 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking MoE-based LLM Inference Resilient with Tarragon
Jan 06, 2026Mixture-of-Experts (MoE) models are increasingly used to serve LLMs at scale, but failures become common as deployment scale grows. Existing systems exhibit poor failure resilience: even a single worker failure triggers a coarse-grained, service-wide restart, discarding accumulated progress and halting the entire inference pipeline during recovery--an approach clearly ill-suited for latency-sensitive, LLM services. We present Tarragon, a resilient MoE inference framework that confines the failures impact to individual workers while allowing the rest of the pipeline to continue making forward progress. Tarragon exploits the natural separation between the attention and expert computation in MoE-based transformers, treating attention workers (AWs) and expert workers (EWs) as distinct failure domains. Tarragon introduces a reconfigurable datapath to mask failures by rerouting requests to healthy workers. On top of this datapath, Tarragon implements a self-healing mechanism that relaxes the tightly synchronized execution of existing MoE frameworks. For stateful AWs, Tarragon performs asynchronous, incremental KV cache checkpointing with per-request restoration, and for stateless EWs, it leverages residual GPU memory to deploy shadow experts. These together keep recovery cost and recomputation overhead extremely low. Our evaluation shows that, compared to state-of-the-art MegaScale-Infer, Tarragon reduces failure-induced stalls by 160-213x (from ~64 s down to 0.3-0.4 s) while preserving performance when no failures occur.
An Algorithmic Equity Toolkit for Technology Audits by Community Advocates and Activists
Dec 06, 2019
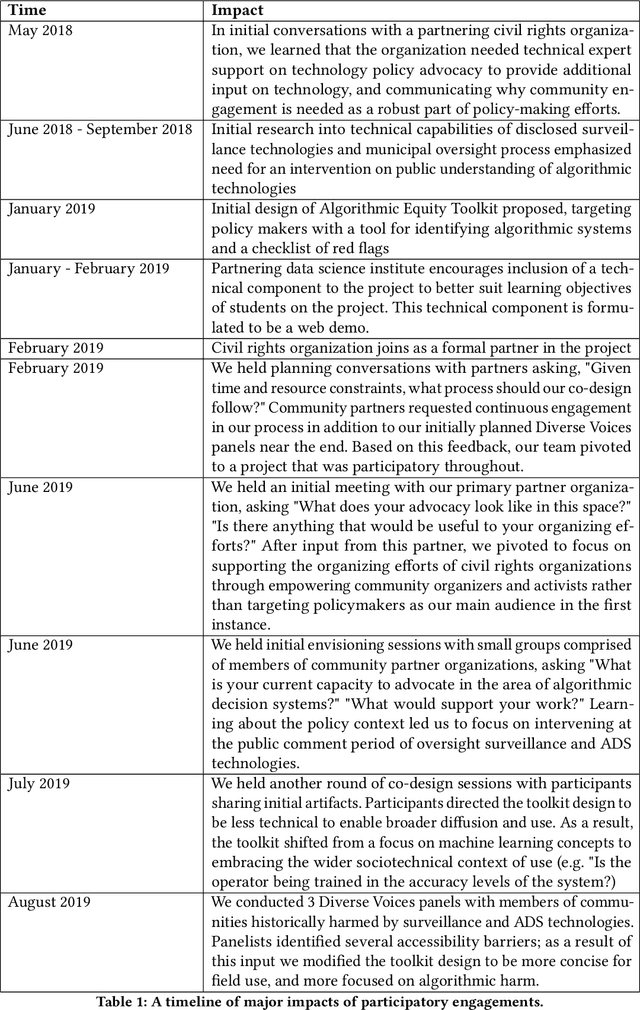
A wave of recent scholarship documenting the discriminatory harms of algorithmic systems has spurred widespread interest in algorithmic accountability and regulation. Yet effective accountability and regulation is stymied by a persistent lack of resources supporting public understanding of algorithms and artificial intelligence. Through interactions with a US-based civil rights organization and their coalition of community organizations, we identify a need for (i) heuristics that aid stakeholders in distinguishing between types of analytic and information systems in lay language, and (ii) risk assessment tools for such systems that begin by making algorithms more legible. The present work delivers a toolkit to achieve these aims. This paper both presents the Algorithmic Equity Toolkit (AEKit) Equity as an artifact, and details how our participatory process shaped its design. Our work fits within human-computer interaction scholarship as a demonstration of the value of HCI methods and approaches to problems in the area of algorithmic transparency and accountability.