 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative label cleaning for transductive and semi-supervised few-shot learning
Paper and Code
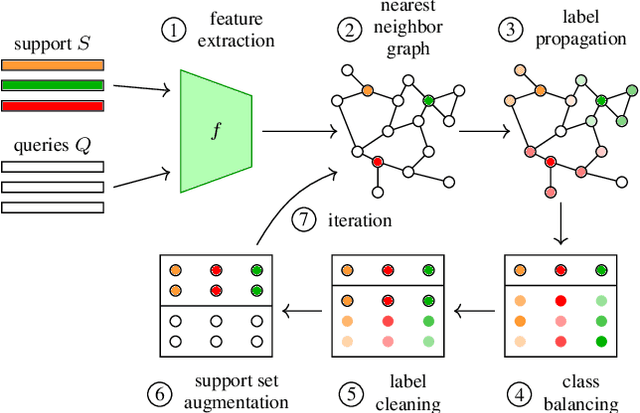
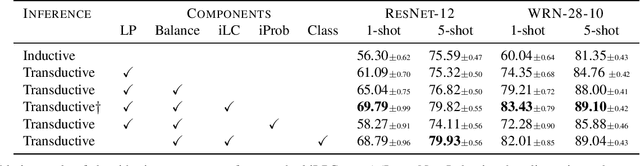
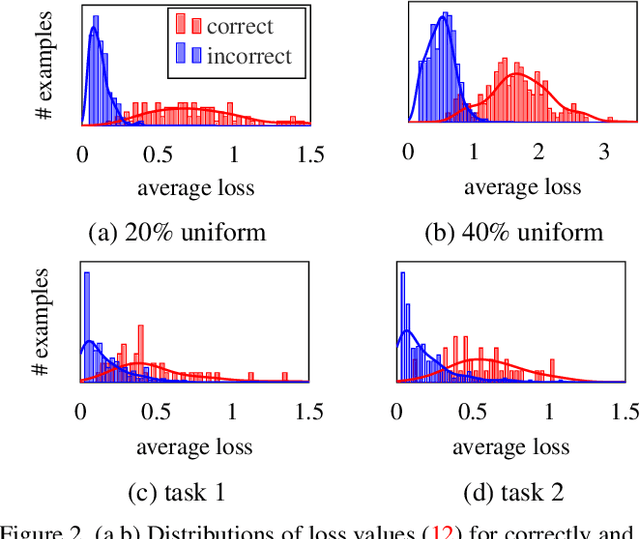
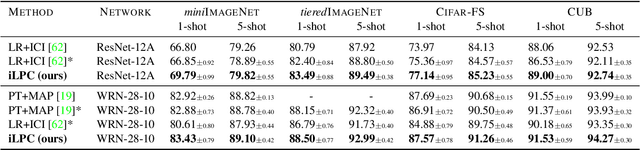
Few-shot learning amounts to learning representations and acquiring knowledge such that novel tasks may be solved with both supervision and data being limited. Improved performance is possible by transductive inference, where the entire test set is available concurrently, and semi-supervised learning, where more unlabeled data is available. These problems are closely related because there is little or no adaptation of the representation in novel tasks. Focusing on these two settings, we introduce a new algorithm that leverages the manifold structure of the labeled and unlabeled data distribution to predict pseudo-labels, while balancing over classes and using the loss value distribution of a limited-capacity classifier to select the cleanest labels, iterately improving the quality of pseudo-labels. Our solution sets new state of the art on four benchmark datasets, namely \emph{mini}ImageNet, \emph{tiered}ImageNet, CUB and CIFAR-FS, while being robust over feature space pre-processing and the quantity of available data.