 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Robust Multidimensional Attention in Remote Physiological Sensing through Target Signal Constrained Factorization
May 11, 2025Remote physiological sensing using camera-based technologies offers transformative potential for non-invasive vital sign monitoring across healthcare and human-computer interaction domains. Although deep learning approaches have advanced the extraction of physiological signals from video data, existing methods have not been sufficiently assessed for their robustness to domain shifts. These shifts in remote physiological sensing include variations in ambient conditions, camera specifications, head movements, facial poses, and physiological states which often impact real-world performance significantly. Cross-dataset evaluation provides an objective measure to assess generalization capabilities across these domain shifts. We introduce Target Signal Constrained Factorization module (TSFM), a novel multidimensional attention mechanism that explicitly incorporates physiological signal characteristics as factorization constraints, allowing more precise feature extraction. Building on this innovation, we present MMRPhys, an efficient dual-branch 3D-CNN architecture designed for simultaneous multitask estimation of photoplethysmography (rPPG) and respiratory (rRSP) signals from multimodal RGB and thermal video inputs. Through comprehensive cross-dataset evaluation on five benchmark datasets, we demonstrate that MMRPhys with TSFM significantly outperforms state-of-the-art methods in generalization across domain shifts for rPPG and rRSP estimation, while maintaining a minimal inference latency suitable for real-time applications. Our approach establishes new benchmarks for robust multitask and multimodal physiological sensing and offers a computationally efficient framework for practical deployment in unconstrained environments. The web browser-based application featuring on-device real-time inference of MMRPhys model is available at https://physiologicailab.github.io/mmrphys-live
FactorizePhys: Matrix Factorization for Multidimensional Attention in Remote Physiological Sensing
Nov 03, 2024
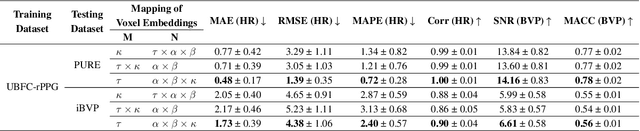
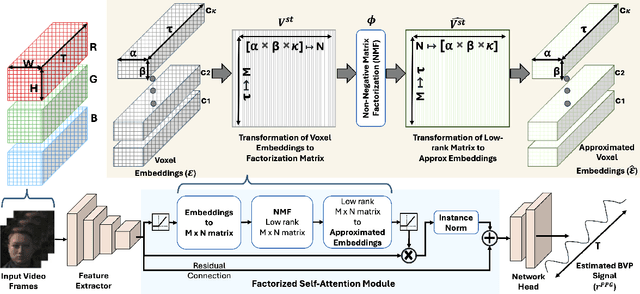
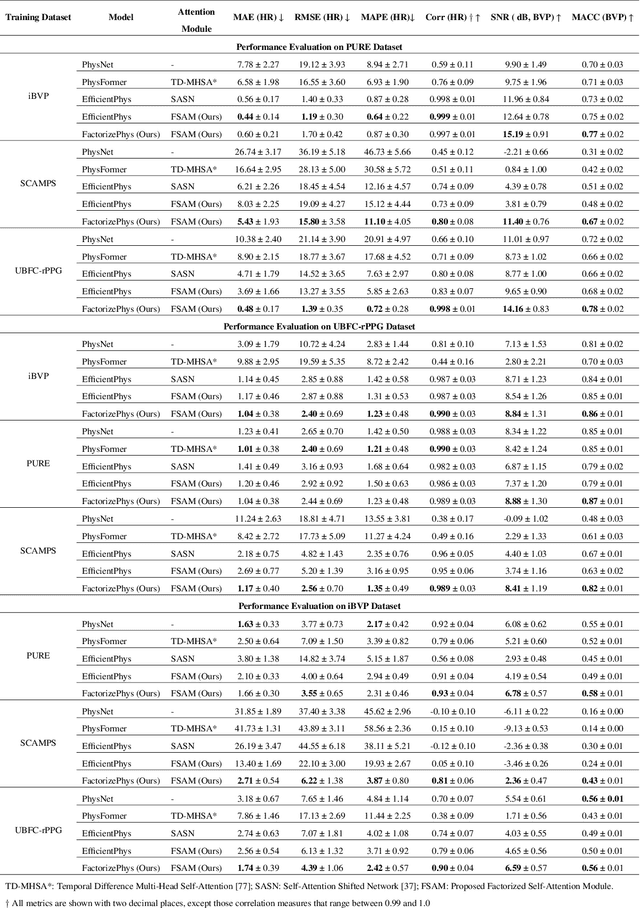
Remote photoplethysmography (rPPG) enables non-invasive extraction of blood volume pulse signals through imaging, transforming spatial-temporal data into time series signals. Advances in end-to-end rPPG approaches have focused on this transformation where attention mechanisms are crucial for feature extraction. However, existing methods compute attention disjointly across spatial, temporal, and channel dimensions. Here, we propose the Factorized Self-Attention Module (FSAM), which jointly computes multidimensional attention from voxel embeddings using nonnegative matrix factorization. To demonstrate FSAM's effectiveness, we developed FactorizePhys, an end-to-end 3D-CNN architecture for estimating blood volume pulse signals from raw video frames. Our approach adeptly factorizes voxel embeddings to achieve comprehensive spatial, temporal, and channel attention, enhancing performance of generic signal extraction tasks. Furthermore, we deploy FSAM within an existing 2D-CNN-based rPPG architecture to illustrate its versatility. FSAM and FactorizePhys are thoroughly evaluated against state-of-the-art rPPG methods, each representing different types of architecture and attention mechanism. We perform ablation studies to investigate the architectural decisions and hyperparameters of FSAM. Experiments on four publicly available datasets and intuitive visualization of learned spatial-temporal features substantiate the effectiveness of FSAM and enhanced cross-dataset generalization in estimating rPPG signals, suggesting its broader potential as a multidimensional attention mechanism. The code is accessible at https://github.com/PhysiologicAILab/FactorizePhys.
Multi-Modal Hybrid Learning and Sequential Training for RGB-T Saliency Detection
Sep 13, 2023RGB-T saliency detection has emerged as an important computer vision task, identifying conspicuous objects in challenging scenes such as dark environments. However, existing methods neglect the characteristics of cross-modal features and rely solely on network structures to fuse RGB and thermal features. To address this, we first propose a Multi-Modal Hybrid loss (MMHL) that comprises supervised and self-supervised loss functions. The supervised loss component of MMHL distinctly utilizes semantic features from different modalities, while the self-supervised loss component reduces the distance between RGB and thermal features. We further consider both spatial and channel information during feature fusion and propose the Hybrid Fusion Module to effectively fuse RGB and thermal features. Lastly, instead of jointly training the network with cross-modal features, we implement a sequential training strategy which performs training only on RGB images in the first stage and then learns cross-modal features in the second stage. This training strategy improves saliency detection performance without computational overhead. Results from performance evaluation and ablation studies demonstrate the superior performance achieved by the proposed method compared with the existing state-of-the-art methods.
Self-adversarial Multi-scale Contrastive Learning for Semantic Segmentation of Thermal Facial Images
Oct 07, 2022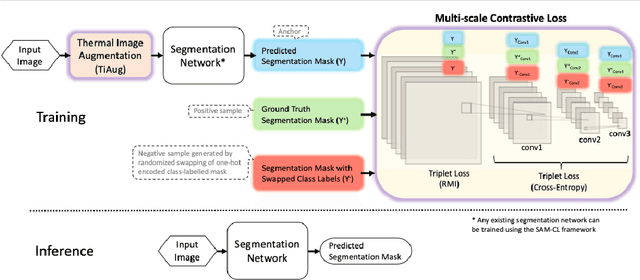
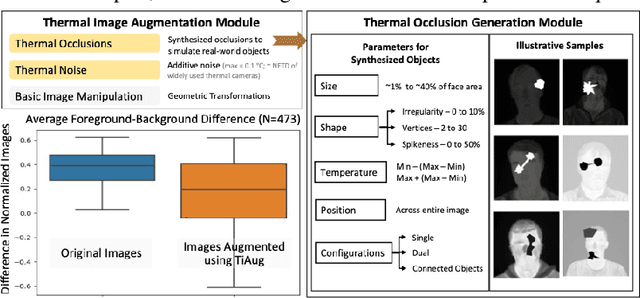
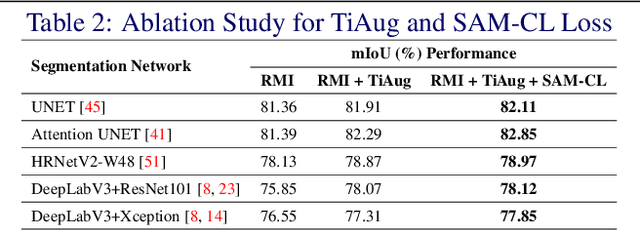
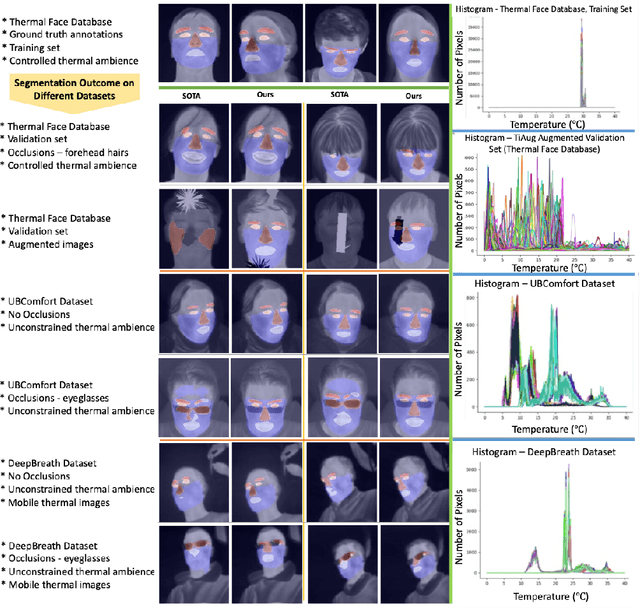
Segmentation of thermal facial images is a challenging task. This is because facial features often lack salience due to high-dynamic thermal range scenes and occlusion issues. Limited availability of datasets from unconstrained settings further limits the use of the state-of-the-art segmentation networks, loss functions and learning strategies which have been built and validated for RGB images. To address the challenge, we propose Self-Adversarial Multi-scale Contrastive Learning (SAM-CL) framework as a new training strategy for thermal image segmentation. SAM-CL framework consists of a SAM-CL loss function and a thermal image augmentation (TiAug) module as a domain-specific augmentation technique. We use the Thermal-Face-Database to demonstrate effectiveness of our approach. Experiments conducted on the existing segmentation networks (UNET, Attention-UNET, DeepLabV3 and HRNetv2) evidence the consistent performance gains from the SAM-CL framework. Furthermore, we present a qualitative analysis with UBComfort and DeepBreath datasets to discuss how our proposed methods perform in handling unconstrained situations.