 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEA-BED: Southeast Asia Embedding Benchmark
Aug 17, 2025
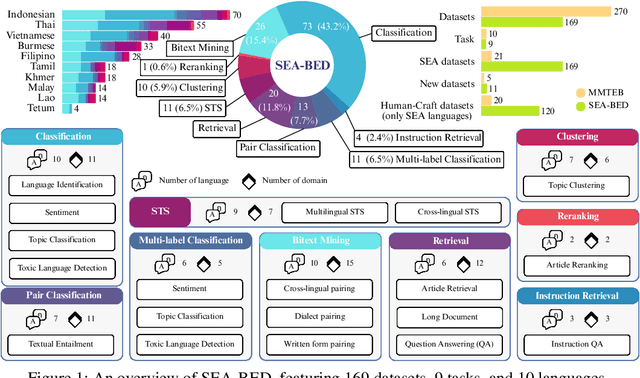


Sentence embeddings are essential for NLP tasks such as semantic search, re-ranking, and textual similarity. Although multilingual benchmarks like MMTEB broaden coverage, Southeast Asia (SEA) datasets are scarce and often machine-translated, missing native linguistic properties. With nearly 700 million speakers, the SEA region lacks a region-specific embedding benchmark. We introduce SEA-BED, the first large-scale SEA embedding benchmark with 169 datasets across 9 tasks and 10 languages, where 71% are formulated by humans, not machine generation or translation. We address three research questions: (1) which SEA languages and tasks are challenging, (2) whether SEA languages show unique performance gaps globally, and (3) how human vs. machine translations affect evaluation. We evaluate 17 embedding models across six studies, analyzing task and language challenges, cross-benchmark comparisons, and translation trade-offs. Results show sharp ranking shifts, inconsistent model performance among SEA languages, and the importance of human-curated datasets for low-resource languages like Burmese.
SEA-LION: Southeast Asian Languages in One Network
Apr 08, 2025Recently, Large Language Models (LLMs) have dominated much of the artificial intelligence scene with their ability to process and generate natural languages. However, the majority of LLM research and development remains English-centric, leaving low-resource languages such as those in the Southeast Asian (SEA) region under-represented. To address this representation gap, we introduce Llama-SEA-LION-v3-8B-IT and Gemma-SEA-LION-v3-9B-IT, two cutting-edge multilingual LLMs designed for SEA languages. The SEA-LION family of LLMs supports 11 SEA languages, namely English, Chinese, Indonesian, Vietnamese, Malay, Thai, Burmese, Lao, Filipino, Tamil, and Khmer. Our work leverages large-scale multilingual continued pre-training with a comprehensive post-training regime involving multiple stages of instruction fine-tuning, alignment, and model merging. Evaluation results on multilingual benchmarks indicate that our models achieve state-of-the-art performance across LLMs supporting SEA languages. We open-source the models to benefit the wider SEA community.
SEA-HELM: Southeast Asian Holistic Evaluation of Language Models
Feb 20, 2025



With the rapid emergence of novel capabilities in Large Language Models (LLMs), the need for rigorous multilingual and multicultural benchmarks that are integrated has become more pronounced. Though existing LLM benchmarks are capable of evaluating specific capabilities of LLMs in English as well as in various mid- to low-resource languages, including those in the Southeast Asian (SEA) region, a comprehensive and authentic evaluation suite for the SEA languages has not been developed thus far. Here, we present SEA-HELM, a holistic linguistic and cultural LLM evaluation suite that emphasizes SEA languages, comprising five core pillars: (1) NLP Classics, (2) LLM-specifics, (3) SEA Linguistics, (4) SEA Culture, (5) Safety. SEA-HELM currently supports Filipino, Indonesian, Tamil, Thai, and Vietnamese. We also introduce the SEA-HELM leaderboard, which allows users to understand models' multilingual and multicultural performance in a systematic and user-friendly manner.
Batayan: A Filipino NLP benchmark for evaluating Large Language Models
Feb 19, 2025



Recent advances in large language models (LLMs) have demonstrated remarkable capabilities on widely benchmarked high-resource languages; however, linguistic nuances of under-resourced languages remain unexplored. We introduce Batayan, a holistic Filipino benchmark designed to systematically evaluate LLMs across three key natural language processing (NLP) competencies: understanding, reasoning, and generation. Batayan consolidates eight tasks, covering both Tagalog and code-switched Taglish utterances. Our rigorous, native-speaker-driven annotation process ensures fluency and authenticity to the complex morphological and syntactic structures of Filipino, alleviating a pervasive translationese bias in existing Filipino corpora. We report empirical results on a variety of multilingual LLMs, highlighting significant performance gaps that signal the under-representation of Filipino in pretraining corpora, the unique hurdles in modeling Filipino's rich morphology and construction, and the importance of explicit Filipino language support and instruction tuning. Moreover, we discuss the practical challenges encountered in dataset construction and propose principled solutions for building culturally and linguistically-faithful resources in under-represented languages. We also provide a public benchmark and leaderboard as a clear foundation for iterative, community-driven progress in Filipino NLP.