 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperationalizing Machine Learning: An Interview Study
Sep 16, 2022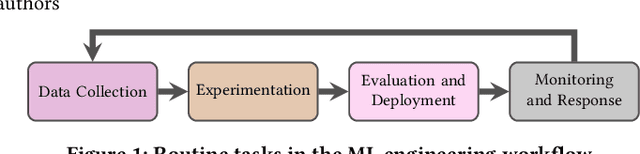
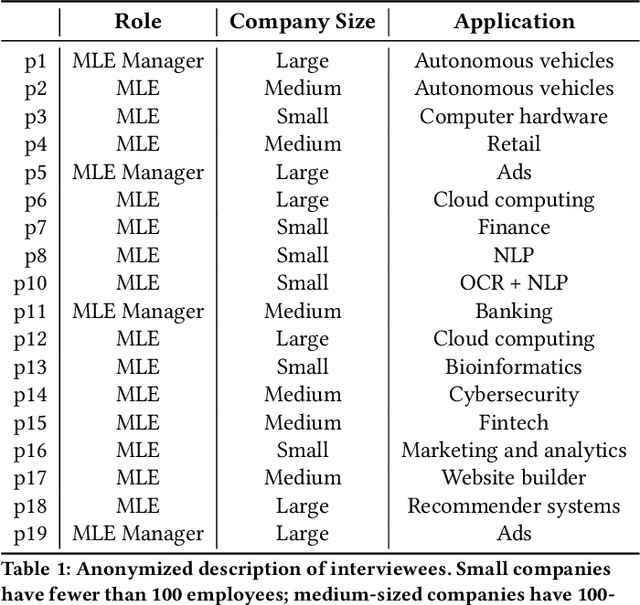
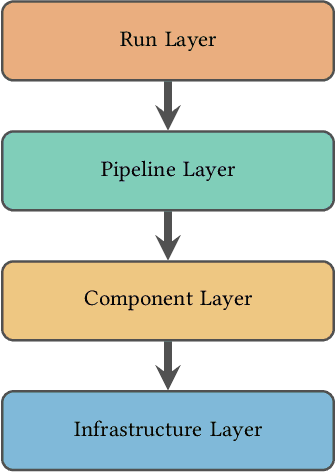
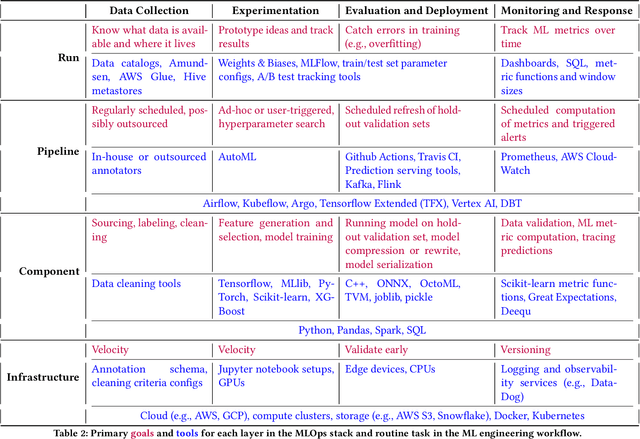
Organizations rely on machine learning engineers (MLEs) to operationalize ML, i.e., deploy and maintain ML pipelines in production. The process of operationalizing ML, or MLOps, consists of a continual loop of (i) data collection and labeling, (ii) experimentation to improve ML performance, (iii) evaluation throughout a multi-staged deployment process, and (iv) monitoring of performance drops in production. When considered together, these responsibilities seem staggering -- how does anyone do MLOps, what are the unaddressed challenges, and what are the implications for tool builders? We conducted semi-structured ethnographic interviews with 18 MLEs working across many applications, including chatbots, autonomous vehicles, and finance. Our interviews expose three variables that govern success for a production ML deployment: Velocity, Validation, and Versioning. We summarize common practices for successful ML experimentation, deployment, and sustaining production performance. Finally, we discuss interviewees' pain points and anti-patterns, with implications for tool design.