 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-trained Speech Processing Models Contain Human-Like Biases that Propagate to Speech Emotion Recognition
Paper and Code
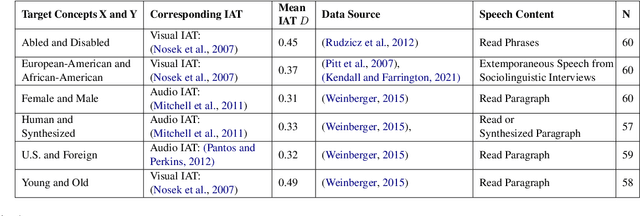
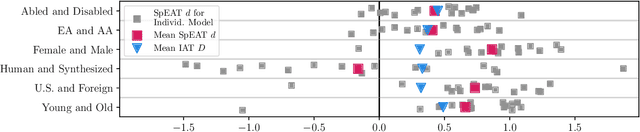
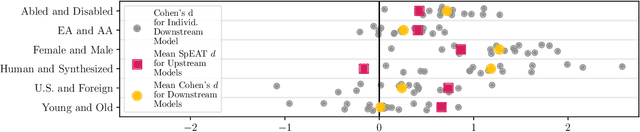
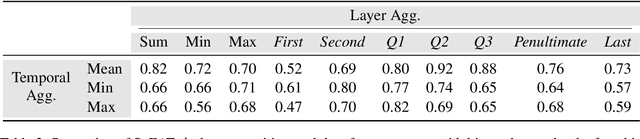
Previous work has established that a person's demographics and speech style affect how well speech processing models perform for them. But where does this bias come from? In this work, we present the Speech Embedding Association Test (SpEAT), a method for detecting bias in one type of model used for many speech tasks: pre-trained models. The SpEAT is inspired by word embedding association tests in natural language processing, which quantify intrinsic bias in a model's representations of different concepts, such as race or valence (something's pleasantness or unpleasantness) and capture the extent to which a model trained on large-scale socio-cultural data has learned human-like biases. Using the SpEAT, we test for six types of bias in 16 English speech models (including 4 models also trained on multilingual data), which come from the wav2vec 2.0, HuBERT, WavLM, and Whisper model families. We find that 14 or more models reveal positive valence (pleasantness) associations with abled people over disabled people, with European-Americans over African-Americans, with females over males, with U.S. accented speakers over non-U.S. accented speakers, and with younger people over older people. Beyond establishing that pre-trained speech models contain these biases, we also show that they can have real world effects. We compare biases found in pre-trained models to biases in downstream models adapted to the task of Speech Emotion Recognition (SER) and find that in 66 of the 96 tests performed (69%), the group that is more associated with positive valence as indicated by the SpEAT also tends to be predicted as speaking with higher valence by the downstream model. Our work provides evidence that, like text and image-based models, pre-trained speech based-models frequently learn human-like biases. Our work also shows that bias found in pre-trained models can propagate to the downstream task of SER.