 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Masks Needed: Explainable AI for Deriving Segmentation from Classification
Aug 06, 2025Medical image segmentation is vital for modern healthcare and is a key element of computer-aided diagnosis. While recent advancements in computer vision have explored unsupervised segmentation using pre-trained models, these methods have not been translated well to the medical imaging domain. In this work, we introduce a novel approach that fine-tunes pre-trained models specifically for medical images, achieving accurate segmentation with extensive processing. Our method integrates Explainable AI to generate relevance scores, enhancing the segmentation process. Unlike traditional methods that excel in standard benchmarks but falter in medical applications, our approach achieves improved results on datasets like CBIS-DDSM, NuInsSeg and Kvasir-SEG.
Image compositing is all you need for data augmentation
Feb 19, 2025This paper investigates the impact of various data augmentation techniques on the performance of object detection models. Specifically, we explore classical augmentation methods, image compositing, and advanced generative models such as Stable Diffusion XL and ControlNet. The objective of this work is to enhance model robustness and improve detection accuracy, particularly when working with limited annotated data. Using YOLOv8, we fine-tune the model on a custom dataset consisting of commercial and military aircraft, applying different augmentation strategies. Our experiments show that image compositing offers the highest improvement in detection performance, as measured by precision, recall, and mean Average Precision (mAP@0.50). Other methods, including Stable Diffusion XL and ControlNet, also demonstrate significant gains, highlighting the potential of advanced data augmentation techniques for object detection tasks. The results underline the importance of dataset diversity and augmentation in achieving better generalization and performance in real-world applications. Future work will explore the integration of semi-supervised learning methods and further optimizations to enhance model performance across larger and more complex datasets.
Image edge enhancement for effective image classification
Jan 13, 2024Image classification has been a popular task due to its feasibility in real-world applications. Training neural networks by feeding them RGB images has demonstrated success over it. Nevertheless, improving the classification accuracy and computational efficiency of this process continues to present challenges that researchers are actively addressing. A widely popular embraced method to improve the classification performance of neural networks is to incorporate data augmentations during the training process. Data augmentations are simple transformations that create slightly modified versions of the training data and can be very effective in training neural networks to mitigate overfitting and improve their accuracy performance. In this study, we draw inspiration from high-boost image filtering and propose an edge enhancement-based method as means to enhance both accuracy and training speed of neural networks. Specifically, our approach involves extracting high frequency features, such as edges, from images within the available dataset and fusing them with the original images, to generate new, enriched images. Our comprehensive experiments, conducted on two distinct datasets CIFAR10 and CALTECH101, and three different network architectures ResNet-18, LeNet-5 and CNN-9 demonstrates the effectiveness of our proposed method.
Adaptive Anchor Label Propagation for Transductive Few-Shot Learning
Oct 30, 2023



Few-shot learning addresses the issue of classifying images using limited labeled data. Exploiting unlabeled data through the use of transductive inference methods such as label propagation has been shown to improve the performance of few-shot learning significantly. Label propagation infers pseudo-labels for unlabeled data by utilizing a constructed graph that exploits the underlying manifold structure of the data. However, a limitation of the existing label propagation approaches is that the positions of all data points are fixed and might be sub-optimal so that the algorithm is not as effective as possible. In this work, we propose a novel algorithm that adapts the feature embeddings of the labeled data by minimizing a differentiable loss function optimizing their positions in the manifold in the process. Our novel algorithm, Adaptive Anchor Label Propagation}, outperforms the standard label propagation algorithm by as much as 7% and 2% in the 1-shot and 5-shot settings respectively. We provide experimental results highlighting the merits of our algorithm on four widely used few-shot benchmark datasets, namely miniImageNet, tieredImageNet, CUB and CIFAR-FS and two commonly used backbones, ResNet12 and WideResNet-28-10. The source code can be found at https://github.com/MichalisLazarou/A2LP.
Adaptive manifold for imbalanced transductive few-shot learning
Apr 27, 2023Transductive few-shot learning algorithms have showed substantially superior performance over their inductive counterparts by leveraging the unlabeled queries. However, the vast majority of such methods are evaluated on perfectly class-balanced benchmarks. It has been shown that they undergo remarkable drop in performance under a more realistic, imbalanced setting. To this end, we propose a novel algorithm to address imbalanced transductive few-shot learning, named Adaptive Manifold. Our method exploits the underlying manifold of the labeled support examples and unlabeled queries by using manifold similarity to predict the class probability distribution per query. It is parameterized by one centroid per class as well as a set of graph-specific parameters that determine the manifold. All parameters are optimized through a loss function that can be tuned towards class-balanced or imbalanced distributions. The manifold similarity shows substantial improvement over Euclidean distance, especially in the 1-shot setting. Our algorithm outperforms or is on par with other state of the art methods in three benchmark datasets, namely miniImageNet, tieredImageNet and CUB, and three different backbones, namely ResNet-18, WideResNet-28-10 and DenseNet-121. In certain cases, our algorithm outperforms the previous state of the art by as much as 4.2%.
Towards Automated Polyp Segmentation Using Weakly- and Semi-Supervised Learning and Deformable Transformers
Nov 21, 2022Polyp segmentation is a crucial step towards computer-aided diagnosis of colorectal cancer. However, most of the polyp segmentation methods require pixel-wise annotated datasets. Annotated datasets are tedious and time-consuming to produce, especially for physicians who must dedicate their time to their patients. We tackle this issue by proposing a novel framework that can be trained using only weakly annotated images along with exploiting unlabeled images. To this end, we propose three ideas to address this problem, more specifically our contributions are: 1) a novel sparse foreground loss that suppresses false positives and improves weakly-supervised training, 2) a batch-wise weighted consistency loss utilizing predicted segmentation maps from identical networks trained using different initialization during semi-supervised training, 3) a deformable transformer encoder neck for feature enhancement by fusing information across levels and flexible spatial locations. Extensive experimental results demonstrate the merits of our ideas on five challenging datasets outperforming some state-of-the-art fully supervised models. Also, our framework can be utilized to fine-tune models trained on natural image segmentation datasets drastically improving their performance for polyp segmentation and impressively demonstrating superior performance to fully supervised fine-tuning.
Tensor feature hallucination for few-shot learning
Jun 09, 2021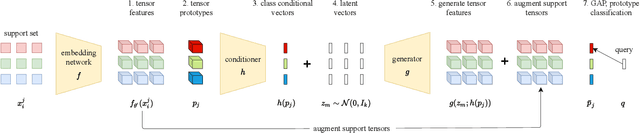
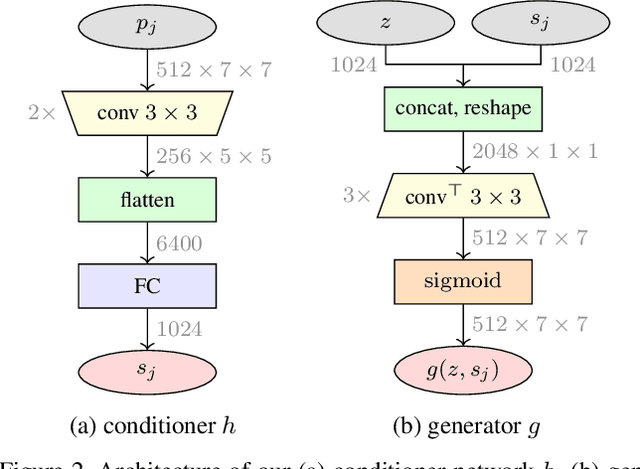
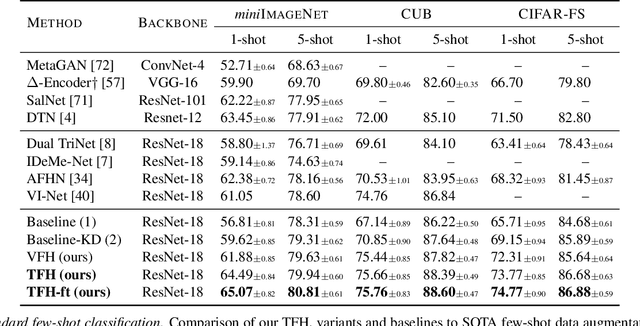
Few-shot classification addresses the challenge of classifying examples given not just limited supervision but limited data as well. An attractive solution is synthetic data generation. However, most such methods are overly sophisticated, focusing on high-quality, realistic data in the input space. It is unclear whether adapting them to the few-shot regime and using them for the downstream task of classification is the right approach. Previous works on synthetic data generation for few-shot classification focus on exploiting complex models, e.g. a Wasserstein GAN with multiple regularizers or a network that transfers latent diversities from known to novel classes. We follow a different approach and investigate how a simple and straightforward synthetic data generation method can be used effectively. We make two contributions, namely we show that: (1) using a simple loss function is more than enough for training a feature generator in the few-shot setting; and (2) learning to generate tensor features instead of vector features is superior. Extensive experiments on miniImagenet, CUB and CIFAR-FS datasets show that our method sets a new state of the art, outperforming more sophisticated few-shot data augmentation methods.
Few-shot learning via tensor hallucination
Apr 19, 2021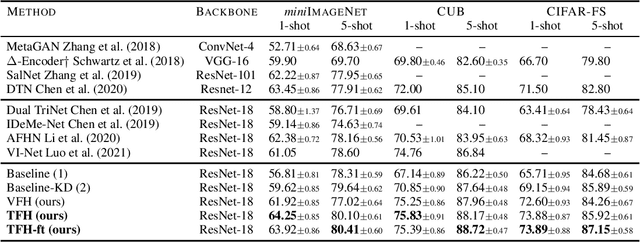
Few-shot classification addresses the challenge of classifying examples given only limited labeled data. A powerful approach is to go beyond data augmentation, towards data synthesis. However, most of data augmentation/synthesis methods for few-shot classification are overly complex and sophisticated, e.g. training a wGAN with multiple regularizers or training a network to transfer latent diversities from known to novel classes. We make two contributions, namely we show that: (1) using a simple loss function is more than enough for training a feature generator in the few-shot setting; and (2) learning to generate tensor features instead of vector features is superior. Extensive experiments on miniImagenet, CUB and CIFAR-FS datasets show that our method sets a new state of the art, outperforming more sophisticated few-shot data augmentation methods.
A novel shape matching descriptor for real-time hand gesture recognition
Jan 11, 2021


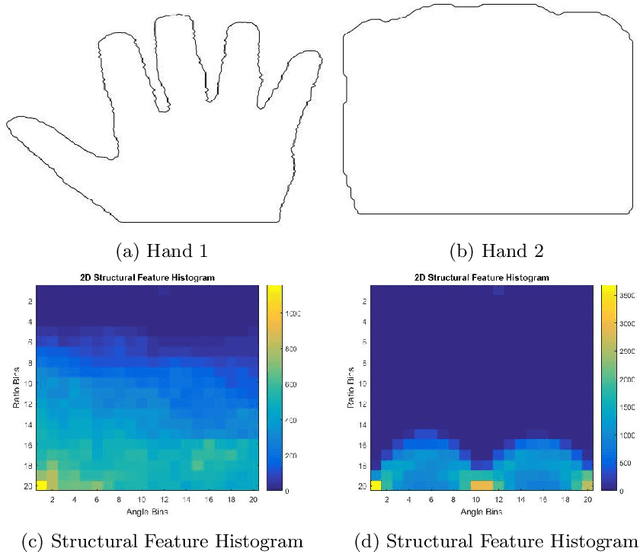
The current state-of-the-art hand gesture recognition methodologies heavily rely in the use of machine learning. However there are scenarios that machine learning cannot be applied successfully, for example in situations where data is scarce. This is the case when one-to-one matching is required between a query and a database of hand gestures where each gesture represents a unique class. In situations where learning algorithms cannot be trained, classic computer vision techniques such as feature extraction can be used to identify similarities between objects. Shape is one of the most important features that can be extracted from images, however the most accurate shape matching algorithms tend to be computationally inefficient for real-time applications. In this work we present a novel shape matching methodology for real-time hand gesture recognition. Extensive experiments were carried out comparing our method with other shape matching methods with respect to accuracy and computational complexity using our own collected hand gesture database as well as the MPEG-7 database that is widely used for comparing 2D shape matching algorithms. Our method outperforms the other methods and provides the optimal combination of accuracy and computational efficiency for real-time applications.
Iterative label cleaning for transductive and semi-supervised few-shot learning
Dec 14, 2020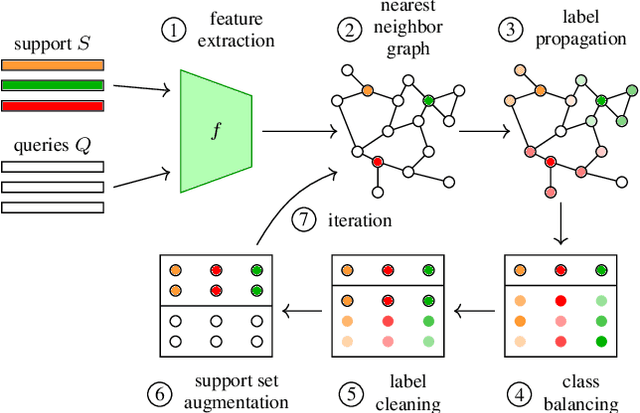
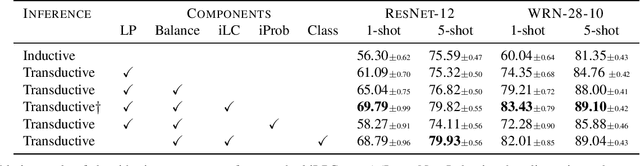
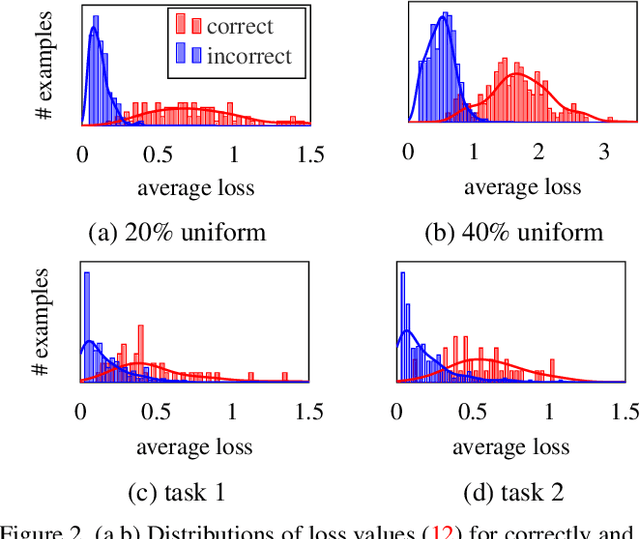
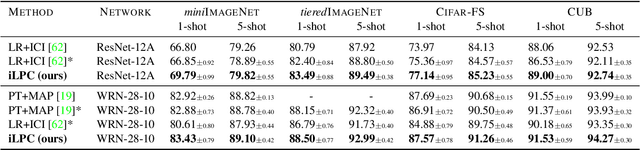
Few-shot learning amounts to learning representations and acquiring knowledge such that novel tasks may be solved with both supervision and data being limited. Improved performance is possible by transductive inference, where the entire test set is available concurrently, and semi-supervised learning, where more unlabeled data is available. These problems are closely related because there is little or no adaptation of the representation in novel tasks. Focusing on these two settings, we introduce a new algorithm that leverages the manifold structure of the labeled and unlabeled data distribution to predict pseudo-labels, while balancing over classes and using the loss value distribution of a limited-capacity classifier to select the cleanest labels, iterately improving the quality of pseudo-labels. Our solution sets new state of the art on four benchmark datasets, namely \emph{mini}ImageNet, \emph{tiered}ImageNet, CUB and CIFAR-FS, while being robust over feature space pre-processing and the quantity of available data.