 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArming Data Agents with Tribal Knowledge
Feb 13, 2026Natural language to SQL (NL2SQL) translation enables non-expert users to query relational databases through natural language. Recently, NL2SQL agents, powered by the reasoning capabilities of Large Language Models (LLMs), have significantly advanced NL2SQL translation. Nonetheless, NL2SQL agents still make mistakes when faced with large-scale real-world databases because they lack knowledge of how to correctly leverage the underlying data (e.g., knowledge about the intent of each column) and form misconceptions about the data when querying it, leading to errors. Prior work has studied generating facts about the database to provide more context to NL2SQL agents, but such approaches simply restate database contents without addressing the agent's misconceptions. In this paper, we propose Tk-Boost, a bolt-on framework for augmenting any NL2SQL agent with tribal knowledge: knowledge that corrects the agent's misconceptions in querying the database accumulated through experience using the database. To accumulate experience, Tk-Boost first asks the NL2SQL agent to answer a few queries on the database, identifies the agent's misconceptions by analyzing its mistakes on the database, and generates tribal knowledge to address them. To enable accurate retrieval, Tk-Boost indexes this knowledge with applicability conditions that specify the query features for which the knowledge is useful. When answering new queries, Tk-Boost uses this knowledge to provide feedback to the NL2SQL agent, resolving the agent's misconceptions during SQL generation, and thus improving the agent's accuracy. Extensive experiments across the BIRD and Spider 2.0 benchmarks with various NL2SQL agents shows Tk-Boost improves NL2SQL agents accuracy by up to 16.9% on Spider 2.0 and 13.7% on BIRD
TARGET: Benchmarking Table Retrieval for Generative Tasks
May 14, 2025The data landscape is rich with structured data, often of high value to organizations, driving important applications in data analysis and machine learning. Recent progress in representation learning and generative models for such data has led to the development of natural language interfaces to structured data, including those leveraging text-to-SQL. Contextualizing interactions, either through conversational interfaces or agentic components, in structured data through retrieval-augmented generation can provide substantial benefits in the form of freshness, accuracy, and comprehensiveness of answers. The key question is: how do we retrieve the right table(s) for the analytical query or task at hand? To this end, we introduce TARGET: a benchmark for evaluating TAble Retrieval for GEnerative Tasks. With TARGET we analyze the retrieval performance of different retrievers in isolation, as well as their impact on downstream tasks. We find that dense embedding-based retrievers far outperform a BM25 baseline which is less effective than it is for retrieval over unstructured text. We also surface the sensitivity of retrievers across various metadata (e.g., missing table titles), and demonstrate a stark variation of retrieval performance across datasets and tasks. TARGET is available at https://target-benchmark.github.io.
TWIX: Automatically Reconstructing Structured Data from Templatized Documents
Jan 11, 2025



Many documents, that we call templatized documents, are programmatically generated by populating fields in a visual template. Effective data extraction from these documents is crucial to supporting downstream analytical tasks. Current data extraction tools often struggle with complex document layouts, incur high latency and/or cost on large datasets, and often require significant human effort, when extracting tables or values given user-specified fields from documents. The key insight of our tool, TWIX, is to predict the underlying template used to create such documents, modeling the visual and structural commonalities across documents. Data extraction based on this predicted template provides a more principled, accurate, and efficient solution at a low cost. Comprehensive evaluations on 34 diverse real-world datasets show that uncovering the template is crucial for data extraction from templatized documents. TWIX achieves over 90% precision and recall on average, outperforming tools from industry: Textract and Azure Document Intelligence, and vision-based LLMs like GPT-4-Vision, by over 25% in precision and recall. TWIX scales easily to large datasets and is 734X faster and 5836X cheaper than vision-based LLMs for extracting data from a large document collection with 817 pages.
DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing
Oct 16, 2024



Analyzing unstructured data, such as complex documents, has been a persistent challenge in data processing. Large Language Models (LLMs) have shown promise in this regard, leading to recent proposals for declarative frameworks for LLM-powered unstructured data processing. However, these frameworks focus on reducing cost when executing user-specified operations using LLMs, rather than improving accuracy, executing most operations as-is. This is problematic for complex tasks and data, where LLM outputs for user-defined operations are often inaccurate, even with optimized prompts. We present DocETL, a system that optimizes complex document processing pipelines, while accounting for LLM shortcomings. DocETL offers a declarative interface for users to define such pipelines and uses an agent-based framework to automatically optimize them, leveraging novel agent-based rewrites (that we call {\em rewrite directives}) and an optimization and evaluation framework that we introduce. We introduce {\em (i)} logical rewriting of pipelines, tailored for LLM-based tasks, {\em (ii)} an agent-guided plan evaluation mechanism that synthesizes and orchestrates task-specific validation prompts, and {\em (iii)} an optimization algorithm that efficiently finds promising plans, considering the time constraints of LLM-based plan generation and evaluation. Our evaluation on three different unstructured document analysis tasks demonstrates that DocETL finds plans with outputs that are $1.34$ to $4.6\times$ higher quality (e.g., more accurate, comprehensive) than well-engineered baselines, addressing a critical gap in existing declarative frameworks for unstructured data analysis. DocETL is open-source at \ttt{docetl.org}, and as of October 2024, has amassed over 800 GitHub Stars, with users spanning a variety of domains.
Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences
Apr 18, 2024



Due to the cumbersome nature of human evaluation and limitations of code-based evaluation, Large Language Models (LLMs) are increasingly being used to assist humans in evaluating LLM outputs. Yet LLM-generated evaluators simply inherit all the problems of the LLMs they evaluate, requiring further human validation. We present a mixed-initiative approach to ``validate the validators'' -- aligning LLM-generated evaluation functions (be it prompts or code) with human requirements. Our interface, EvalGen, provides automated assistance to users in generating evaluation criteria and implementing assertions. While generating candidate implementations (Python functions, LLM grader prompts), EvalGen asks humans to grade a subset of LLM outputs; this feedback is used to select implementations that better align with user grades. A qualitative study finds overall support for EvalGen but underscores the subjectivity and iterative process of alignment. In particular, we identify a phenomenon we dub \emph{criteria drift}: users need criteria to grade outputs, but grading outputs helps users define criteria. What is more, some criteria appears \emph{dependent} on the specific LLM outputs observed (rather than independent criteria that can be defined \emph{a priori}), raising serious questions for approaches that assume the independence of evaluation from observation of model outputs. We present our interface and implementation details, a comparison of our algorithm with a baseline approach, and implications for the design of future LLM evaluation assistants.
Revisiting Prompt Engineering via Declarative Crowdsourcing
Aug 07, 2023Large language models (LLMs) are incredibly powerful at comprehending and generating data in the form of text, but are brittle and error-prone. There has been an advent of toolkits and recipes centered around so-called prompt engineering-the process of asking an LLM to do something via a series of prompts. However, for LLM-powered data processing workflows, in particular, optimizing for quality, while keeping cost bounded, is a tedious, manual process. We put forth a vision for declarative prompt engineering. We view LLMs like crowd workers and leverage ideas from the declarative crowdsourcing literature-including leveraging multiple prompting strategies, ensuring internal consistency, and exploring hybrid-LLM-non-LLM approaches-to make prompt engineering a more principled process. Preliminary case studies on sorting, entity resolution, and imputation demonstrate the promise of our approach
Operationalizing Machine Learning: An Interview Study
Sep 16, 2022
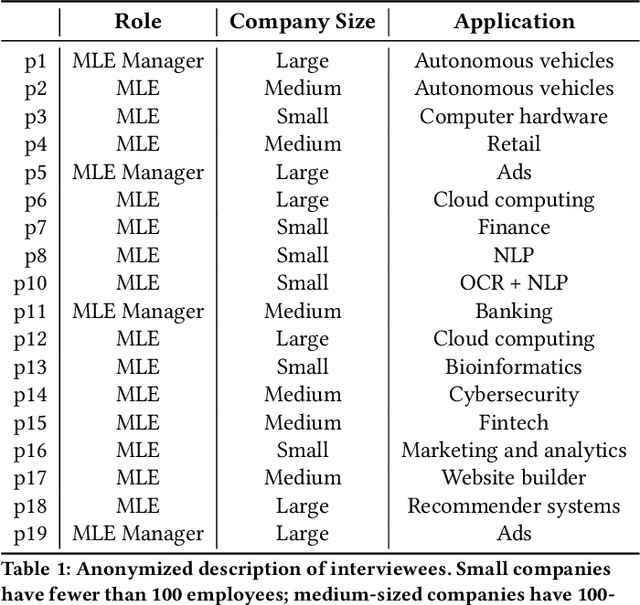
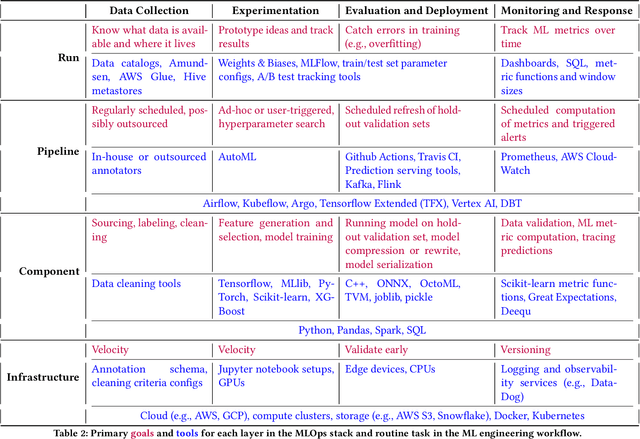
Organizations rely on machine learning engineers (MLEs) to operationalize ML, i.e., deploy and maintain ML pipelines in production. The process of operationalizing ML, or MLOps, consists of a continual loop of (i) data collection and labeling, (ii) experimentation to improve ML performance, (iii) evaluation throughout a multi-staged deployment process, and (iv) monitoring of performance drops in production. When considered together, these responsibilities seem staggering -- how does anyone do MLOps, what are the unaddressed challenges, and what are the implications for tool builders? We conducted semi-structured ethnographic interviews with 18 MLEs working across many applications, including chatbots, autonomous vehicles, and finance. Our interviews expose three variables that govern success for a production ML deployment: Velocity, Validation, and Versioning. We summarize common practices for successful ML experimentation, deployment, and sustaining production performance. Finally, we discuss interviewees' pain points and anti-patterns, with implications for tool design.
Rethinking Streaming Machine Learning Evaluation
May 23, 2022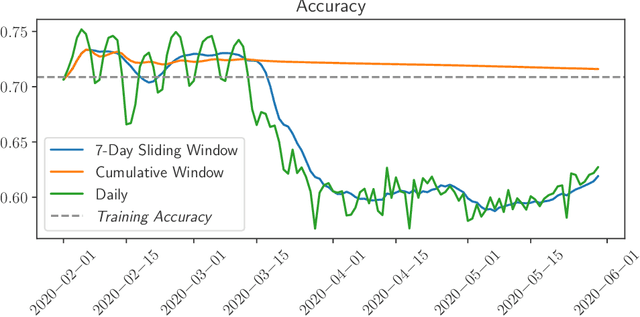
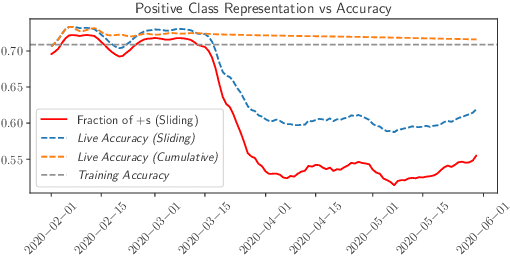
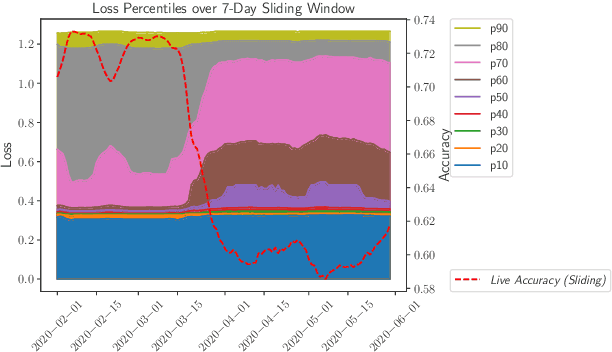
While most work on evaluating machine learning (ML) models focuses on computing accuracy on batches of data, tracking accuracy alone in a streaming setting (i.e., unbounded, timestamp-ordered datasets) fails to appropriately identify when models are performing unexpectedly. In this position paper, we discuss how the nature of streaming ML problems introduces new real-world challenges (e.g., delayed arrival of labels) and recommend additional metrics to assess streaming ML performance.