 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot learning via tensor hallucination
Paper and Code
Apr 19, 2021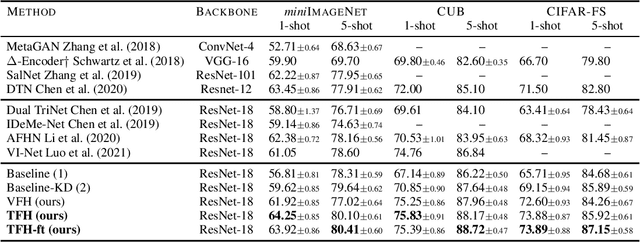
Few-shot classification addresses the challenge of classifying examples given only limited labeled data. A powerful approach is to go beyond data augmentation, towards data synthesis. However, most of data augmentation/synthesis methods for few-shot classification are overly complex and sophisticated, e.g. training a wGAN with multiple regularizers or training a network to transfer latent diversities from known to novel classes. We make two contributions, namely we show that: (1) using a simple loss function is more than enough for training a feature generator in the few-shot setting; and (2) learning to generate tensor features instead of vector features is superior. Extensive experiments on miniImagenet, CUB and CIFAR-FS datasets show that our method sets a new state of the art, outperforming more sophisticated few-shot data augmentation methods.