 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulco: Recognizing Chinese Nested Named Entities Through Multiple Scopes
Paper and Code
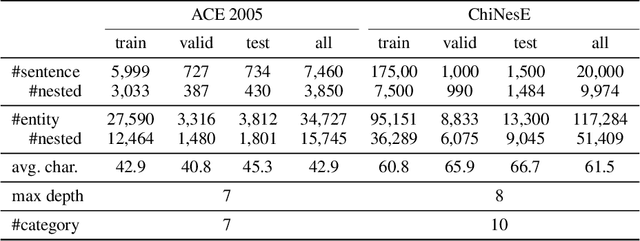
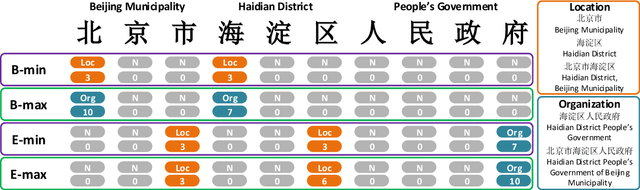
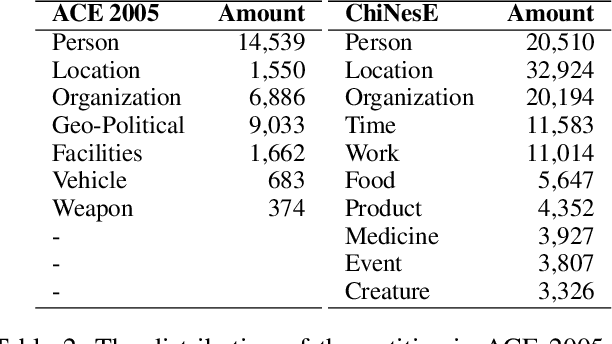
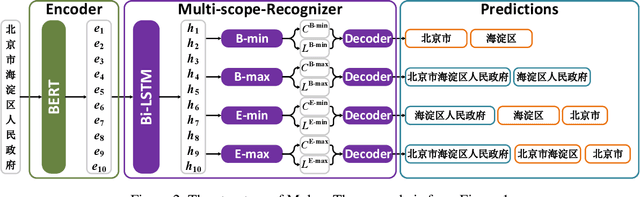
Nested Named Entity Recognition (NNER) has been a long-term challenge to researchers as an important sub-area of Named Entity Recognition. NNER is where one entity may be part of a longer entity, and this may happen on multiple levels, as the term nested suggests. These nested structures make traditional sequence labeling methods unable to properly recognize all entities. While recent researches focus on designing better recognition methods for NNER in a variety of languages, the Chinese NNER (CNNER) still lacks attention, where a free-for-access, CNNER-specialized benchmark is absent. In this paper, we aim to solve CNNER problems by providing a Chinese dataset and a learning-based model to tackle the issue. To facilitate the research on this task, we release ChiNesE, a CNNER dataset with 20,000 sentences sampled from online passages of multiple domains, containing 117,284 entities failing in 10 categories, where 43.8 percent of those entities are nested. Based on ChiNesE, we propose Mulco, a novel method that can recognize named entities in nested structures through multiple scopes. Each scope use a designed scope-based sequence labeling method, which predicts an anchor and the length of a named entity to recognize it. Experiment results show that Mulco has outperformed several baseline methods with the different recognizing schemes on ChiNesE. We also conduct extensive experiments on ACE2005 Chinese corpus, where Mulco has achieved the best performance compared with the baseline methods.