 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Biased Attitude Associations of Language Models in an Intersectional Context
Jul 07, 2023Language models are trained on large-scale corpora that embed implicit biases documented in psychology. Valence associations (pleasantness/unpleasantness) of social groups determine the biased attitudes towards groups and concepts in social cognition. Building on this established literature, we quantify how social groups are valenced in English language models using a sentence template that provides an intersectional context. We study biases related to age, education, gender, height, intelligence, literacy, race, religion, sex, sexual orientation, social class, and weight. We present a concept projection approach to capture the valence subspace through contextualized word embeddings of language models. Adapting the projection-based approach to embedding association tests that quantify bias, we find that language models exhibit the most biased attitudes against gender identity, social class, and sexual orientation signals in language. We find that the largest and better-performing model that we study is also more biased as it effectively captures bias embedded in sociocultural data. We validate the bias evaluation method by overperforming on an intrinsic valence evaluation task. The approach enables us to measure complex intersectional biases as they are known to manifest in the outputs and applications of language models that perpetuate historical biases. Moreover, our approach contributes to design justice as it studies the associations of groups underrepresented in language such as transgender and homosexual individuals.
Measuring Gender Bias in Word Embeddings of Gendered Languages Requires Disentangling Grammatical Gender Signals
Jun 03, 2022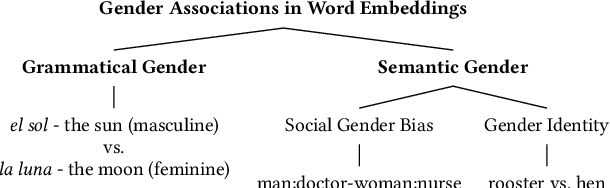

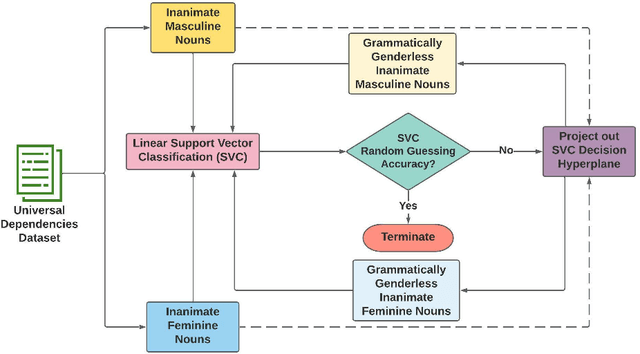
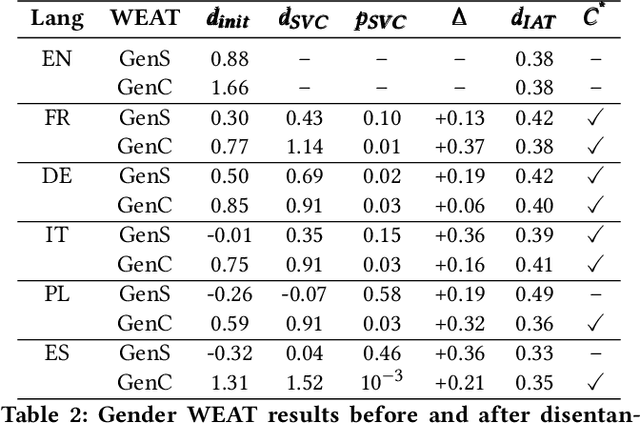
Does the grammatical gender of a language interfere when measuring the semantic gender information captured by its word embeddings? A number of anomalous gender bias measurements in the embeddings of gendered languages suggest this possibility. We demonstrate that word embeddings learn the association between a noun and its grammatical gender in grammatically gendered languages, which can skew social gender bias measurements. Consequently, word embedding post-processing methods are introduced to quantify, disentangle, and evaluate grammatical gender signals. The evaluation is performed on five gendered languages from the Germanic, Romance, and Slavic branches of the Indo-European language family. Our method reduces the strength of grammatical gender signals, which is measured in terms of effect size (Cohen's d), by a significant average of d = 1.3 for French, German, and Italian, and d = 0.56 for Polish and Spanish. Once grammatical gender is disentangled, the association between over 90% of 10,000 inanimate nouns and their assigned grammatical gender weakens, and cross-lingual bias results from the Word Embedding Association Test (WEAT) become more congruent with country-level implicit bias measurements. The results further suggest that disentangling grammatical gender signals from word embeddings may lead to improvement in semantic machine learning tasks.