 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Bias is Predicted by Pretraining Data and Correlates with Downstream Performance in Vision-Language Encoders
Feb 11, 2025
While recent work has found that vision-language models trained under the Contrastive Language Image Pre-training (CLIP) framework contain intrinsic social biases, the extent to which different upstream pre-training features of the framework relate to these biases, and hence how intrinsic bias and downstream performance are connected has been unclear. In this work, we present the largest comprehensive analysis to-date of how the upstream pre-training factors and downstream performance of CLIP models relate to their intrinsic biases. Studying 131 unique CLIP models, trained on 26 datasets, using 55 architectures, and in a variety of sizes, we evaluate bias in each model using 26 well-established unimodal and cross-modal principled Embedding Association Tests. We find that the choice of pre-training dataset is the most significant upstream predictor of bias, whereas architectural variations have minimal impact. Additionally, datasets curated using sophisticated filtering techniques aimed at enhancing downstream model performance tend to be associated with higher levels of intrinsic bias. Finally, we observe that intrinsic bias is often significantly correlated with downstream performance ($0.3 \leq r \leq 0.8$), suggesting that models optimized for performance inadvertently learn to amplify representational biases. Comparisons between unimodal and cross-modal association tests reveal that social group bias depends heavily on the modality. Our findings imply that more sophisticated strategies are needed to address intrinsic model bias for vision-language models across the entire model development pipeline.
Laboratory-Scale AI: Open-Weight Models are Competitive with ChatGPT Even in Low-Resource Settings
May 27, 2024



The rapid proliferation of generative AI has raised questions about the competitiveness of lower-parameter, locally tunable, open-weight models relative to high-parameter, API-guarded, closed-weight models in terms of performance, domain adaptation, cost, and generalization. Centering under-resourced yet risk-intolerant settings in government, research, and healthcare, we see for-profit closed-weight models as incompatible with requirements for transparency, privacy, adaptability, and standards of evidence. Yet the performance penalty in using open-weight models, especially in low-data and low-resource settings, is unclear. We assess the feasibility of using smaller, open-weight models to replace GPT-4-Turbo in zero-shot, few-shot, and fine-tuned regimes, assuming access to only a single, low-cost GPU. We assess value-sensitive issues around bias, privacy, and abstention on three additional tasks relevant to those topics. We find that with relatively low effort, very low absolute monetary cost, and relatively little data for fine-tuning, small open-weight models can achieve competitive performance in domain-adapted tasks without sacrificing generality. We then run experiments considering practical issues in bias, privacy, and hallucination risk, finding that open models offer several benefits over closed models. We intend this work as a case study in understanding the opportunity cost of reproducibility and transparency over for-profit state-of-the-art zero shot performance, finding this cost to be marginal under realistic settings.
Pre-trained Speech Processing Models Contain Human-Like Biases that Propagate to Speech Emotion Recognition
Oct 29, 2023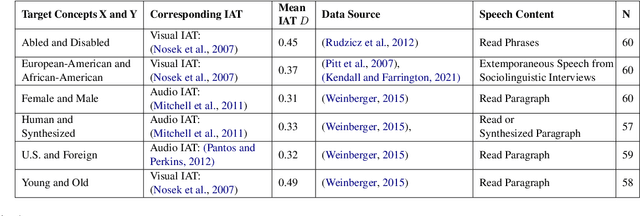
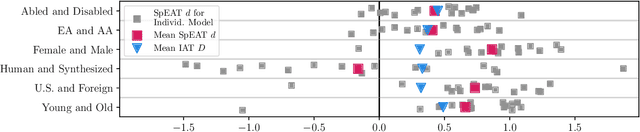
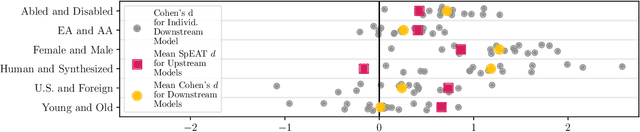
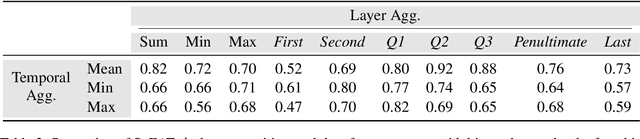
Previous work has established that a person's demographics and speech style affect how well speech processing models perform for them. But where does this bias come from? In this work, we present the Speech Embedding Association Test (SpEAT), a method for detecting bias in one type of model used for many speech tasks: pre-trained models. The SpEAT is inspired by word embedding association tests in natural language processing, which quantify intrinsic bias in a model's representations of different concepts, such as race or valence (something's pleasantness or unpleasantness) and capture the extent to which a model trained on large-scale socio-cultural data has learned human-like biases. Using the SpEAT, we test for six types of bias in 16 English speech models (including 4 models also trained on multilingual data), which come from the wav2vec 2.0, HuBERT, WavLM, and Whisper model families. We find that 14 or more models reveal positive valence (pleasantness) associations with abled people over disabled people, with European-Americans over African-Americans, with females over males, with U.S. accented speakers over non-U.S. accented speakers, and with younger people over older people. Beyond establishing that pre-trained speech models contain these biases, we also show that they can have real world effects. We compare biases found in pre-trained models to biases in downstream models adapted to the task of Speech Emotion Recognition (SER) and find that in 66 of the 96 tests performed (69%), the group that is more associated with positive valence as indicated by the SpEAT also tends to be predicted as speaking with higher valence by the downstream model. Our work provides evidence that, like text and image-based models, pre-trained speech based-models frequently learn human-like biases. Our work also shows that bias found in pre-trained models can propagate to the downstream task of SER.