 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork Density Analysis of Health Seeking Behavior in Metro Manila: A Retrospective Analysis on COVID-19 Google Trends Data
Mar 27, 2025

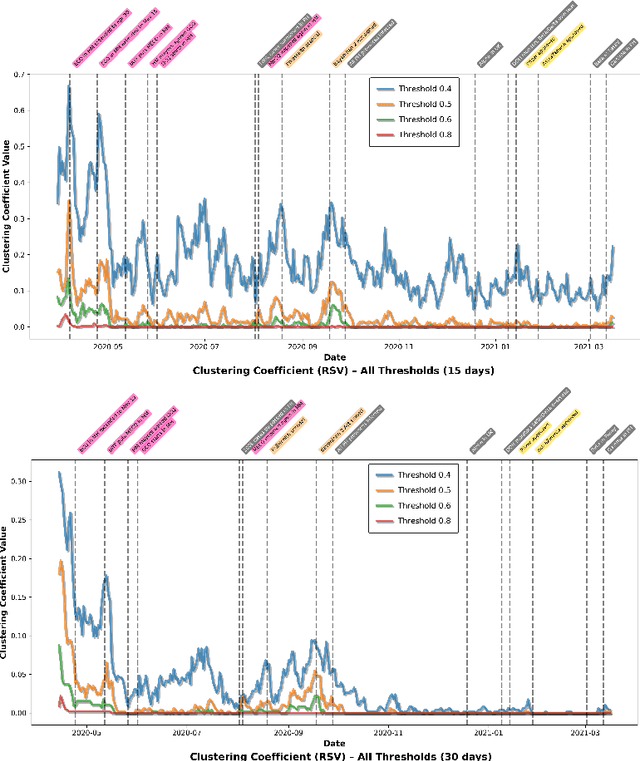
This study examined the temporal aspect of COVID-19-related health-seeking behavior in Metro Manila, National Capital Region, Philippines through a network density analysis of Google Trends data. A total of 15 keywords across five categories (English symptoms, Filipino symptoms, face wearing, quarantine, and new normal) were examined using both 15-day and 30-day rolling windows from March 2020 to March 2021. The methodology involved constructing network graphs using distance correlation coefficients at varying thresholds (0.4, 0.5, 0.6, and 0.8) and analyzing the time-series data of network density and clustering coefficients. Results revealed three key findings: (1) an inverse relationship between the threshold values and network metrics, indicating that higher thresholds provide more meaningful keyword relationships; (2) exceptionally high network connectivity during the initial pandemic months followed by gradual decline; and (3) distinct patterns in keyword relationships, transitioning from policy-focused searches to more symptom-specific queries as the pandemic temporally progressed. The 30-day window analysis showed more stable, but less search activities compared to the 15-day windows, suggesting stronger correlations in immediate search behaviors. These insights are helpful for health communication because it emphasizes the need of a strategic and conscientious information dissemination from the government or the private sector based on the networked search behavior (e.g. prioritizing to inform select symptoms rather than an overview of what the coronavirus is).
Batayan: A Filipino NLP benchmark for evaluating Large Language Models
Feb 19, 2025



Recent advances in large language models (LLMs) have demonstrated remarkable capabilities on widely benchmarked high-resource languages; however, linguistic nuances of under-resourced languages remain unexplored. We introduce Batayan, a holistic Filipino benchmark designed to systematically evaluate LLMs across three key natural language processing (NLP) competencies: understanding, reasoning, and generation. Batayan consolidates eight tasks, covering both Tagalog and code-switched Taglish utterances. Our rigorous, native-speaker-driven annotation process ensures fluency and authenticity to the complex morphological and syntactic structures of Filipino, alleviating a pervasive translationese bias in existing Filipino corpora. We report empirical results on a variety of multilingual LLMs, highlighting significant performance gaps that signal the under-representation of Filipino in pretraining corpora, the unique hurdles in modeling Filipino's rich morphology and construction, and the importance of explicit Filipino language support and instruction tuning. Moreover, we discuss the practical challenges encountered in dataset construction and propose principled solutions for building culturally and linguistically-faithful resources in under-represented languages. We also provide a public benchmark and leaderboard as a clear foundation for iterative, community-driven progress in Filipino NLP.