 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToys that listen, talk, and play: Understanding Children's Sensemaking and Interactions with AI Toys
Apr 03, 2026Generative AI (genAI) is increasingly being integrated into children's everyday lives, not only through screens but also through so-called "screen-free" AI toys. These toys can simulate emotions, personalize responses, and recall prior interactions, creating the illusion of an ongoing social connection. Such capabilities raise important questions about how children understand boundaries, agency, and relationships when interacting with AI toys. To investigate this, we conducted two participatory design sessions with eight children ages 6-11 where they engaged with three different AI toys, shifting between play, experimentation, and reflection. Our findings reveal that children approached AI toys with genuine curiosity, profiling them as social beings. However, frequent interaction breakdowns and mismatches between apparent intelligence and toy-like form disrupted expectations around play and led to adversarial play. We conclude with implications and design provocations to navigate children's encounters with AI toys in more transparent, developmentally appropriate, and responsible ways.
Where Does AI Leave a Footprint? Children's Reasoning About AI's Environmental Costs
Mar 28, 2026Two of the most socially consequential issues facing today's children are the rise of artificial intelligence (AI) and the rapid changes to the earth's climate. Both issues are complex and contested, and they are linked through the notable environmental costs of AI use. Using a systems thinking framework, we developed an interactive system called Ecoprompt to help children reason about the environmental impact of AI. EcoPrompt combines a prompt-level environmental footprint calculator with a simulation game that challenges players to reason about the impact of AI use on natural resources that the player manages. We evaluated the system through two participatory design sessions with 16 children ages 6-12. Our findings surfaced children's perspectives on societal and environmental tradeoffs of AI use, as well as their sense of agency and responsibility. Taken together, these findings suggest opportunities for broadening AI literacy to include systems-level reasoning about AI's environmental impact.
Can Large Language Models Integrate Spatial Data? Empirical Insights into Reasoning Strengths and Computational Weaknesses
Aug 07, 2025



We explore the application of large language models (LLMs) to empower domain experts in integrating large, heterogeneous, and noisy urban spatial datasets. Traditional rule-based integration methods are unable to cover all edge cases, requiring manual verification and repair. Machine learning approaches require collecting and labeling of large numbers of task-specific samples. In this study, we investigate the potential of LLMs for spatial data integration. Our analysis first considers how LLMs reason about environmental spatial relationships mediated by human experience, such as between roads and sidewalks. We show that while LLMs exhibit spatial reasoning capabilities, they struggle to connect the macro-scale environment with the relevant computational geometry tasks, often producing logically incoherent responses. But when provided relevant features, thereby reducing dependence on spatial reasoning, LLMs are able to generate high-performing results. We then adapt a review-and-refine method, which proves remarkably effective in correcting erroneous initial responses while preserving accurate responses. We discuss practical implications of employing LLMs for spatial data integration in real-world contexts and outline future research directions, including post-training, multi-modal integration methods, and support for diverse data formats. Our findings position LLMs as a promising and flexible alternative to traditional rule-based heuristics, advancing the capabilities of adaptive spatial data integration.
Children's Mental Models of AI Reasoning: Implications for AI Literacy Education
May 21, 2025As artificial intelligence (AI) advances in reasoning capabilities, most recently with the emergence of Large Reasoning Models (LRMs), understanding how children conceptualize AI's reasoning processes becomes critical for fostering AI literacy. While one of the "Five Big Ideas" in AI education highlights reasoning algorithms as central to AI decision-making, less is known about children's mental models in this area. Through a two-phase approach, consisting of a co-design session with 8 children followed by a field study with 106 children (grades 3-8), we identified three models of AI reasoning: Deductive, Inductive, and Inherent. Our findings reveal that younger children (grades 3-5) often attribute AI's reasoning to inherent intelligence, while older children (grades 6-8) recognize AI as a pattern recognizer. We highlight three tensions that surfaced in children's understanding of AI reasoning and conclude with implications for scaffolding AI curricula and designing explainable AI tools.
Fragments to Facts: Partial-Information Fragment Inference from LLMs
May 20, 2025Large language models (LLMs) can leak sensitive training data through memorization and membership inference attacks. Prior work has primarily focused on strong adversarial assumptions, including attacker access to entire samples or long, ordered prefixes, leaving open the question of how vulnerable LLMs are when adversaries have only partial, unordered sample information. For example, if an attacker knows a patient has "hypertension," under what conditions can they query a model fine-tuned on patient data to learn the patient also has "osteoarthritis?" In this paper, we introduce a more general threat model under this weaker assumption and show that fine-tuned LLMs are susceptible to these fragment-specific extraction attacks. To systematically investigate these attacks, we propose two data-blind methods: (1) a likelihood ratio attack inspired by methods from membership inference, and (2) a novel approach, PRISM, which regularizes the ratio by leveraging an external prior. Using examples from both medical and legal settings, we show that both methods are competitive with a data-aware baseline classifier that assumes access to labeled in-distribution data, underscoring their robustness.
ML-EAT: A Multilevel Embedding Association Test for Interpretable and Transparent Social Science
Aug 04, 2024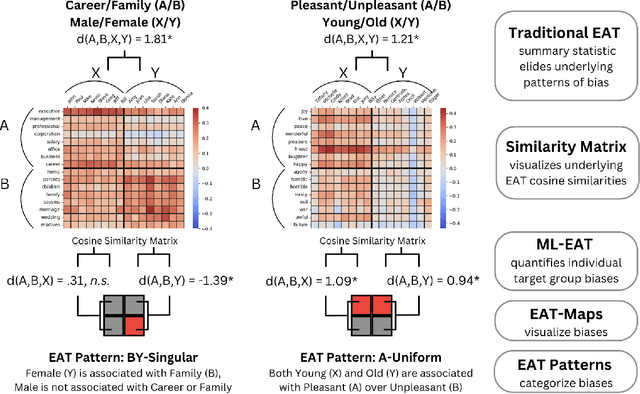
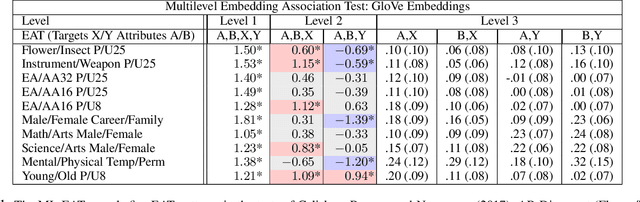
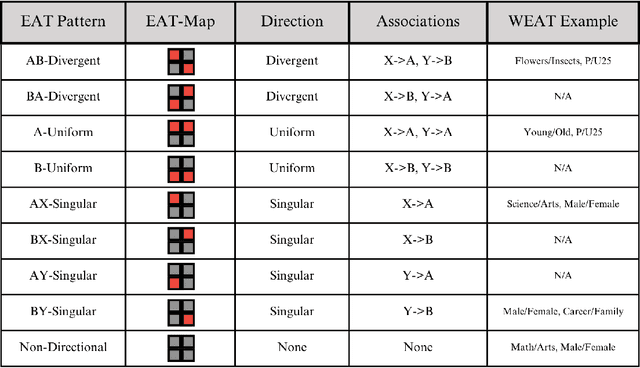
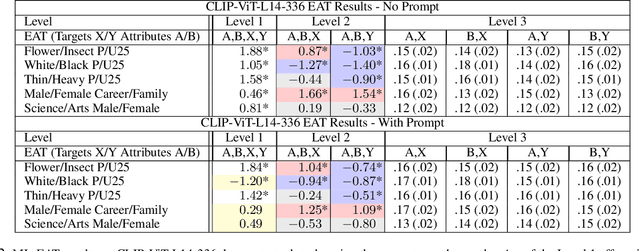
This research introduces the Multilevel Embedding Association Test (ML-EAT), a method designed for interpretable and transparent measurement of intrinsic bias in language technologies. The ML-EAT addresses issues of ambiguity and difficulty in interpreting the traditional EAT measurement by quantifying bias at three levels of increasing granularity: the differential association between two target concepts with two attribute concepts; the individual effect size of each target concept with two attribute concepts; and the association between each individual target concept and each individual attribute concept. Using the ML-EAT, this research defines a taxonomy of EAT patterns describing the nine possible outcomes of an embedding association test, each of which is associated with a unique EAT-Map, a novel four-quadrant visualization for interpreting the ML-EAT. Empirical analysis of static and diachronic word embeddings, GPT-2 language models, and a CLIP language-and-image model shows that EAT patterns add otherwise unobservable information about the component biases that make up an EAT; reveal the effects of prompting in zero-shot models; and can also identify situations when cosine similarity is an ineffective metric, rendering an EAT unreliable. Our work contributes a method for rendering bias more observable and interpretable, improving the transparency of computational investigations into human minds and societies.
Dataset Scale and Societal Consistency Mediate Facial Impression Bias in Vision-Language AI
Aug 04, 2024Multimodal AI models capable of associating images and text hold promise for numerous domains, ranging from automated image captioning to accessibility applications for blind and low-vision users. However, uncertainty about bias has in some cases limited their adoption and availability. In the present work, we study 43 CLIP vision-language models to determine whether they learn human-like facial impression biases, and we find evidence that such biases are reflected across three distinct CLIP model families. We show for the first time that the the degree to which a bias is shared across a society predicts the degree to which it is reflected in a CLIP model. Human-like impressions of visually unobservable attributes, like trustworthiness and sexuality, emerge only in models trained on the largest dataset, indicating that a better fit to uncurated cultural data results in the reproduction of increasingly subtle social biases. Moreover, we use a hierarchical clustering approach to show that dataset size predicts the extent to which the underlying structure of facial impression bias resembles that of facial impression bias in humans. Finally, we show that Stable Diffusion models employing CLIP as a text encoder learn facial impression biases, and that these biases intersect with racial biases in Stable Diffusion XL-Turbo. While pretrained CLIP models may prove useful for scientific studies of bias, they will also require significant dataset curation when intended for use as general-purpose models in a zero-shot setting.
The Implications of Open Generative Models in Human-Centered Data Science Work: A Case Study with Fact-Checking Organizations
Aug 04, 2024Calls to use open generative language models in academic research have highlighted the need for reproducibility and transparency in scientific research. However, the impact of generative AI extends well beyond academia, as corporations and public interest organizations have begun integrating these models into their data science pipelines. We expand this lens to include the impact of open models on organizations, focusing specifically on fact-checking organizations, which use AI to observe and analyze large volumes of circulating misinformation, yet must also ensure the reproducibility and impartiality of their work. We wanted to understand where fact-checking organizations use open models in their data science pipelines; what motivates their use of open models or proprietary models; and how their use of open or proprietary models can inform research on the societal impact of generative AI. To answer these questions, we conducted an interview study with N=24 professionals at 20 fact-checking organizations on six continents. Based on these interviews, we offer a five-component conceptual model of where fact-checking organizations employ generative AI to support or automate parts of their data science pipeline, including Data Ingestion, Data Analysis, Data Retrieval, Data Delivery, and Data Sharing. We then provide taxonomies of fact-checking organizations' motivations for using open models and the limitations that prevent them for further adopting open models, finding that they prefer open models for Organizational Autonomy, Data Privacy and Ownership, Application Specificity, and Capability Transparency. However, they nonetheless use proprietary models due to perceived advantages in Performance, Usability, and Safety, as well as Opportunity Costs related to participation in emerging generative AI ecosystems. Our work provides novel perspective on open models in data-driven organizations.
Representation Bias of Adolescents in AI: A Bilingual, Bicultural Study
Aug 04, 2024Popular and news media often portray teenagers with sensationalism, as both a risk to society and at risk from society. As AI begins to absorb some of the epistemic functions of traditional media, we study how teenagers in two countries speaking two languages: 1) are depicted by AI, and 2) how they would prefer to be depicted. Specifically, we study the biases about teenagers learned by static word embeddings (SWEs) and generative language models (GLMs), comparing these with the perspectives of adolescents living in the U.S. and Nepal. We find English-language SWEs associate teenagers with societal problems, and more than 50% of the 1,000 words most associated with teenagers in the pretrained GloVe SWE reflect such problems. Given prompts about teenagers, 30% of outputs from GPT2-XL and 29% from LLaMA-2-7B GLMs discuss societal problems, most commonly violence, but also drug use, mental illness, and sexual taboo. Nepali models, while not free of such associations, are less dominated by social problems. Data from workshops with N=13 U.S. adolescents and N=18 Nepalese adolescents show that AI presentations are disconnected from teenage life, which revolves around activities like school and friendship. Participant ratings of how well 20 trait words describe teens are decorrelated from SWE associations, with Pearson's r=.02, n.s. in English FastText and r=.06, n.s. in GloVe; and r=.06, n.s. in Nepali FastText and r=-.23, n.s. in GloVe. U.S. participants suggested AI could fairly present teens by highlighting diversity, while Nepalese participants centered positivity. Participants were optimistic that, if it learned from adolescents, rather than media sources, AI could help mitigate stereotypes. Our work offers an understanding of the ways SWEs and GLMs misrepresent a developmentally vulnerable group and provides a template for less sensationalized characterization.
Laboratory-Scale AI: Open-Weight Models are Competitive with ChatGPT Even in Low-Resource Settings
May 27, 2024



The rapid proliferation of generative AI has raised questions about the competitiveness of lower-parameter, locally tunable, open-weight models relative to high-parameter, API-guarded, closed-weight models in terms of performance, domain adaptation, cost, and generalization. Centering under-resourced yet risk-intolerant settings in government, research, and healthcare, we see for-profit closed-weight models as incompatible with requirements for transparency, privacy, adaptability, and standards of evidence. Yet the performance penalty in using open-weight models, especially in low-data and low-resource settings, is unclear. We assess the feasibility of using smaller, open-weight models to replace GPT-4-Turbo in zero-shot, few-shot, and fine-tuned regimes, assuming access to only a single, low-cost GPU. We assess value-sensitive issues around bias, privacy, and abstention on three additional tasks relevant to those topics. We find that with relatively low effort, very low absolute monetary cost, and relatively little data for fine-tuning, small open-weight models can achieve competitive performance in domain-adapted tasks without sacrificing generality. We then run experiments considering practical issues in bias, privacy, and hallucination risk, finding that open models offer several benefits over closed models. We intend this work as a case study in understanding the opportunity cost of reproducibility and transparency over for-profit state-of-the-art zero shot performance, finding this cost to be marginal under realistic settings.