 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriving Innovation in 6G Wireless Technologies: The OpenAirInterface Approach
Dec 17, 2024


The development of 6G wireless technologies is rapidly advancing, with the 3rd Generation Partnership Project (3GPP) entering the pre-standardization phase and aiming to deliver the first specifications by 2028. This paper explores the OpenAirInterface (OAI) project, an open-source initiative that plays a crucial role in the evolution of 5G and the future 6G networks. OAI provides a comprehensive implementation of 3GPP and O-RAN compliant networks, including Radio Access Network (RAN), Core Network (CN), and software-defined User Equipment (UE) components. The paper details the history and evolution of OAI, its licensing model, and the various projects under its umbrella, such as RAN, the CN, as well as the Operations, Administration and Maintenance (OAM) projects. It also highlights the development methodology, Continuous Integration/Continuous Delivery (CI/CD) processes, and end-to-end systems powered by OAI. Furthermore, the paper discusses the potential of OAI for 6G research, focusing on spectrum, reflective intelligent surfaces, and Artificial Intelligence (AI)/Machine Learning (ML) integration. The open-source approach of OAI is emphasized as essential for tackling the challenges of 6G, fostering community collaboration, and driving innovation in next-generation wireless technologies.
Learning to Rank Broad and Narrow Queries in E-Commerce
Jul 15, 2019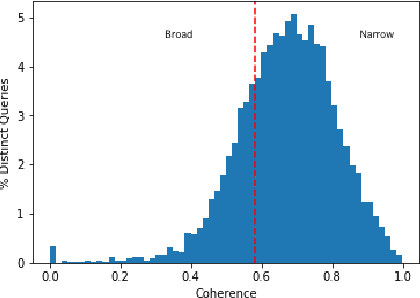
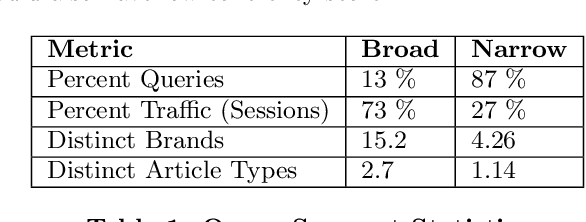
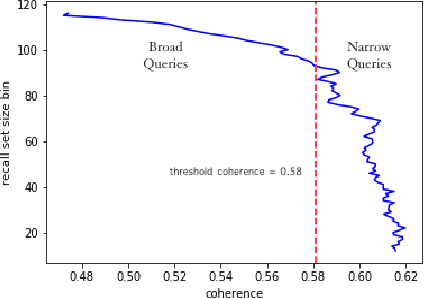
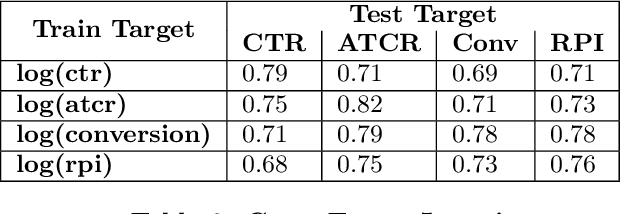
Search is a prominent channel for discovering products on an e-commerce platform. Ranking products retrieved from search becomes crucial to address customer's need and optimize for business metrics. While learning to Rank (LETOR) models have been extensively studied and have demonstrated efficacy in the context of web search; it is a relatively new research area to be explored in the e-commerce. In this paper, we present a framework for building LETOR model for an e-commerce platform. We analyze user queries and propose a mechanism to segment queries between broad and narrow based on user's intent. We discuss different types of features - query, product and query-product and discuss challenges in using them. We show that sparsity in product features can be tackled through a denoising auto-encoder while skip-gram based word embeddings help solve the query-product sparsity issues. We also present various target metrics that can be employed for evaluating search results and compare their robustness. Further, we build and compare performances of both pointwise and pairwise LETOR models on fashion category data set. We also build and compare distinct models for broad and narrow queries, analyze feature importance across these and show that these specialized models perform better than a combined model in the fashion world.
One Embedding To Do Them All
Jun 28, 2019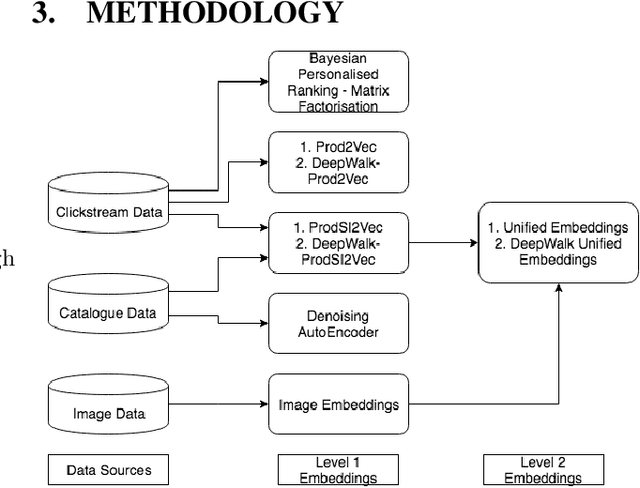

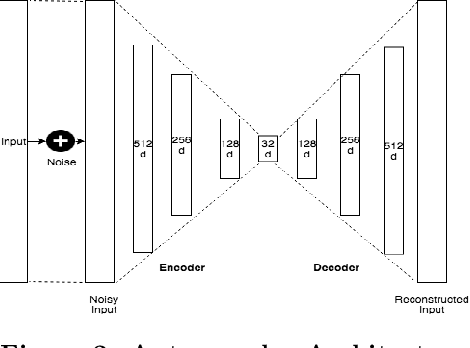
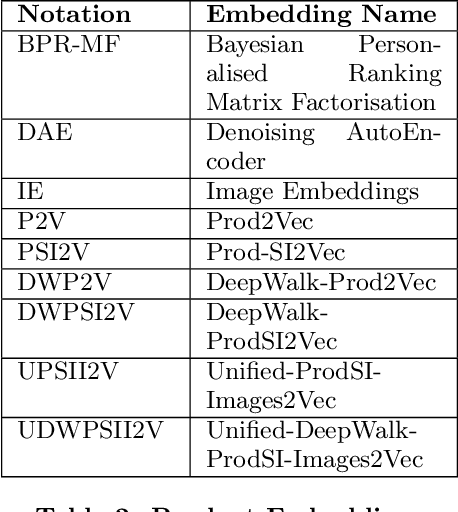
Online shopping caters to the needs of millions of users daily. Search, recommendations, personalization have become essential building blocks for serving customer needs. Efficacy of such systems is dependent on a thorough understanding of products and their representation. Multiple information sources and data types provide a complete picture of the product on the platform. While each of these tasks shares some common characteristics, typically product embeddings are trained and used in isolation. In this paper, we propose a framework to combine multiple data sources and learn unified embeddings for products on our e-commerce platform. Our product embeddings are built from three types of data sources - catalog text data, a user's clickstream session data and product images. We use various techniques like denoising auto-encoders for text, Bayesian personalized ranking (BPR) for clickstream data, Siamese neural network architecture for image data and combined ensemble over the above methods for unified embeddings. Further, we compare and analyze the performance of these embeddings across three unrelated real-world e-commerce tasks specifically checking product attribute coverage, finding similar products and predicting returns. We show that unified product embeddings perform uniformly well across all these tasks.