 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Enhanced Large Language Model For Cross Modal Query Understanding System Using DL-KeyBERT Based CAZSSCL-MPGPT
Feb 24, 2025



Large Language Models (LLMs) are advanced deep-learning models designed to understand and generate human language. They work together with models that process data like images, enabling cross-modal understanding. However, existing approaches often suffer from the echo chamber effect, where redundant visual patterns reduce model generalization and accuracy. Thus, the proposed system considered this limitation and developed an enhanced LLM-based framework for cross-modal query understanding using DL-KeyBERT-based CAZSSCL-MPGPT. The collected dataset consists of pre-processed images and texts. The preprocessed images then undergo object segmentation using Easom-You Only Look Once (E-YOLO). The object skeleton is generated, along with the knowledge graph using a Conditional Random Knowledge Graph (CRKG) technique. Further, features are extracted from the knowledge graph, generated skeletons, and segmented objects. The optimal features are then selected using the Fossa Optimization Algorithm (FOA). Meanwhile, the text undergoes word embedding using DL-KeyBERT. Finally, the cross-modal query understanding system utilizes CAZSSCL-MPGPT to generate accurate and contextually relevant image descriptions as text. The proposed CAZSSCL-MPGPT achieved an accuracy of 99.14187362% in the COCO dataset 2017 and 98.43224393% in the vqav2-val dataset.
A Comparison of LLM Finetuning Methods & Evaluation Metrics with Travel Chatbot Use Case
Aug 07, 2024This research compares large language model (LLM) fine-tuning methods, including Quantized Low Rank Adapter (QLoRA), Retrieval Augmented fine-tuning (RAFT), and Reinforcement Learning from Human Feedback (RLHF), and additionally compared LLM evaluation methods including End to End (E2E) benchmark method of "Golden Answers", traditional natural language processing (NLP) metrics, RAG Assessment (Ragas), OpenAI GPT-4 evaluation metrics, and human evaluation, using the travel chatbot use case. The travel dataset was sourced from the the Reddit API by requesting posts from travel-related subreddits to get travel-related conversation prompts and personalized travel experiences, and augmented for each fine-tuning method. We used two pretrained LLMs utilized for fine-tuning research: LLaMa 2 7B, and Mistral 7B. QLoRA and RAFT are applied to the two pretrained models. The inferences from these models are extensively evaluated against the aforementioned metrics. The best model according to human evaluation and some GPT-4 metrics was Mistral RAFT, so this underwent a Reinforcement Learning from Human Feedback (RLHF) training pipeline, and ultimately was evaluated as the best model. Our main findings are that: 1) quantitative and Ragas metrics do not align with human evaluation, 2) Open AI GPT-4 evaluation most aligns with human evaluation, 3) it is essential to keep humans in the loop for evaluation because, 4) traditional NLP metrics insufficient, 5) Mistral generally outperformed LLaMa, 6) RAFT outperforms QLoRA, but still needs postprocessing, 7) RLHF improves model performance significantly. Next steps include improving data quality, increasing data quantity, exploring RAG methods, and focusing data collection on a specific city, which would improve data quality by narrowing the focus, while creating a useful product.
Zero-shot Active Learning Using Self Supervised Learning
Jan 03, 2024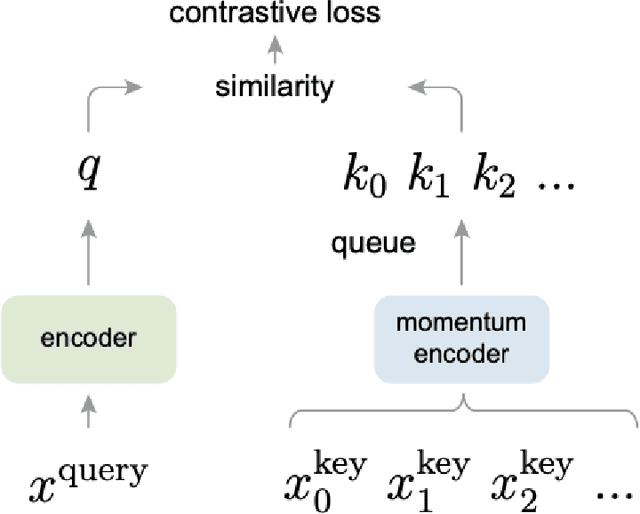
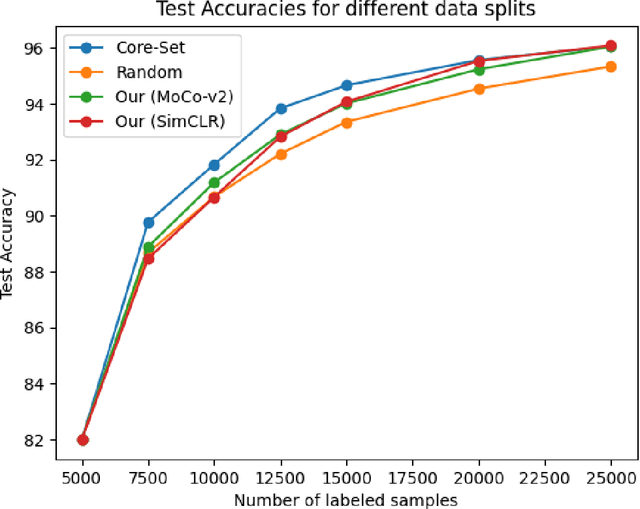
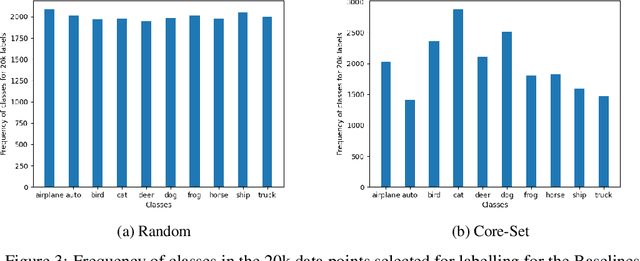
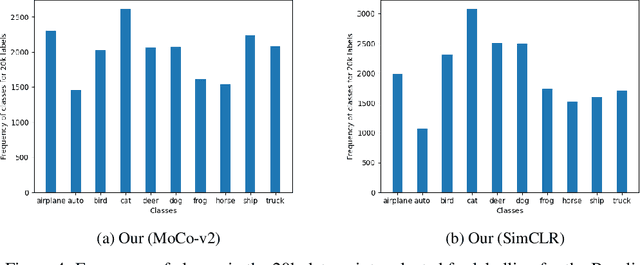
Deep learning algorithms are often said to be data hungry. The performance of such algorithms generally improve as more and more annotated data is fed into the model. While collecting unlabelled data is easier (as they can be scraped easily from the internet), annotating them is a tedious and expensive task. Given a fixed budget available for data annotation, Active Learning helps selecting the best subset of data for annotation, such that the deep learning model when trained over that subset will have maximum generalization performance under this budget. In this work, we aim to propose a new Active Learning approach which is model agnostic as well as one doesn't require an iterative process. We aim to leverage self-supervised learnt features for the task of Active Learning. The benefit of self-supervised learning, is that one can get useful feature representation of the input data, without having any annotation.
Exploring intra-task relations to improve meta-learning algorithms
Dec 27, 2023Meta-learning has emerged as an effective methodology to model several real-world tasks and problems due to its extraordinary effectiveness in the low-data regime. There are many scenarios ranging from the classification of rare diseases to language modelling of uncommon languages where the availability of large datasets is rare. Similarly, for more broader scenarios like self-driving, an autonomous vehicle needs to be trained to handle every situation well. This requires training the ML model on a variety of tasks with good quality data. But often times, we find that the data distribution across various tasks is skewed, i.e.the data follows a long-tail distribution. This leads to the model performing well on some tasks and not performing so well on others leading to model robustness issues. Meta-learning has recently emerged as a potential learning paradigm which can effectively learn from one task and generalize that learning to unseen tasks. In this study, we aim to exploit external knowledge of task relations to improve training stability via effective mini-batching of tasks. We hypothesize that selecting a diverse set of tasks in a mini-batch will lead to a better estimate of the full gradient and hence will lead to a reduction of noise in training.
Detecting anxiety from short clips of free-form speech
Dec 23, 2023



Barriers to accessing mental health assessments including cost and stigma continues to be an impediment in mental health diagnosis and treatment. Machine learning approaches based on speech samples could help in this direction. In this work, we develop machine learning solutions to diagnose anxiety disorders from audio journals of patients. We work on a novel anxiety dataset (provided through collaboration with Kintsugi Mindful Wellness Inc.) and experiment with several models of varying complexity utilizing audio, text and a combination of multiple modalities. We show that the multi-modal and audio embeddings based approaches achieve good performance in the task achieving an AUC ROC score of 0.68-0.69.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Shaping Political Discourse using multi-source News Summarization
Dec 18, 2023Multi-document summarization is the process of automatically generating a concise summary of multiple documents related to the same topic. This summary can help users quickly understand the key information from a large collection of documents. Multi-document summarization systems are more complex than single-document summarization systems due to the need to identify and combine information from multiple sources. In this paper, we have developed a machine learning model that generates a concise summary of a topic from multiple news documents. The model is designed to be unbiased by sampling its input equally from all the different aspects of the topic, even if the majority of the news sources lean one way.
Exploring Graph Based Approaches for Author Name Disambiguation
Dec 12, 2023In many applications, such as scientific literature management, researcher search, social network analysis and etc, Name Disambiguation (aiming at disambiguating WhoIsWho) has been a challenging problem. In addition, the growth of scientific literature makes the problem more difficult and urgent. Although name disambiguation has been extensively studied in academia and industry, the problem has not been solved well due to the clutter of data and the complexity of the same name scenario. In this work, we aim to explore models that can perform the task of name disambiguation using the network structure that is intrinsic to the problem and present an analysis of the models.
Classification for everyone : Building geography agnostic models for fairer recognition
Dec 11, 2023
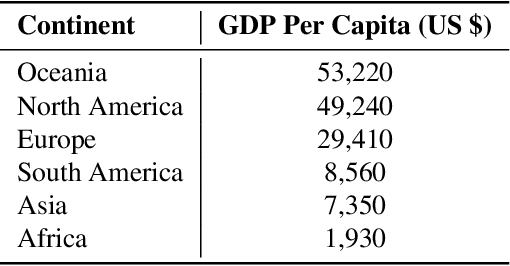
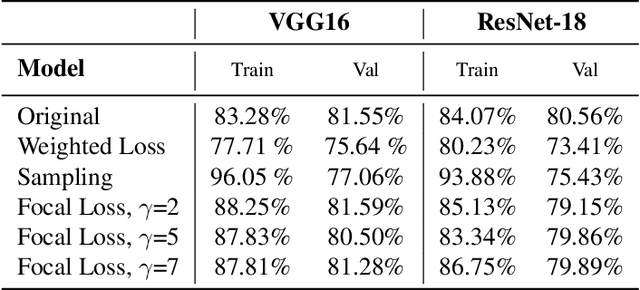

In this paper, we analyze different methods to mitigate inherent geographical biases present in state of the art image classification models. We first quantitatively present this bias in two datasets - The Dollar Street Dataset and ImageNet, using images with location information. We then present different methods which can be employed to reduce this bias. Finally, we analyze the effectiveness of the different techniques on making these models more robust to geographical locations of the images.
One Embedding To Do Them All
Jun 28, 2019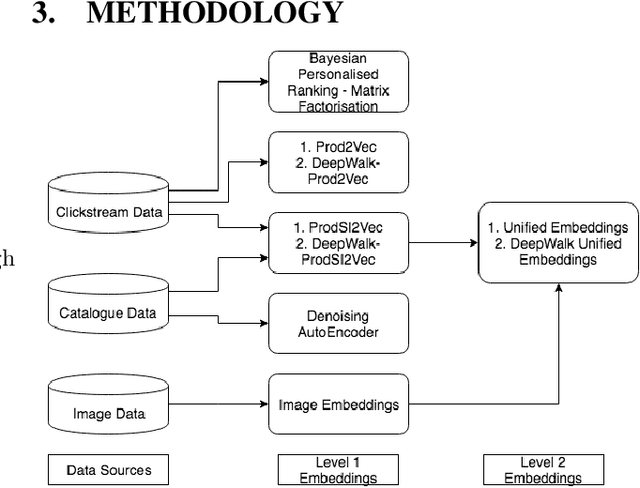

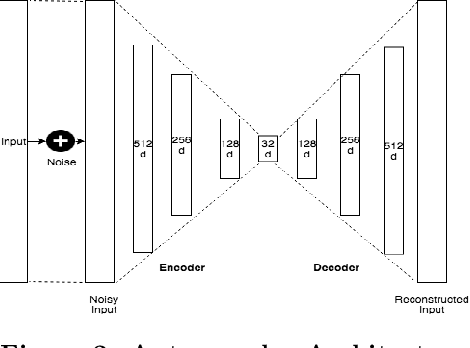
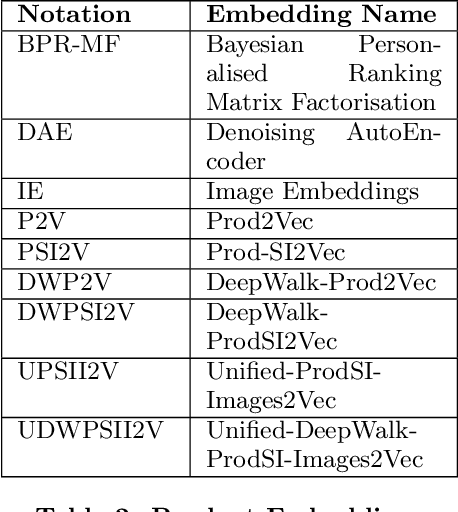
Online shopping caters to the needs of millions of users daily. Search, recommendations, personalization have become essential building blocks for serving customer needs. Efficacy of such systems is dependent on a thorough understanding of products and their representation. Multiple information sources and data types provide a complete picture of the product on the platform. While each of these tasks shares some common characteristics, typically product embeddings are trained and used in isolation. In this paper, we propose a framework to combine multiple data sources and learn unified embeddings for products on our e-commerce platform. Our product embeddings are built from three types of data sources - catalog text data, a user's clickstream session data and product images. We use various techniques like denoising auto-encoders for text, Bayesian personalized ranking (BPR) for clickstream data, Siamese neural network architecture for image data and combined ensemble over the above methods for unified embeddings. Further, we compare and analyze the performance of these embeddings across three unrelated real-world e-commerce tasks specifically checking product attribute coverage, finding similar products and predicting returns. We show that unified product embeddings perform uniformly well across all these tasks.