 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreativity in the Age of AI: Evaluating the Impact of Generative AI on Design Outputs and Designers' Creative Thinking
Oct 31, 2024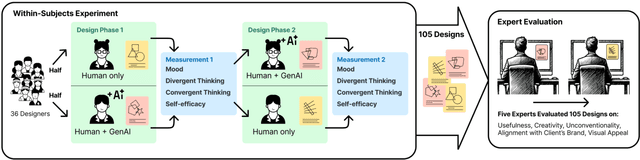

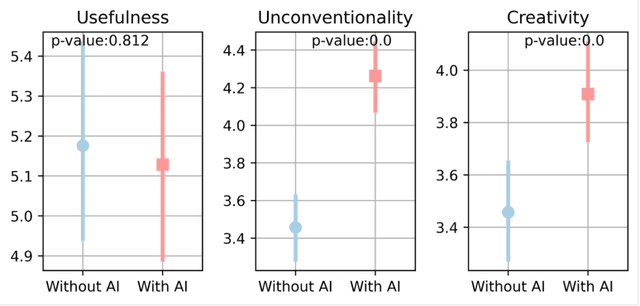
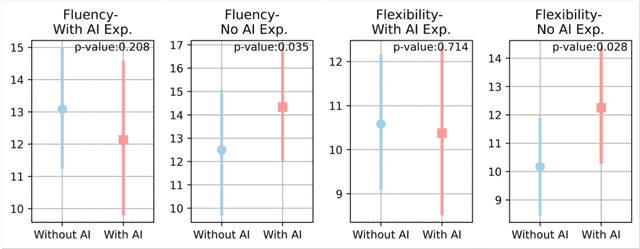
As generative AI (GenAI) increasingly permeates design workflows, its impact on design outcomes and designers' creative capabilities warrants investigation. We conducted a within-subjects experiment where we asked participants to design advertisements both with and without GenAI support. Our results show that expert evaluators rated GenAI-supported designs as more creative and unconventional ("weird") despite no significant differences in visual appeal, brand alignment, or usefulness, which highlights the decoupling of novelty from usefulness-traditional dual components of creativity-in the context of GenAI usage. Moreover, while GenAI does not significantly enhance designers' overall creative thinking abilities, users were affected differently based on native language and prior AI exposure. Native English speakers experienced reduced relaxation when using AI, whereas designers new to GenAI exhibited gains in divergent thinking, such as idea fluency and flexibility. These findings underscore the variable impact of GenAI on different user groups, suggesting the potential for customized AI tools.
ML-EAT: A Multilevel Embedding Association Test for Interpretable and Transparent Social Science
Aug 04, 2024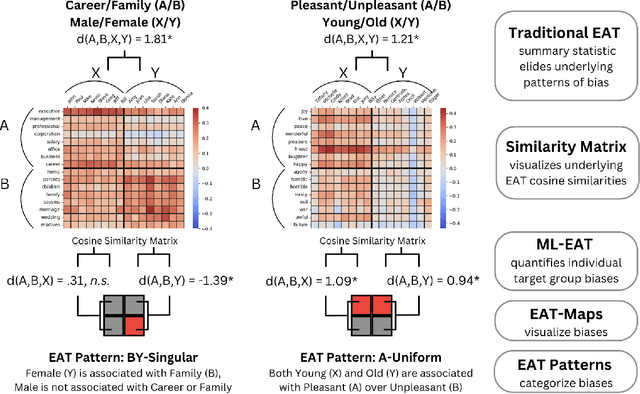
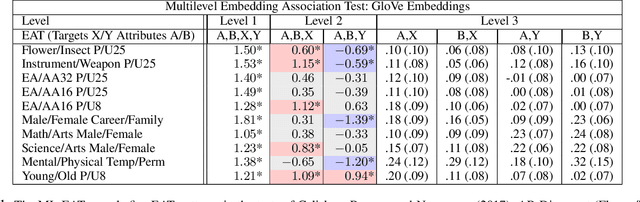
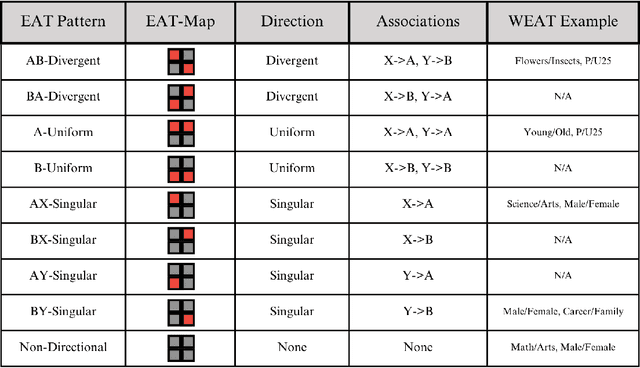
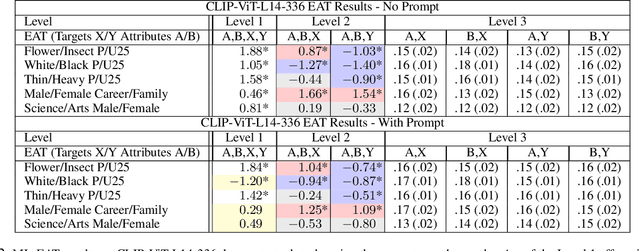
This research introduces the Multilevel Embedding Association Test (ML-EAT), a method designed for interpretable and transparent measurement of intrinsic bias in language technologies. The ML-EAT addresses issues of ambiguity and difficulty in interpreting the traditional EAT measurement by quantifying bias at three levels of increasing granularity: the differential association between two target concepts with two attribute concepts; the individual effect size of each target concept with two attribute concepts; and the association between each individual target concept and each individual attribute concept. Using the ML-EAT, this research defines a taxonomy of EAT patterns describing the nine possible outcomes of an embedding association test, each of which is associated with a unique EAT-Map, a novel four-quadrant visualization for interpreting the ML-EAT. Empirical analysis of static and diachronic word embeddings, GPT-2 language models, and a CLIP language-and-image model shows that EAT patterns add otherwise unobservable information about the component biases that make up an EAT; reveal the effects of prompting in zero-shot models; and can also identify situations when cosine similarity is an ineffective metric, rendering an EAT unreliable. Our work contributes a method for rendering bias more observable and interpretable, improving the transparency of computational investigations into human minds and societies.
Dataset Scale and Societal Consistency Mediate Facial Impression Bias in Vision-Language AI
Aug 04, 2024Multimodal AI models capable of associating images and text hold promise for numerous domains, ranging from automated image captioning to accessibility applications for blind and low-vision users. However, uncertainty about bias has in some cases limited their adoption and availability. In the present work, we study 43 CLIP vision-language models to determine whether they learn human-like facial impression biases, and we find evidence that such biases are reflected across three distinct CLIP model families. We show for the first time that the the degree to which a bias is shared across a society predicts the degree to which it is reflected in a CLIP model. Human-like impressions of visually unobservable attributes, like trustworthiness and sexuality, emerge only in models trained on the largest dataset, indicating that a better fit to uncurated cultural data results in the reproduction of increasingly subtle social biases. Moreover, we use a hierarchical clustering approach to show that dataset size predicts the extent to which the underlying structure of facial impression bias resembles that of facial impression bias in humans. Finally, we show that Stable Diffusion models employing CLIP as a text encoder learn facial impression biases, and that these biases intersect with racial biases in Stable Diffusion XL-Turbo. While pretrained CLIP models may prove useful for scientific studies of bias, they will also require significant dataset curation when intended for use as general-purpose models in a zero-shot setting.
Representation Bias of Adolescents in AI: A Bilingual, Bicultural Study
Aug 04, 2024Popular and news media often portray teenagers with sensationalism, as both a risk to society and at risk from society. As AI begins to absorb some of the epistemic functions of traditional media, we study how teenagers in two countries speaking two languages: 1) are depicted by AI, and 2) how they would prefer to be depicted. Specifically, we study the biases about teenagers learned by static word embeddings (SWEs) and generative language models (GLMs), comparing these with the perspectives of adolescents living in the U.S. and Nepal. We find English-language SWEs associate teenagers with societal problems, and more than 50% of the 1,000 words most associated with teenagers in the pretrained GloVe SWE reflect such problems. Given prompts about teenagers, 30% of outputs from GPT2-XL and 29% from LLaMA-2-7B GLMs discuss societal problems, most commonly violence, but also drug use, mental illness, and sexual taboo. Nepali models, while not free of such associations, are less dominated by social problems. Data from workshops with N=13 U.S. adolescents and N=18 Nepalese adolescents show that AI presentations are disconnected from teenage life, which revolves around activities like school and friendship. Participant ratings of how well 20 trait words describe teens are decorrelated from SWE associations, with Pearson's r=.02, n.s. in English FastText and r=.06, n.s. in GloVe; and r=.06, n.s. in Nepali FastText and r=-.23, n.s. in GloVe. U.S. participants suggested AI could fairly present teens by highlighting diversity, while Nepalese participants centered positivity. Participants were optimistic that, if it learned from adolescents, rather than media sources, AI could help mitigate stereotypes. Our work offers an understanding of the ways SWEs and GLMs misrepresent a developmentally vulnerable group and provides a template for less sensationalized characterization.
Should ChatGPT Write Your Breakup Text? Exploring the Role of AI in Relationship Dissolution
Jan 18, 2024

Relationships are essential to our happiness and wellbeing. The dissolution of a relationship, the final stage of relationship's lifecycle and one of the most stressful events in an individual's life, can have profound and long-lasting impacts on people. With the breakup process increasingly facilitated by computer-mediated communication (CMC), and the likely future influence of AI-mediated communication (AIMC) tools, we conducted a semi-structured interview study with 21 participants. We aim to understand: 1) the current role of technology in the breakup process, 2) the needs and support individuals have during the process, and 3) how AI might address these needs. Our research shows that people have distinct needs at various stages of ending a relationship. Presently, technology is used for information gathering and community support, acting as a catalyst for breakups, enabling ghosting and blocking, and facilitating communication. Participants anticipate that AI could aid in sense-making of their relationship leading up to the breakup, act as a mediator, assist in crafting appropriate wording, tones, and language during breakup conversations, and support companionship, reflection, recovery, and growth after a breakup. Our findings also demonstrate an overlap between the breakup process and the Transtheoretical Model (TTM) of behavior change. Through the lens of TTM, we explore the potential support and affordances AI could offer in breakups, including its benefits and the necessary precautions regarding AI's role in this sensitive process.