Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Streaming Machine Learning Evaluation
Paper and Code
May 23, 2022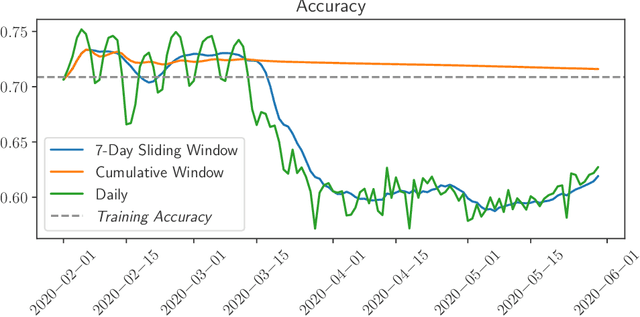
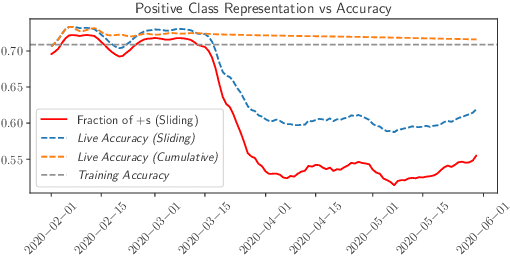
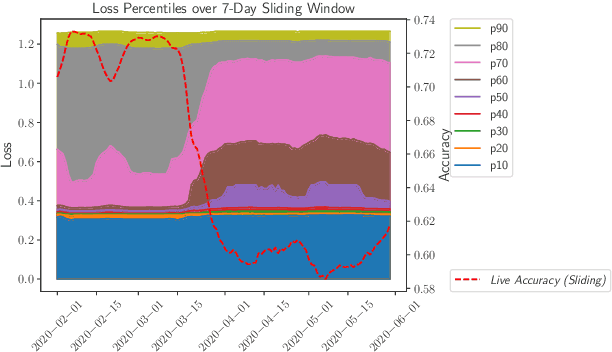
While most work on evaluating machine learning (ML) models focuses on computing accuracy on batches of data, tracking accuracy alone in a streaming setting (i.e., unbounded, timestamp-ordered datasets) fails to appropriately identify when models are performing unexpectedly. In this position paper, we discuss how the nature of streaming ML problems introduces new real-world challenges (e.g., delayed arrival of labels) and recommend additional metrics to assess streaming ML performance.
* ML Evaluation Standards Workshop (ICLR 2022)
View paper on