nov 13, 2024


Chronic Obstructive Pulmonary Disorder (COPD) is an irreversible and progressive disease which is highly heritable. Clinically, COPD is defined using the summary measures derived from a spirometry test but these are not always adequate. Here we show that using the high-dimensional raw spirogram can provide a richer signal compared to just using the summary measures. We design a transformer-based deep learning technique to process the raw spirogram values along with demographic information and predict clinically-relevant endpoints related to COPD. Our method is able to perform better than prior works while being more computationally efficient. Using the weights learned by the model, we make the framework more interpretable by identifying parts of the spirogram that are important for the model predictions. Pairing up with a board-certified pulmonologist, we also provide clinical insights into the different aspects of the spirogram and show that the explanations obtained from the model align with underlying medical knowledge.
Data Alignment for Zero-Shot Concept Generation in Dermatology AI
Apr 19, 2024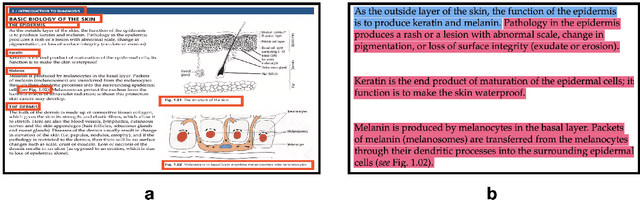



AI in dermatology is evolving at a rapid pace but the major limitation to training trustworthy classifiers is the scarcity of data with ground-truth concept level labels, which are meta-labels semantically meaningful to humans. Foundation models like CLIP providing zero-shot capabilities can help alleviate this challenge by leveraging vast amounts of image-caption pairs available on the internet. CLIP can be fine-tuned using domain specific image-caption pairs to improve classification performance. However, CLIP's pre-training data is not well-aligned with the medical jargon that clinicians use to perform diagnoses. The development of large language models (LLMs) in recent years has led to the possibility of leveraging the expressive nature of these models to generate rich text. Our goal is to use these models to generate caption text that aligns well with both the clinical lexicon and with the natural human language used in CLIP's pre-training data. Starting with captions used for images in PubMed articles, we extend them by passing the raw captions through an LLM fine-tuned on the field's several textbooks. We find that using captions generated by an expressive fine-tuned LLM like GPT-3.5 improves downstream zero-shot concept classification performance.
Classification for everyone : Building geography agnostic models for fairer recognition
Dec 11, 2023
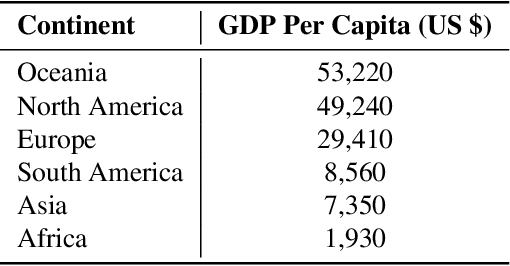
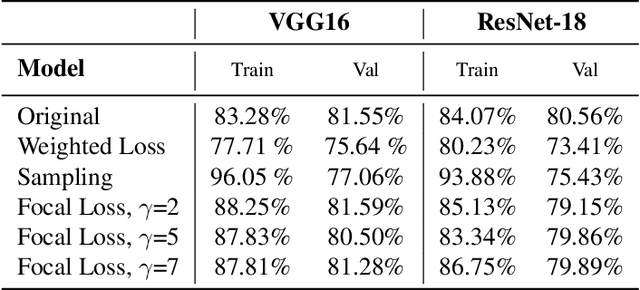

In this paper, we analyze different methods to mitigate inherent geographical biases present in state of the art image classification models. We first quantitatively present this bias in two datasets - The Dollar Street Dataset and ImageNet, using images with location information. We then present different methods which can be employed to reduce this bias. Finally, we analyze the effectiveness of the different techniques on making these models more robust to geographical locations of the images.
Estimating Conditional Mutual Information for Dynamic Feature Selection
Jun 05, 2023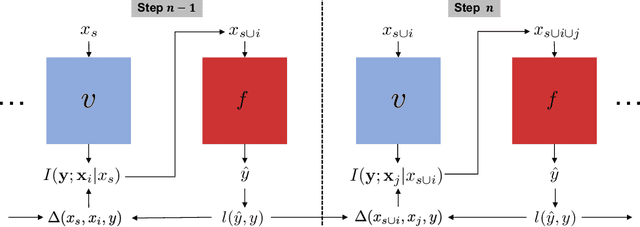
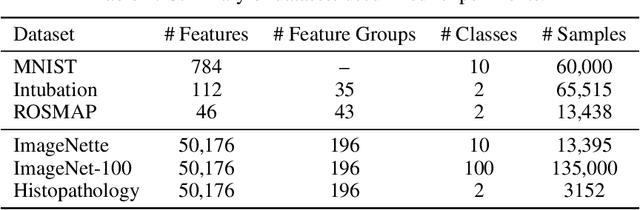
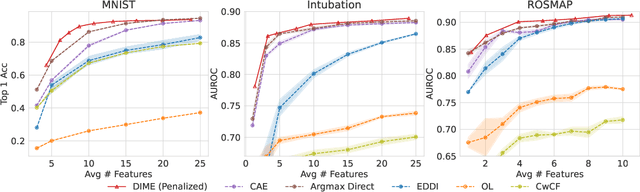
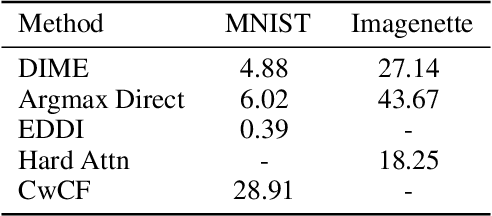
Dynamic feature selection, where we sequentially query features to make accurate predictions with a minimal budget, is a promising paradigm to reduce feature acquisition costs and provide transparency into the prediction process. The problem is challenging, however, as it requires both making predictions with arbitrary feature sets and learning a policy to identify the most valuable selections. Here, we take an information-theoretic perspective and prioritize features based on their mutual information with the response variable. The main challenge is learning this selection policy, and we design a straightforward new modeling approach that estimates the mutual information in a discriminative rather than generative fashion. Building on our learning approach, we introduce several further improvements: allowing variable feature budgets across samples, enabling non-uniform costs between features, incorporating prior information, and exploring modern architectures to handle partial input information. We find that our method provides consistent gains over recent state-of-the-art methods across a variety of datasets.
CheXseg: Combining Expert Annotations with DNN-generated Saliency Maps for X-ray Segmentation
Feb 21, 2021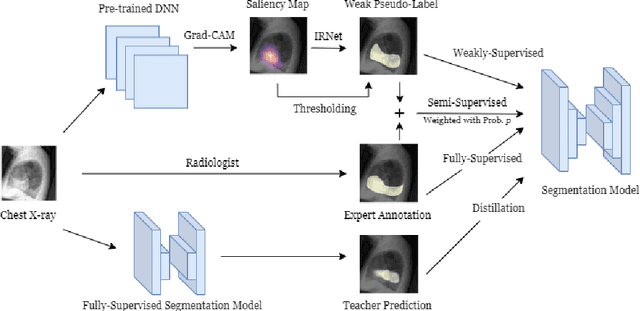
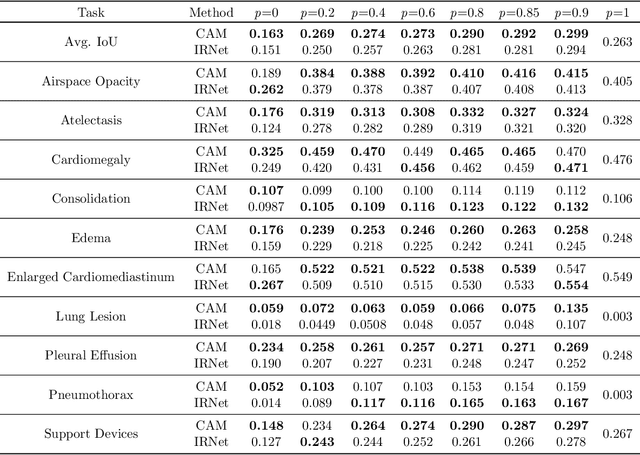
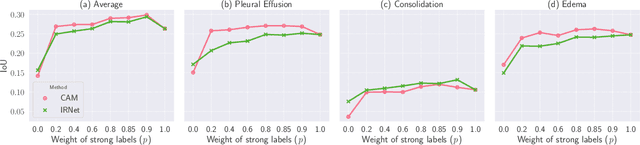
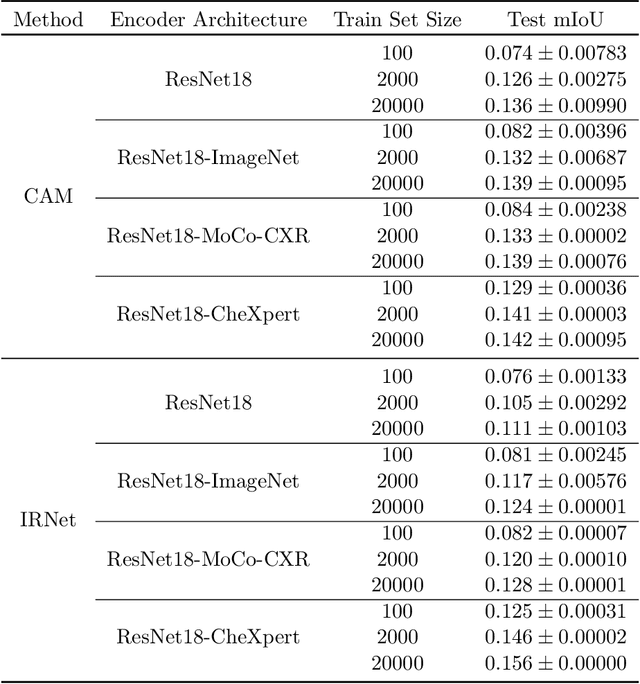
Medical image segmentation models are typically supervised by expert annotations at the pixel-level, which can be expensive to acquire. In this work, we propose a method that combines the high quality of pixel-level expert annotations with the scale of coarse DNN-generated saliency maps for training multi-label semantic segmentation models. We demonstrate the application of our semi-supervised method, which we call CheXseg, on multi-label chest x-ray interpretation. We find that CheXseg improves upon the performance (mIoU) of fully-supervised methods that use only pixel-level expert annotations by 13.4% and weakly-supervised methods that use only DNN-generated saliency maps by 91.2%. Furthermore, we implement a semi-supervised method using knowledge distillation and find that though it is outperformed by CheXseg, it exceeds the performance (mIoU) of the best fully-supervised method by 4.83%. Our best method is able to match radiologist agreement on three out of ten pathologies and reduces the overall performance gap by 71.6% as compared to weakly-supervised methods.
Solving The Lunar Lander Problem under Uncertainty using Reinforcement Learning
Nov 24, 2020
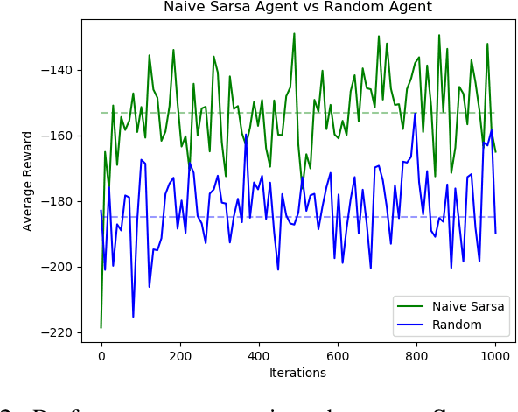

Reinforcement Learning (RL) is an area of machine learning concerned with enabling an agent to navigate an environment with uncertainty in order to maximize some notion of cumulative long-term reward. In this paper, we implement and analyze two different RL techniques, Sarsa and Deep QLearning, on OpenAI Gym's LunarLander-v2 environment. We then introduce additional uncertainty to the original problem to test the robustness of the mentioned techniques. With our best models, we are able to achieve average rewards of 170+ with the Sarsa agent and 200+ with the Deep Q-Learning agent on the original problem. We also show that these techniques are able to overcome the additional uncertainities and achieve positive average rewards of 100+ with both agents. We then perform a comparative analysis of the two techniques to conclude which agent peforms better.
Spatio-Temporal Graph Convolution for Functional MRI Analysis
Mar 24, 2020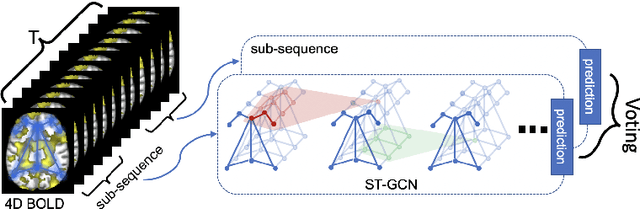
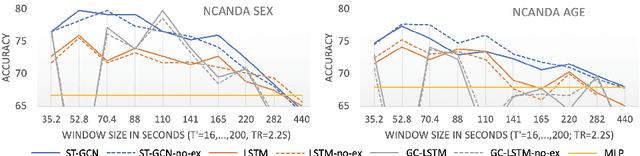
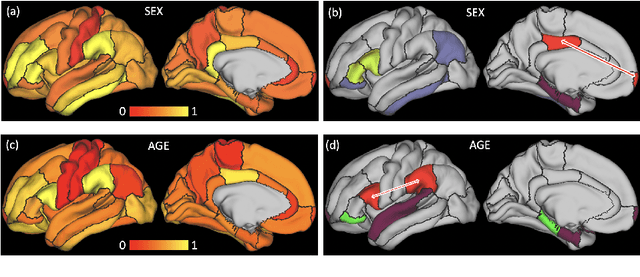
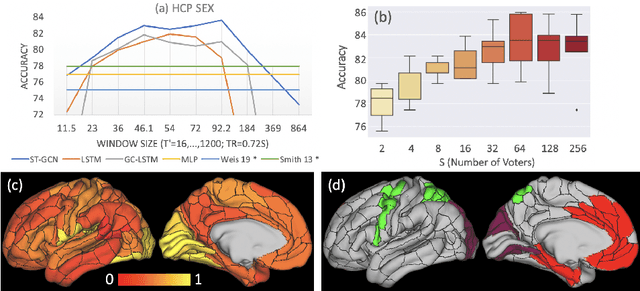
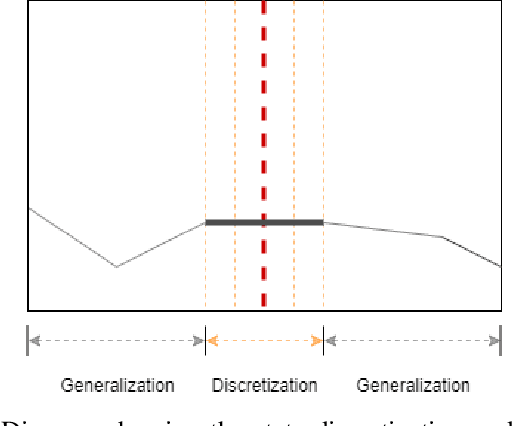
The BOLD signal of resting-state fMRI (rs-fMRI) records the functional brain connectivity in a rich dynamic spatio-temporal setting. However, existing methods applied to rs-fMRI often fail to consider both spatial and temporal characteristics of the data. They either neglect the functional dependency between different brain regions in a network or discard the information in the temporal dynamics of brain activity. To overcome those shortcomings, we propose to formulate functional connectivity networks within the context of spatio-temporal graphs. We then train a spatio-temporal graph convolutional network (ST-GCN) on short sub-sequences of the BOLD time series to model the non-stationary nature of functional connectivity. We simultaneously learn the graph edge importance within ST-GCN to enable interpretation of functional connectivities contributing to the prediction model. In analyzing the rs-fMRI of the Human Connectome Project (HCP, N=1,091) and the National Consortium on Alcohol and Neurodevelopment in Adolescence (NCANDA, N=773), ST-GCN is significantly more accurate than common approaches in predicting gender and age based on BOLD signals. The matrix recording edge importance localizes brain regions and functional connections with significant aging and sex effects, which are verified by the neuroscience literature.
Intelligent City Traffic Management and Public Transportation System
Oct 22, 2013

Intelligent Transportation System in case of cities is controlling traffic congestion and regulating the traffic flow. This paper presents three modules that will help in managing city traffic issues and ultimately gives advanced development in transportation system. First module, Congestion Detection and Management will provide user real time information about congestion on the road towards his destination, Second module, Intelligent Public Transport System will provide user real time public transport information,i.e, local buses, and the third module, Signal Synchronization will help in controlling congestion at signals, with real time adjustments of signal timers according to the congestion. All the information that user is getting about the traffic or public transportation will be provided on users day to day device that is mobile through Android application or SMS. Moreover, communication can also be done via Website for Clients having internet access. And all these modules will be fully automated without any human intervention at server side.