 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLine-of-Sight-Constrained Multi-Robot Mapless Navigation via Polygonal Visible Regions
Mar 27, 2026Multi-robot systems rely on underlying connectivity to ensure reliable communication and timely coordination. This paper studies the line-of-sight (LoS) connectivity maintenance problem in multi-robot navigation with unknown obstacles. Prior works typically assume known environment maps to formulate LoS constraints between robots, which hinders their practical deployment. To overcome this limitation, we propose an inherently distributed approach where each robot only constructs an egocentric visible region based on its real-time LiDAR scans, instead of endeavoring to build a global map online. The individual visible regions are shared through distributed communication to establish inter-robot LoS constraints, which are then incorporated into a multi-robot navigation framework to ensure LoS-connectivity. Moreover, we enhance the robustness of connectivity maintenance by proposing a more accurate LoS-distance metric, which further enables flexible topology optimization that eliminates redundant and effort-demanding connections. The proposed framework is evaluated through extensive multi-robot navigation and exploration tasks in both simulation and real-world experiments. Results show that it reliably maintains LoS-connectivity between robots in challenging environments cluttered with obstacles, even under large visible ranges and fragile minimal topologies, where existing methods consistently fail. Ablation studies also reveal that topology optimization boosts navigation efficiency by around $20\%$, demonstrating the framework's potential for efficient navigation under connectivity constraints.
Towards Human-Like Manipulation through RL-Augmented Teleoperation and Mixture-of-Dexterous-Experts VLA
Mar 09, 2026While Vision-Language-Action (VLA) models have demonstrated remarkable success in robotic manipulation, their application has largely been confined to low-degree-of-freedom end-effectors performing simple, vision-guided pick-and-place tasks. Extending these models to human-like, bimanual dexterous manipulation-specifically contact-rich in-hand operations-introduces critical challenges in high-fidelity data acquisition, multi-skill learning, and multimodal sensory fusion. In this paper, we propose an integrated framework to address these bottlenecks, built upon two components. First, we introduce IMCopilot (In-hand Manipulation Copilot), a suite of reinforcement learning-trained atomic skills that plays a dual role: it acts as a shared-autonomy assistant to simplify teleoperation data collection, and it serves as a callable low-level execution primitive for the VLA. Second, we present MoDE-VLA (Mixture-of-Dexterous-Experts VLA), an architecture that seamlessly integrates heterogeneous force and tactile modalities into a pretrained VLA backbone. By utilizing a residual injection mechanism, MoDE-VLA enables contact-aware refinement without degrading the model's pretrained knowledge. We validate our approach on four tasks of escalating complexity, demonstrating doubled success rate improvement over the baseline in dexterous contact-rich tasks.
Stereo-Inertial Poser: Towards Metric-Accurate Shape-Aware Motion Capture Using Sparse IMUs and a Single Stereo Camera
Mar 02, 2026Recent advancements in visual-inertial motion capture systems have demonstrated the potential of combining monocular cameras with sparse inertial measurement units (IMUs) as cost-effective solutions, which effectively mitigate occlusion and drift issues inherent in single-modality systems. However, they are still limited by metric inaccuracies in global translations stemming from monocular depth ambiguity, and shape-agnostic local motion estimations that ignore anthropometric variations. We present Stereo-Inertial Poser, a real-time motion capture system that leverages a single stereo camera and six IMUs to estimate metric-accurate and shape-aware 3D human motion. By replacing the monocular RGB with stereo vision, our system resolves depth ambiguity through calibrated baseline geometry, enabling direct 3D keypoint extraction and body shape parameter estimation. IMU data and visual cues are fused for predicting drift-compensated joint positions and root movements, while a novel shape-aware fusion module dynamically harmonizes anthropometry variations with global translations. Our end-to-end pipeline achieves over 200 FPS without optimization-based post-processing, enabling real-time deployment. Quantitative evaluations across various datasets demonstrate state-of-the-art performance. Qualitative results show our method produces drift-free global translation under a long recording time and reduces foot-skating effects.
TARGET: Benchmarking Table Retrieval for Generative Tasks
May 14, 2025The data landscape is rich with structured data, often of high value to organizations, driving important applications in data analysis and machine learning. Recent progress in representation learning and generative models for such data has led to the development of natural language interfaces to structured data, including those leveraging text-to-SQL. Contextualizing interactions, either through conversational interfaces or agentic components, in structured data through retrieval-augmented generation can provide substantial benefits in the form of freshness, accuracy, and comprehensiveness of answers. The key question is: how do we retrieve the right table(s) for the analytical query or task at hand? To this end, we introduce TARGET: a benchmark for evaluating TAble Retrieval for GEnerative Tasks. With TARGET we analyze the retrieval performance of different retrievers in isolation, as well as their impact on downstream tasks. We find that dense embedding-based retrievers far outperform a BM25 baseline which is less effective than it is for retrieval over unstructured text. We also surface the sensitivity of retrievers across various metadata (e.g., missing table titles), and demonstrate a stark variation of retrieval performance across datasets and tasks. TARGET is available at https://target-benchmark.github.io.
CSGDN: Contrastive Signed Graph Diffusion Network for Predicting Crop Gene-Trait Associations
Oct 10, 2024


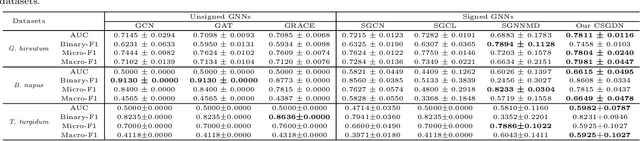
Positive and negative association preidiction between gene and trait help studies for crops to perform complex physiological functions. The transcription and regulation activity of specific genes will be adjusted accordingly in different cell types, developmental stages, and physiological states to meet the needs of organisms. Determing gene-trait associations can resolve the mechanism of trait formation and benefit the improvement of crop yield and quality. There are the following two problems in obtaining the positive/negative associations between gene and trait: 1) High-throughput DNA/RNA sequencing and trait data collection are expensive and time-consuming due to the need to process large sample sizes; 2) experiments introduce both random and systematic errors, and, at the same time, calculations or predictions using software or models may produce noise. To address these two issues, we propose a Contrastive Signed Graph Diffusion Network, CSGDN, to learn robust node representations with fewer training samples to achieve higher link prediction accuracy. CSGDN employs a signed graph diffusion method to uncover the underlying regulatory associations between genes and traits. Then, stochastic perterbation strategies are used to create two views for both original and diffusive graphs. At last, a multi-view contrastive learning paradigm loss is designed to unify the node presentations learned from the two views to resist interference and reduce noise. We conduct experiments to validate the performance of CSGDN on three crop datasets: Gossypium hirsutum, Brassica napus, and Triticum turgidum. The results demonstrate that the proposed model outperforms state-of-the-art methods by up to 9.28% AUC for link sign prediction in G. hirsutum dataset.
Verbalized Graph Representation Learning: A Fully Interpretable Graph Model Based on Large Language Models Throughout the Entire Process
Oct 02, 2024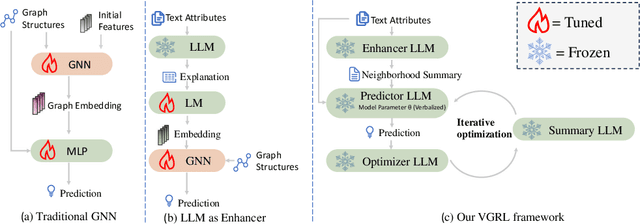

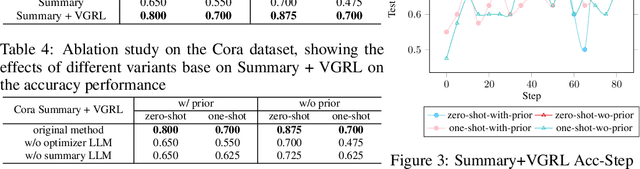

Representation learning on text-attributed graphs (TAGs) has attracted significant interest due to its wide-ranging real-world applications, particularly through Graph Neural Networks (GNNs). Traditional GNN methods focus on encoding the structural information of graphs, often using shallow text embeddings for node or edge attributes. This limits the model to understand the rich semantic information in the data and its reasoning ability for complex downstream tasks, while also lacking interpretability. With the rise of large language models (LLMs), an increasing number of studies are combining them with GNNs for graph representation learning and downstream tasks. While these approaches effectively leverage the rich semantic information in TAGs datasets, their main drawback is that they are only partially interpretable, which limits their application in critical fields. In this paper, we propose a verbalized graph representation learning (VGRL) method which is fully interpretable. In contrast to traditional graph machine learning models, which are usually optimized within a continuous parameter space, VGRL constrains this parameter space to be text description which ensures complete interpretability throughout the entire process, making it easier for users to understand and trust the decisions of the model. We conduct several studies to empirically evaluate the effectiveness of VGRL and we believe these method can serve as a stepping stone in graph representation learning.
SGBA: Semantic Gaussian Mixture Model-Based LiDAR Bundle Adjustment
Oct 02, 2024LiDAR bundle adjustment (BA) is an effective approach to reduce the drifts in pose estimation from the front-end. Existing works on LiDAR BA usually rely on predefined geometric features for landmark representation. This reliance restricts generalizability, as the system will inevitably deteriorate in environments where these specific features are absent. To address this issue, we propose SGBA, a LiDAR BA scheme that models the environment as a semantic Gaussian mixture model (GMM) without predefined feature types. This approach encodes both geometric and semantic information, offering a comprehensive and general representation adaptable to various environments. Additionally, to limit computational complexity while ensuring generalizability, we propose an adaptive semantic selection framework that selects the most informative semantic clusters for optimization by evaluating the condition number of the cost function. Lastly, we introduce a probabilistic feature association scheme that considers the entire probability density of assignments, which can manage uncertainties in measurement and initial pose estimation. We have conducted various experiments and the results demonstrate that SGBA can achieve accurate and robust pose refinement even in challenging scenarios with low-quality initial pose estimation and limited geometric features. We plan to open-source the work for the benefit of the community https://github.com/Ji1Xinyu/SGBA.
SE-SGformer: A Self-Explainable Signed Graph Transformer for Link Sign Prediction
Aug 16, 2024
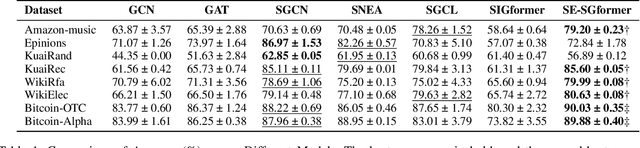
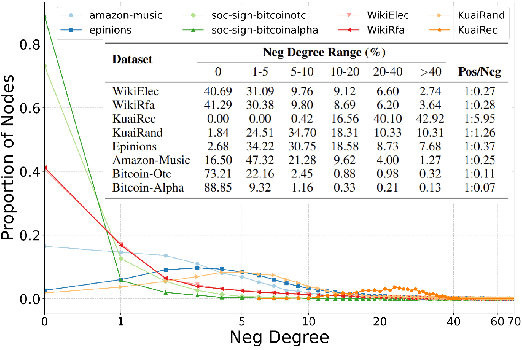
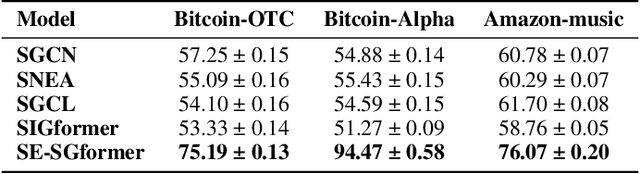
Signed Graph Neural Networks (SGNNs) have been shown to be effective in analyzing complex patterns in real-world situations where positive and negative links coexist. However, SGNN models suffer from poor explainability, which limit their adoptions in critical scenarios that require understanding the rationale behind predictions. To the best of our knowledge, there is currently no research work on the explainability of the SGNN models. Our goal is to address the explainability of decision-making for the downstream task of link sign prediction specific to signed graph neural networks. Since post-hoc explanations are not derived directly from the models, they may be biased and misrepresent the true explanations. Therefore, in this paper we introduce a Self-Explainable Signed Graph transformer (SE-SGformer) framework, which can not only outputs explainable information while ensuring high prediction accuracy. Specifically, We propose a new Transformer architecture for signed graphs and theoretically demonstrate that using positional encoding based on signed random walks has greater expressive power than current SGNN methods and other positional encoding graph Transformer-based approaches. We constructs a novel explainable decision process by discovering the $K$-nearest (farthest) positive (negative) neighbors of a node to replace the neural network-based decoder for predicting edge signs. These $K$ positive (negative) neighbors represent crucial information about the formation of positive (negative) edges between nodes and thus can serve as important explanatory information in the decision-making process. We conducted experiments on several real-world datasets to validate the effectiveness of SE-SGformer, which outperforms the state-of-the-art methods by improving 2.2\% prediction accuracy and 73.1\% explainablity accuracy in the best-case scenario.
Reliable Spatial-Temporal Voxels For Multi-Modal Test-Time Adaptation
Mar 15, 2024Multi-modal test-time adaptation (MM-TTA) is proposed to adapt models to an unlabeled target domain by leveraging the complementary multi-modal inputs in an online manner. Previous MM-TTA methods rely on predictions of cross-modal information in each input frame, while they ignore the fact that predictions of geometric neighborhoods within consecutive frames are highly correlated, leading to unstable predictions across time. To fulfill this gap, we propose ReLiable Spatial-temporal Voxels (Latte), an MM-TTA method that leverages reliable cross-modal spatial-temporal correspondences for multi-modal 3D segmentation. Motivated by the fact that reliable predictions should be consistent with their spatial-temporal correspondences, Latte aggregates consecutive frames in a slide window manner and constructs ST voxel to capture temporally local prediction consistency for each modality. After filtering out ST voxels with high ST entropy, Latte conducts cross-modal learning for each point and pixel by attending to those with reliable and consistent predictions among both spatial and temporal neighborhoods. Experimental results show that Latte achieves state-of-the-art performance on three different MM-TTA benchmarks compared to previous MM-TTA or TTA methods.
Multipath Time-delay Estimation with Impulsive Noise via Bayesian Compressive Sensing
Jul 05, 2023Multipath time-delay estimation is commonly encountered in radar and sonar signal processing. In some real-life environments, impulse noise is ubiquitous and significantly degrades estimation performance. Here, we propose a Bayesian approach to tailor the Bayesian Compressive Sensing (BCS) to mitigate impulsive noises. In particular, a heavy-tail Laplacian distribution is used as a statistical model for impulse noise, while Laplacian prior is used for sparse multipath modeling. The Bayesian learning problem contains hyperparameters learning and parameter estimation, solved under the BCS inference framework. The performance of our proposed method is compared with benchmark methods, including compressive sensing (CS), BCS, and Laplacian-prior BCS (L-BCS). The simulation results show that our proposed method can estimate the multipath parameters more accurately and have a lower root mean squared estimation error (RMSE) in intensely impulsive noise.