 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMean Height Aided Post-Processing for Pedestrian Detection
Aug 24, 2024The design of pedestrian detectors seldom considers the unique characteristics of this task and usually follows the common strategies for general object detection. To explore the potential of these characteristics, we take the perspective effect in pedestrian datasets as an example and propose the mean height aided suppression for post-processing. This method rejects predictions that fall at levels with a low possibility of containing any pedestrians or that have an abnormal height compared to the average. To achieve this, the existence score and mean height generators are proposed. Comprehensive experiments on various datasets and detectors are performed; the choice of hyper-parameters is discussed in depth. The proposed method is easy to implement and is plug-and-play. Results show that the proposed methods significantly improve detection accuracy when applied to different existing pedestrian detectors and datasets. The combination of mean height aided suppression with particular detectors outperforms state-of-the-art pedestrian detectors on Caltech and Citypersons datasets.
Adaptive Anchor Label Propagation for Transductive Few-Shot Learning
Oct 30, 2023



Few-shot learning addresses the issue of classifying images using limited labeled data. Exploiting unlabeled data through the use of transductive inference methods such as label propagation has been shown to improve the performance of few-shot learning significantly. Label propagation infers pseudo-labels for unlabeled data by utilizing a constructed graph that exploits the underlying manifold structure of the data. However, a limitation of the existing label propagation approaches is that the positions of all data points are fixed and might be sub-optimal so that the algorithm is not as effective as possible. In this work, we propose a novel algorithm that adapts the feature embeddings of the labeled data by minimizing a differentiable loss function optimizing their positions in the manifold in the process. Our novel algorithm, Adaptive Anchor Label Propagation}, outperforms the standard label propagation algorithm by as much as 7% and 2% in the 1-shot and 5-shot settings respectively. We provide experimental results highlighting the merits of our algorithm on four widely used few-shot benchmark datasets, namely miniImageNet, tieredImageNet, CUB and CIFAR-FS and two commonly used backbones, ResNet12 and WideResNet-28-10. The source code can be found at https://github.com/MichalisLazarou/A2LP.
Multi-Modal Hybrid Learning and Sequential Training for RGB-T Saliency Detection
Sep 13, 2023RGB-T saliency detection has emerged as an important computer vision task, identifying conspicuous objects in challenging scenes such as dark environments. However, existing methods neglect the characteristics of cross-modal features and rely solely on network structures to fuse RGB and thermal features. To address this, we first propose a Multi-Modal Hybrid loss (MMHL) that comprises supervised and self-supervised loss functions. The supervised loss component of MMHL distinctly utilizes semantic features from different modalities, while the self-supervised loss component reduces the distance between RGB and thermal features. We further consider both spatial and channel information during feature fusion and propose the Hybrid Fusion Module to effectively fuse RGB and thermal features. Lastly, instead of jointly training the network with cross-modal features, we implement a sequential training strategy which performs training only on RGB images in the first stage and then learns cross-modal features in the second stage. This training strategy improves saliency detection performance without computational overhead. Results from performance evaluation and ablation studies demonstrate the superior performance achieved by the proposed method compared with the existing state-of-the-art methods.
Towards Automated Polyp Segmentation Using Weakly- and Semi-Supervised Learning and Deformable Transformers
Nov 21, 2022Polyp segmentation is a crucial step towards computer-aided diagnosis of colorectal cancer. However, most of the polyp segmentation methods require pixel-wise annotated datasets. Annotated datasets are tedious and time-consuming to produce, especially for physicians who must dedicate their time to their patients. We tackle this issue by proposing a novel framework that can be trained using only weakly annotated images along with exploiting unlabeled images. To this end, we propose three ideas to address this problem, more specifically our contributions are: 1) a novel sparse foreground loss that suppresses false positives and improves weakly-supervised training, 2) a batch-wise weighted consistency loss utilizing predicted segmentation maps from identical networks trained using different initialization during semi-supervised training, 3) a deformable transformer encoder neck for feature enhancement by fusing information across levels and flexible spatial locations. Extensive experimental results demonstrate the merits of our ideas on five challenging datasets outperforming some state-of-the-art fully supervised models. Also, our framework can be utilized to fine-tune models trained on natural image segmentation datasets drastically improving their performance for polyp segmentation and impressively demonstrating superior performance to fully supervised fine-tuning.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022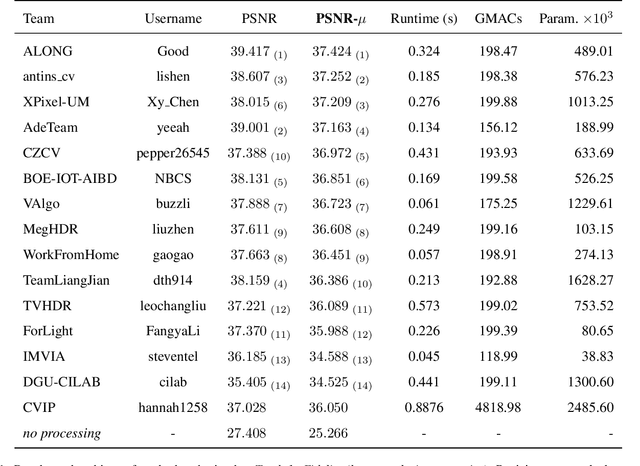
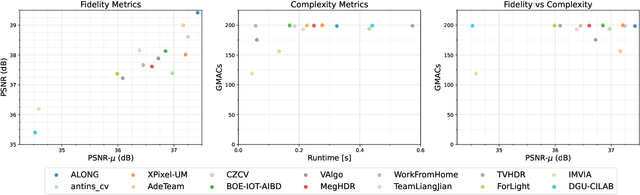
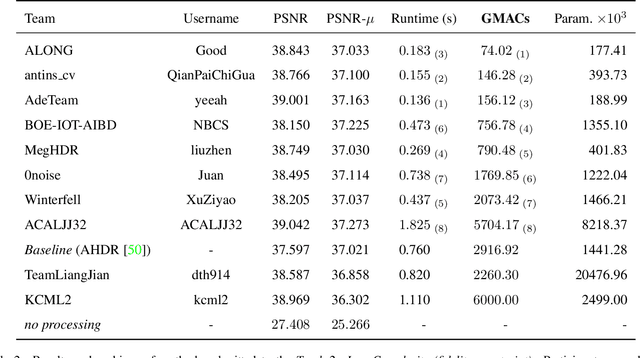
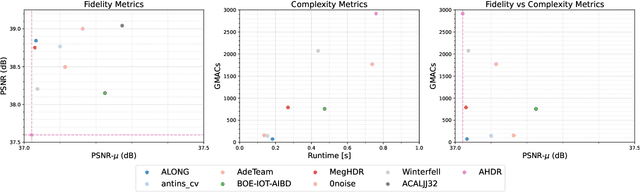
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
Diversity-based Trajectory and Goal Selection with Hindsight Experience Replay
Aug 17, 2021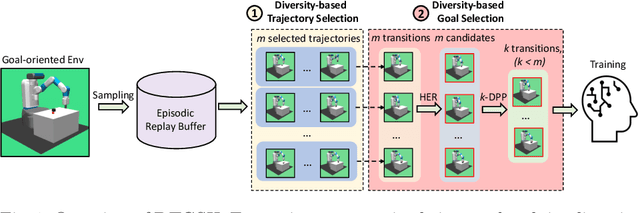
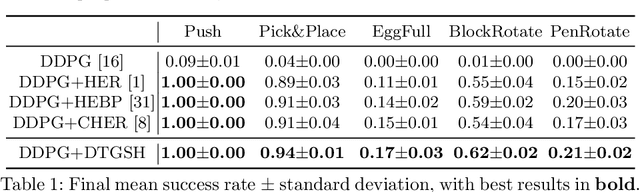
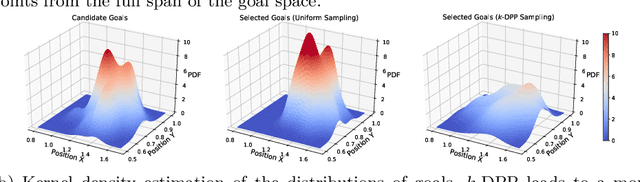

Hindsight experience replay (HER) is a goal relabelling technique typically used with off-policy deep reinforcement learning algorithms to solve goal-oriented tasks; it is well suited to robotic manipulation tasks that deliver only sparse rewards. In HER, both trajectories and transitions are sampled uniformly for training. However, not all of the agent's experiences contribute equally to training, and so naive uniform sampling may lead to inefficient learning. In this paper, we propose diversity-based trajectory and goal selection with HER (DTGSH). Firstly, trajectories are sampled according to the diversity of the goal states as modelled by determinantal point processes (DPPs). Secondly, transitions with diverse goal states are selected from the trajectories by using k-DPPs. We evaluate DTGSH on five challenging robotic manipulation tasks in simulated robot environments, where we show that our method can learn more quickly and reach higher performance than other state-of-the-art approaches on all tasks.
Dynamic Knowledge Distillation with A Single Stream Structure for RGB-D Salient Object Detection
Jun 30, 2021

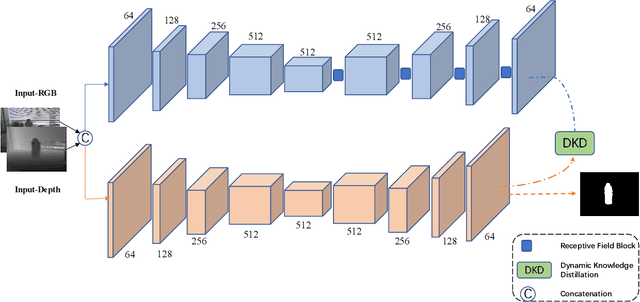

RGB-D salient object detection(SOD) demonstrates its superiority on detecting in complex environments due to the additional depth information introduced in the data. Inevitably, an independent stream is introduced to extract features from depth images, leading to extra computation and parameters. This methodology which sacrifices the model size to improve the detection accuracy may impede the practical application of SOD problems. To tackle this dilemma, we propose a dynamic distillation method along with a lightweight framework, which significantly reduces the parameters. This method considers the factors of both teacher and student performance within the training stage and dynamically assigns the distillation weight instead of applying a fixed weight on the student model. Extensive experiments are conducted on five public datasets to demonstrate that our method can achieve competitive performance compared to 10 prior methods through a 78.2MB lightweight structure.
Progressive Multi-scale Fusion Network for RGB-D Salient Object Detection
Jun 07, 2021
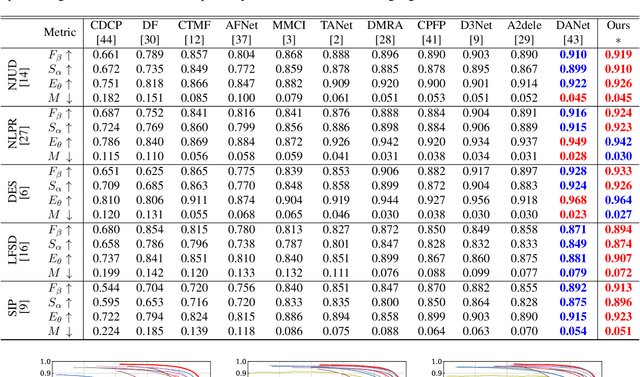
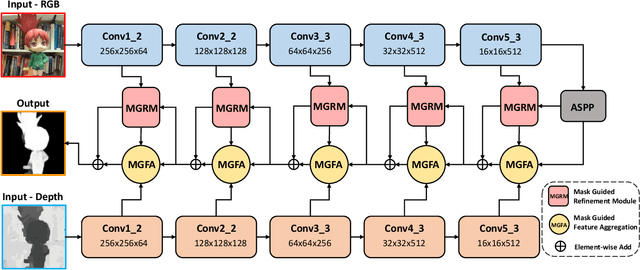
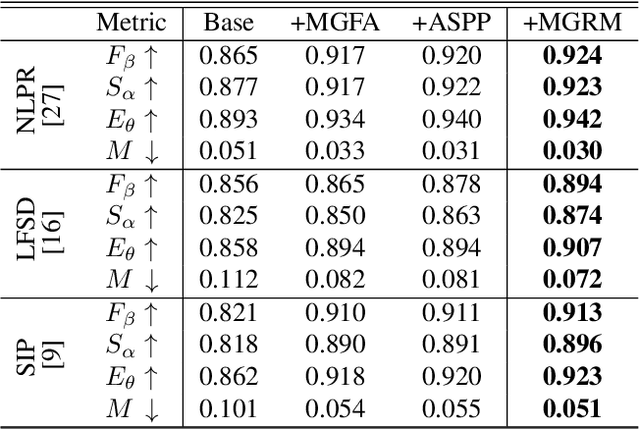
Salient object detection(SOD) aims at locating the most significant object within a given image. In recent years, great progress has been made in applying SOD on many vision tasks. The depth map could provide additional spatial prior and boundary cues to boost the performance. Combining the depth information with image data obtained from standard visual cameras has been widely used in recent SOD works, however, introducing depth information in a suboptimal fusion strategy may have negative influence in the performance of SOD. In this paper, we discuss about the advantages of the so-called progressive multi-scale fusion method and propose a mask-guided feature aggregation module(MGFA). The proposed framework can effectively combine the two features of different modalities and, furthermore, alleviate the impact of erroneous depth features, which are inevitably caused by the variation of depth quality. We further introduce a mask-guided refinement module(MGRM) to complement the high-level semantic features and reduce the irrelevant features from multi-scale fusion, leading to an overall refinement of detection. Experiments on five challenging benchmarks demonstrate that the proposed method outperforms 11 state-of-the-art methods under different evaluation metrics.
Salient Object Detection Combining a Self-attention Module and a Feature Pyramid Network
Apr 30, 2020


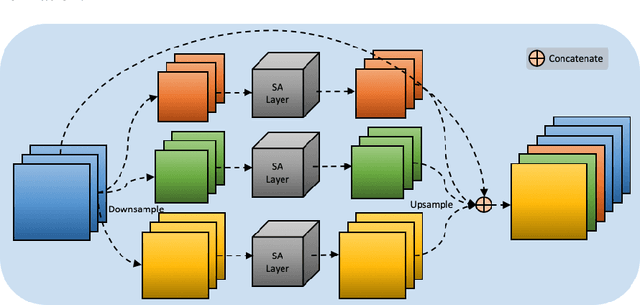
Salient object detection has achieved great improvement by using the Fully Convolution Network (FCN). However, the FCN-based U-shape architecture may cause the dilution problem in the high-level semantic information during the up-sample operations in the top-down pathway. Thus, it can weaken the ability of salient object localization and produce degraded boundaries. To this end, in order to overcome this limitation, we propose a novel pyramid self-attention module (PSAM) and the adoption of an independent feature-complementing strategy. In PSAM, self-attention layers are equipped after multi-scale pyramid features to capture richer high-level features and bring larger receptive fields to the model. In addition, a channel-wise attention module is also employed to reduce the redundant features of the FPN and provide refined results. Experimental analysis shows that the proposed PSAM effectively contributes to the whole model so that it outperforms state-of-the-art results over five challenging datasets. Finally, quantitative results show that PSAM generates clear and integral salient maps which can provide further help to other computer vision tasks, such as object detection and semantic segmentation.
Gated Multi-layer Convolutional Feature Extraction Network for Robust Pedestrian Detection
Oct 25, 2019

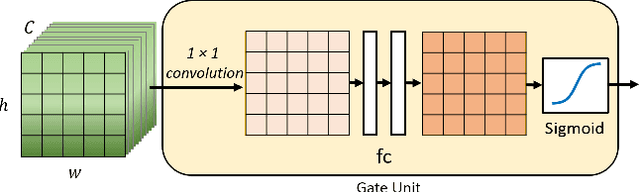
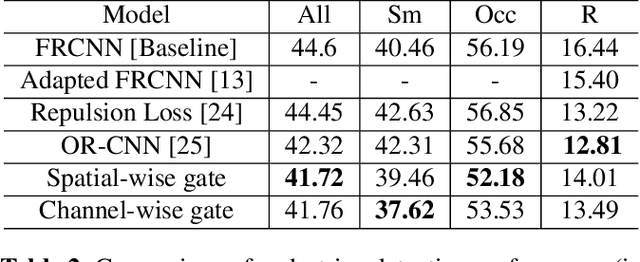
Pedestrian detection methods have been significantly improved with the development of deep convolutional neural networks. Nevertheless, robustly detecting pedestrians with a large variant on sizes and with occlusions remains a challenging problem. In this paper, we propose a gated multi-layer convolutional feature extraction method which can adaptively generate discriminative features for candidate pedestrian regions. The proposed gated feature extraction framework consists of squeeze units, gate units and a concatenation layer which perform feature dimension squeezing, feature elements manipulation and convolutional features combination from multiple CNN layers, respectively. We proposed two different gate models which can manipulate the regional feature maps in a channel-wise selection manner and a spatial-wise selection manner, respectively. Experiments on the challenging CityPersons dataset demonstrate the effectiveness of the proposed method, especially on detecting those small-size and occluded pedestrians.