 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgT challenge: Benchmark of Soft-Tissue Trackers for Robotic Surgery
Feb 28, 2023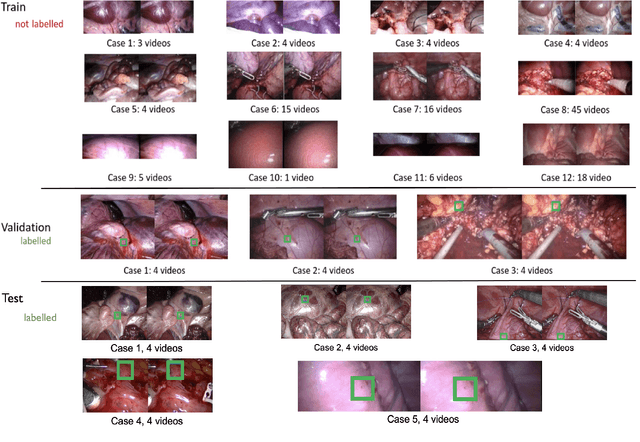
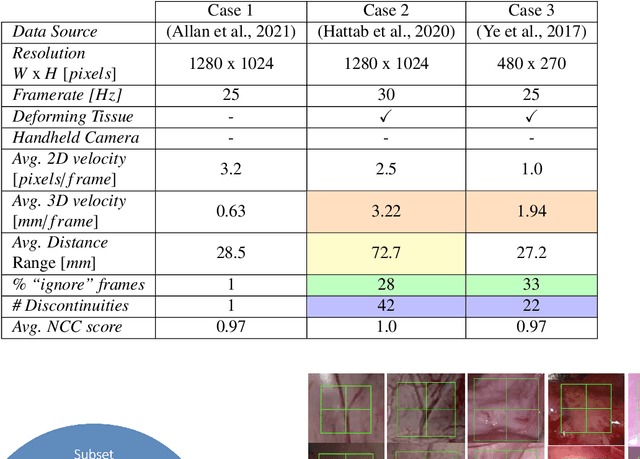
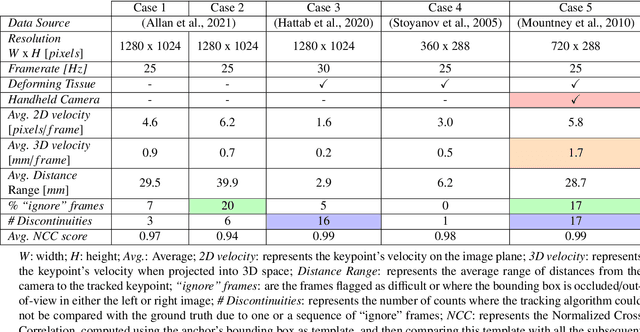
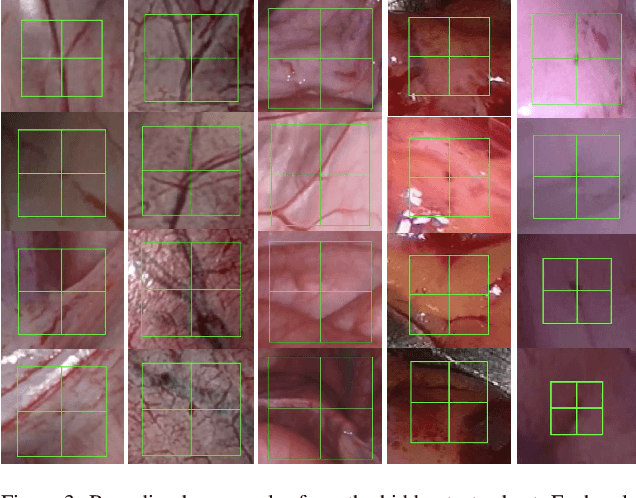
This paper introduces the "SurgT: Surgical Tracking" challenge which was organised in conjunction with the 25th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2022). There were two purposes for the creation of this challenge: (1) the establishment of the first standardised benchmark for the research community to assess soft-tissue trackers; and (2) to encourage the development of unsupervised deep learning methods, given the lack of annotated data in surgery. A dataset of 157 stereo endoscopic videos from 20 clinical cases, along with stereo camera calibration parameters, have been provided. The participants were tasked with the development of algorithms to track a bounding box on stereo endoscopic videos. At the end of the challenge, the developed methods were assessed on a previously hidden test subset. This assessment uses benchmarking metrics that were purposely developed for this challenge and are now available online. The teams were ranked according to their Expected Average Overlap (EAO) score, which is a weighted average of the Intersection over Union (IoU) scores. The performance evaluation study verifies the efficacy of unsupervised deep learning algorithms in tracking soft-tissue. The best-performing method achieved an EAO score of 0.583 in the test subset. The dataset and benchmarking tool created for this challenge have been made publicly available. This challenge is expected to contribute to the development of autonomous robotic surgery and other digital surgical technologies.
Improving Visual Representation Learning through Perceptual Understanding
Dec 30, 2022



We present an extension to masked autoencoders (MAE) which improves on the representations learnt by the model by explicitly encouraging the learning of higher scene-level features. We do this by: (i) the introduction of a perceptual similarity term between generated and real images (ii) incorporating several techniques from the adversarial training literature including multi-scale training and adaptive discriminator augmentation. The combination of these results in not only better pixel reconstruction but also representations which appear to capture better higher-level details within images. More consequentially, we show how our method, Perceptual MAE, leads to better performance when used for downstream tasks outperforming previous methods. We achieve 78.1% top-1 accuracy linear probing on ImageNet-1K and up to 88.1% when fine-tuning, with similar results for other downstream tasks, all without use of additional pre-trained models or data.
Analysing Deep Reinforcement Learning Agents Trained with Domain Randomisation
Dec 18, 2019


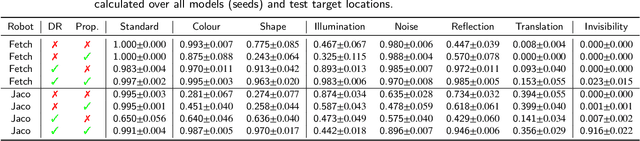
Deep reinforcement learning has the potential to train robots to perform complex tasks in the real world without requiring accurate models of the robot or its environment. A practical approach is to train agents in simulation, and then transfer them to the real world. One of the most popular methods for achieving this is to use domain randomisation, which involves randomly perturbing various aspects of a simulated environment in order to make trained agents robust to the reality gap between the simulator and the real world. However, less work has gone into understanding such agents-which are deployed in the real world-beyond task performance. In this work we examine such agents, through qualitative and quantitative comparisons between agents trained with and without visual domain randomisation, in order to provide a better understanding of how they function. In this work, we train agents for Fetch and Jaco robots on a visuomotor control task, and evaluate how well they generalise using different unit tests. We tie this with interpretability techniques, providing both quantitative and qualitative data. Finally, we investigate the internals of the trained agents by examining their weights and activations. Our results show that the primary outcome of domain randomisation is more redundant, entangled representations, accompanied with significant statistical/structural changes in the weights; moreover, the types of changes are heavily influenced by the task setup and presence of additional proprioceptive inputs. Furthermore, even with an improved saliency method introduced in this work, we show that qualitative studies may not always correspond with quantitative measures, necessitating the use of a wide suite of inspection tools in order to provide sufficient insights into the behaviour of trained agents.