 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaboratory-Scale AI: Open-Weight Models are Competitive with ChatGPT Even in Low-Resource Settings
May 27, 2024



The rapid proliferation of generative AI has raised questions about the competitiveness of lower-parameter, locally tunable, open-weight models relative to high-parameter, API-guarded, closed-weight models in terms of performance, domain adaptation, cost, and generalization. Centering under-resourced yet risk-intolerant settings in government, research, and healthcare, we see for-profit closed-weight models as incompatible with requirements for transparency, privacy, adaptability, and standards of evidence. Yet the performance penalty in using open-weight models, especially in low-data and low-resource settings, is unclear. We assess the feasibility of using smaller, open-weight models to replace GPT-4-Turbo in zero-shot, few-shot, and fine-tuned regimes, assuming access to only a single, low-cost GPU. We assess value-sensitive issues around bias, privacy, and abstention on three additional tasks relevant to those topics. We find that with relatively low effort, very low absolute monetary cost, and relatively little data for fine-tuning, small open-weight models can achieve competitive performance in domain-adapted tasks without sacrificing generality. We then run experiments considering practical issues in bias, privacy, and hallucination risk, finding that open models offer several benefits over closed models. We intend this work as a case study in understanding the opportunity cost of reproducibility and transparency over for-profit state-of-the-art zero shot performance, finding this cost to be marginal under realistic settings.
Rethinking Streaming Machine Learning Evaluation
May 23, 2022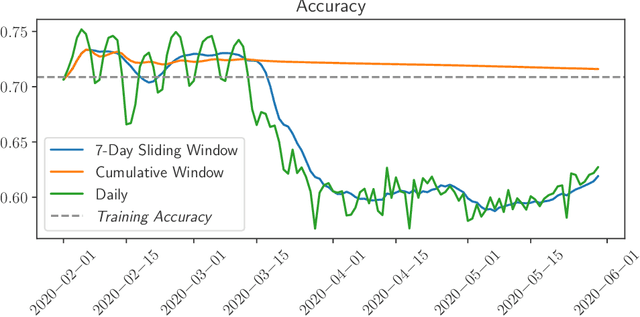
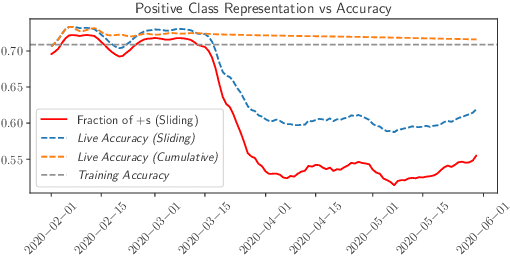
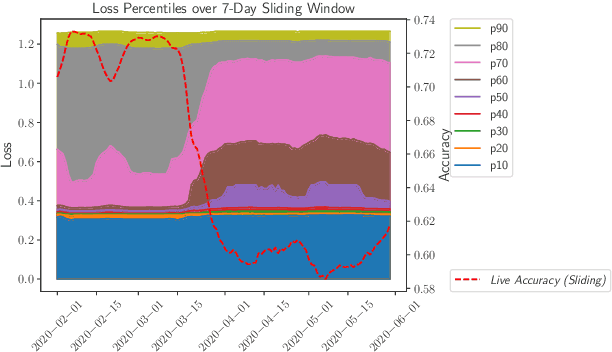
While most work on evaluating machine learning (ML) models focuses on computing accuracy on batches of data, tracking accuracy alone in a streaming setting (i.e., unbounded, timestamp-ordered datasets) fails to appropriately identify when models are performing unexpectedly. In this position paper, we discuss how the nature of streaming ML problems introduces new real-world challenges (e.g., delayed arrival of labels) and recommend additional metrics to assess streaming ML performance.
An Algorithmic Equity Toolkit for Technology Audits by Community Advocates and Activists
Dec 06, 2019
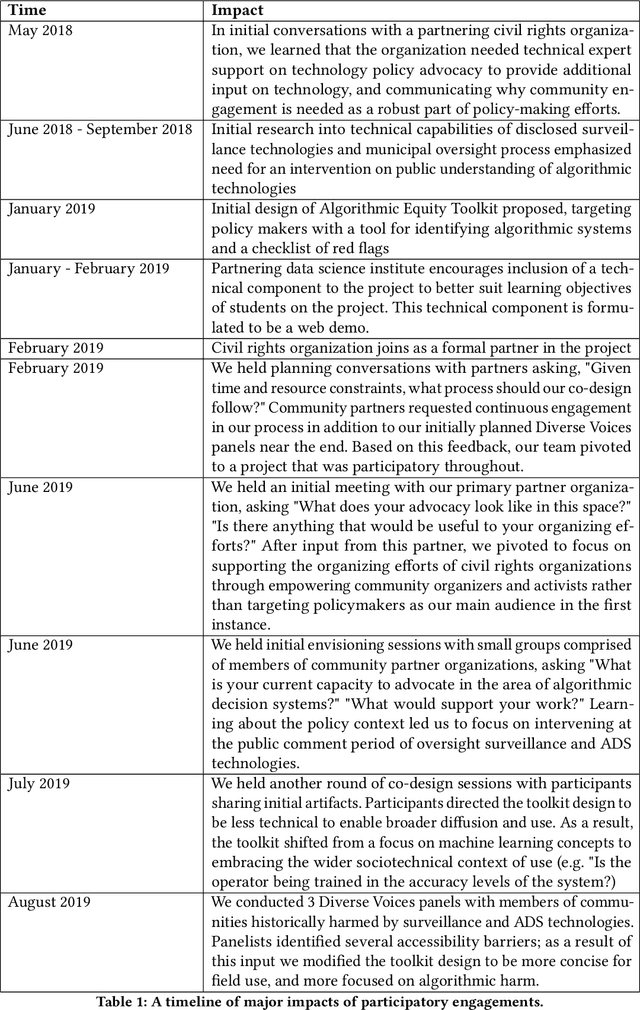
A wave of recent scholarship documenting the discriminatory harms of algorithmic systems has spurred widespread interest in algorithmic accountability and regulation. Yet effective accountability and regulation is stymied by a persistent lack of resources supporting public understanding of algorithms and artificial intelligence. Through interactions with a US-based civil rights organization and their coalition of community organizations, we identify a need for (i) heuristics that aid stakeholders in distinguishing between types of analytic and information systems in lay language, and (ii) risk assessment tools for such systems that begin by making algorithms more legible. The present work delivers a toolkit to achieve these aims. This paper both presents the Algorithmic Equity Toolkit (AEKit) Equity as an artifact, and details how our participatory process shaped its design. Our work fits within human-computer interaction scholarship as a demonstration of the value of HCI methods and approaches to problems in the area of algorithmic transparency and accountability.
The Promise and Peril of Human Evaluation for Model Interpretability
Nov 20, 2017Transparency, user trust, and human comprehension are popular ethical motivations for interpretable machine learning. In support of these goals, researchers evaluate model explanation performance using humans and real world applications. This alone presents a challenge in many areas of artificial intelligence. In this position paper, we propose a distinction between descriptive and persuasive explanations. We discuss reasoning suggesting that functional interpretability may be correlated with cognitive function and user preferences. If this is indeed the case, evaluation and optimization using functional metrics could perpetuate implicit cognitive bias in explanations that threaten transparency. Finally, we propose two potential research directions to disambiguate cognitive function and explanation models, retaining control over the tradeoff between accuracy and interpretability.