 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy GNNs with LLMs: A Systematic Review and Taxonomy
Feb 12, 2025With the extensive application of Graph Neural Networks (GNNs) across various domains, their trustworthiness has emerged as a focal point of research. Some existing studies have shown that the integration of large language models (LLMs) can improve the semantic understanding and generation capabilities of GNNs, which in turn improves the trustworthiness of GNNs from various aspects. Our review introduces a taxonomy that offers researchers a clear framework for comprehending the principles and applications of different methods and helps clarify the connections and differences among various approaches. Then we systematically survey representative approaches along the four categories of our taxonomy. Through our taxonomy, researchers can understand the applicable scenarios, potential advantages, and limitations of each approach for the the trusted integration of GNNs with LLMs. Finally, we present some promising directions of work and future trends for the integration of LLMs and GNNs to improve model trustworthiness.
CSGDN: Contrastive Signed Graph Diffusion Network for Predicting Crop Gene-Trait Associations
Oct 10, 2024


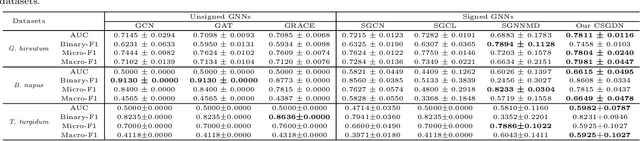
Positive and negative association preidiction between gene and trait help studies for crops to perform complex physiological functions. The transcription and regulation activity of specific genes will be adjusted accordingly in different cell types, developmental stages, and physiological states to meet the needs of organisms. Determing gene-trait associations can resolve the mechanism of trait formation and benefit the improvement of crop yield and quality. There are the following two problems in obtaining the positive/negative associations between gene and trait: 1) High-throughput DNA/RNA sequencing and trait data collection are expensive and time-consuming due to the need to process large sample sizes; 2) experiments introduce both random and systematic errors, and, at the same time, calculations or predictions using software or models may produce noise. To address these two issues, we propose a Contrastive Signed Graph Diffusion Network, CSGDN, to learn robust node representations with fewer training samples to achieve higher link prediction accuracy. CSGDN employs a signed graph diffusion method to uncover the underlying regulatory associations between genes and traits. Then, stochastic perterbation strategies are used to create two views for both original and diffusive graphs. At last, a multi-view contrastive learning paradigm loss is designed to unify the node presentations learned from the two views to resist interference and reduce noise. We conduct experiments to validate the performance of CSGDN on three crop datasets: Gossypium hirsutum, Brassica napus, and Triticum turgidum. The results demonstrate that the proposed model outperforms state-of-the-art methods by up to 9.28% AUC for link sign prediction in G. hirsutum dataset.
Verbalized Graph Representation Learning: A Fully Interpretable Graph Model Based on Large Language Models Throughout the Entire Process
Oct 02, 2024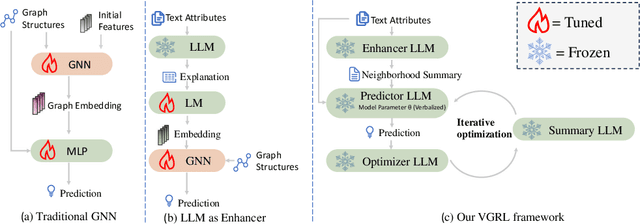

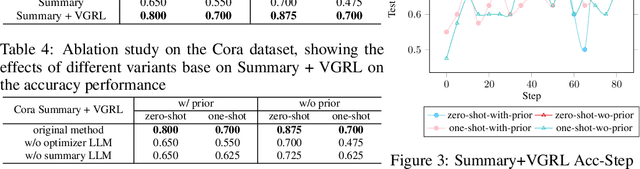

Representation learning on text-attributed graphs (TAGs) has attracted significant interest due to its wide-ranging real-world applications, particularly through Graph Neural Networks (GNNs). Traditional GNN methods focus on encoding the structural information of graphs, often using shallow text embeddings for node or edge attributes. This limits the model to understand the rich semantic information in the data and its reasoning ability for complex downstream tasks, while also lacking interpretability. With the rise of large language models (LLMs), an increasing number of studies are combining them with GNNs for graph representation learning and downstream tasks. While these approaches effectively leverage the rich semantic information in TAGs datasets, their main drawback is that they are only partially interpretable, which limits their application in critical fields. In this paper, we propose a verbalized graph representation learning (VGRL) method which is fully interpretable. In contrast to traditional graph machine learning models, which are usually optimized within a continuous parameter space, VGRL constrains this parameter space to be text description which ensures complete interpretability throughout the entire process, making it easier for users to understand and trust the decisions of the model. We conduct several studies to empirically evaluate the effectiveness of VGRL and we believe these method can serve as a stepping stone in graph representation learning.
Mitigating Degree Bias in Signed Graph Neural Networks
Aug 16, 2024Like Graph Neural Networks (GNNs), Signed Graph Neural Networks (SGNNs) are also up against fairness issues from source data and typical aggregation method. In this paper, we are pioneering to make the investigation of fairness in SGNNs expanded from GNNs. We identify the issue of degree bias within signed graphs, offering a new perspective on the fairness issues related to SGNNs. To handle the confronted bias issue, inspired by previous work on degree bias, a new Model-Agnostic method is consequently proposed to enhance representation of nodes with different degrees, which named as Degree Debiased Signed Graph Neural Network (DD-SGNN) . More specifically, in each layer, we make a transfer from nodes with high degree to nodes with low degree inside a head-to-tail triplet, which to supplement the underlying domain missing structure of the tail nodes and meanwhile maintain the positive and negative semantics specified by balance theory in signed graphs. We make extensive experiments on four real-world datasets. The result verifies the validity of the model, that is, our model mitigates the degree bias issue without compromising performance($\textit{i.e.}$, AUC, F1). The code is provided in supplementary material.
SE-SGformer: A Self-Explainable Signed Graph Transformer for Link Sign Prediction
Aug 16, 2024
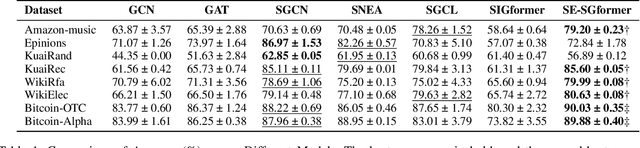
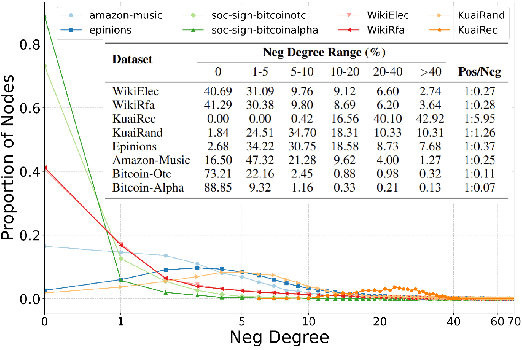
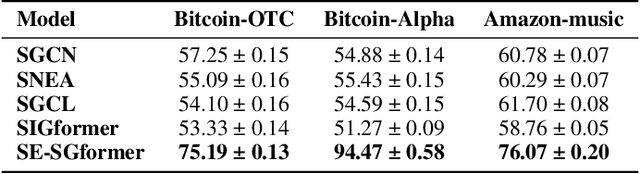
Signed Graph Neural Networks (SGNNs) have been shown to be effective in analyzing complex patterns in real-world situations where positive and negative links coexist. However, SGNN models suffer from poor explainability, which limit their adoptions in critical scenarios that require understanding the rationale behind predictions. To the best of our knowledge, there is currently no research work on the explainability of the SGNN models. Our goal is to address the explainability of decision-making for the downstream task of link sign prediction specific to signed graph neural networks. Since post-hoc explanations are not derived directly from the models, they may be biased and misrepresent the true explanations. Therefore, in this paper we introduce a Self-Explainable Signed Graph transformer (SE-SGformer) framework, which can not only outputs explainable information while ensuring high prediction accuracy. Specifically, We propose a new Transformer architecture for signed graphs and theoretically demonstrate that using positional encoding based on signed random walks has greater expressive power than current SGNN methods and other positional encoding graph Transformer-based approaches. We constructs a novel explainable decision process by discovering the $K$-nearest (farthest) positive (negative) neighbors of a node to replace the neural network-based decoder for predicting edge signs. These $K$ positive (negative) neighbors represent crucial information about the formation of positive (negative) edges between nodes and thus can serve as important explanatory information in the decision-making process. We conducted experiments on several real-world datasets to validate the effectiveness of SE-SGformer, which outperforms the state-of-the-art methods by improving 2.2\% prediction accuracy and 73.1\% explainablity accuracy in the best-case scenario.